Rhymes AI präsentiert Aria: Das erste Open-Source-Multimodal-Modell mit Mixture-of-Experts
Aria kombiniert Text, Bild, Video und Code für maximale Effizienz und übertrifft kommerzielle Modelle.

Rhymes AI | All-AI.de
Worum geht es?
Das japanische Start-up Rhymes AI hat mit der Veröffentlichung von Aria, einem Open-Source-Modell, einen bedeutenden Schritt in der KI-Entwicklung gemacht. Aria ist laut dem Unternehmen das weltweit erste quelloffene, multimodale Mixture-of-Experts-(MoE)-Modell, das die Leistungsfähigkeit kommerzieller Modelle übertreffen soll. Die Besonderheit von Aria liegt in der Kombination verschiedener Eingabemodalitäten wie Text, Bild, Video und Code, wobei es bei vergleichbarer Kapazität mit spezialisierten Modellen mithalten oder sie sogar übertreffen kann.
News
Technische Architektur von Aria
Aria basiert auf einer Mixture-of-Experts-Architektur (MoE), einer speziellen Struktur, die die Feed-Forward-Schichten eines klassischen Transformer-Modells durch mehrere spezialisierte Experten ersetzt. Für jeden Input-Token wählt ein Router-Modul eine Teilmenge der Experten aus, was zu einer Reduzierung der aktiven Parameter pro Token führt. Dies steigert die Recheneffizienz, da nicht alle Parameter gleichzeitig aktiviert werden müssen. Zu den bekanntesten Vertretern dieser Architektur zählen Modelle wie Mixtral 8x7B und DeepSeek-V2, und auch OpenAIs GPT-4 basiert wahrscheinlich auf einer ähnlichen Struktur.
Aria aktiviert bei Textinputs 3,5 Milliarden Parameter pro Token und verfügt insgesamt über 24,9 Milliarden Parameter. Ein leichtgewichtiger visueller Encoder mit 438 Millionen Parametern verarbeitet visuelle Eingaben wie Bilder oder Videos. Das multimodale Kontextfenster von Aria umfasst beeindruckende 64.000 Token, was es zu einem der leistungsstärksten Open-Source-Modelle seiner Art macht.
Trainingsprozess
Der Trainingsprozess von Aria erfolgte in vier Phasen:
1. Phase 1: Vortraining ausschließlich mit Textdaten.
2. Phase 2: Training mit einer Mischung aus Text- und multimodalen Daten.
3. Phase 3: Training mit langen Sequenzen, um den Umgang mit ausgedehnten Kontexten zu optimieren.
4. Phase 4: Feinabstimmung (Finetuning), um das Modell für spezifische Aufgaben anzupassen.
Insgesamt wurde Aria mit 6,4 Billionen Text-Token und 400 Milliarden multimodalen Token trainiert. Die Daten stammen aus öffentlichen Quellen wie Common Crawl und LAION und wurden teilweise synthetisch angereichert, um die Vielfalt und Qualität der Trainingsdaten zu erhöhen.
Vergleich mit anderen Modellen
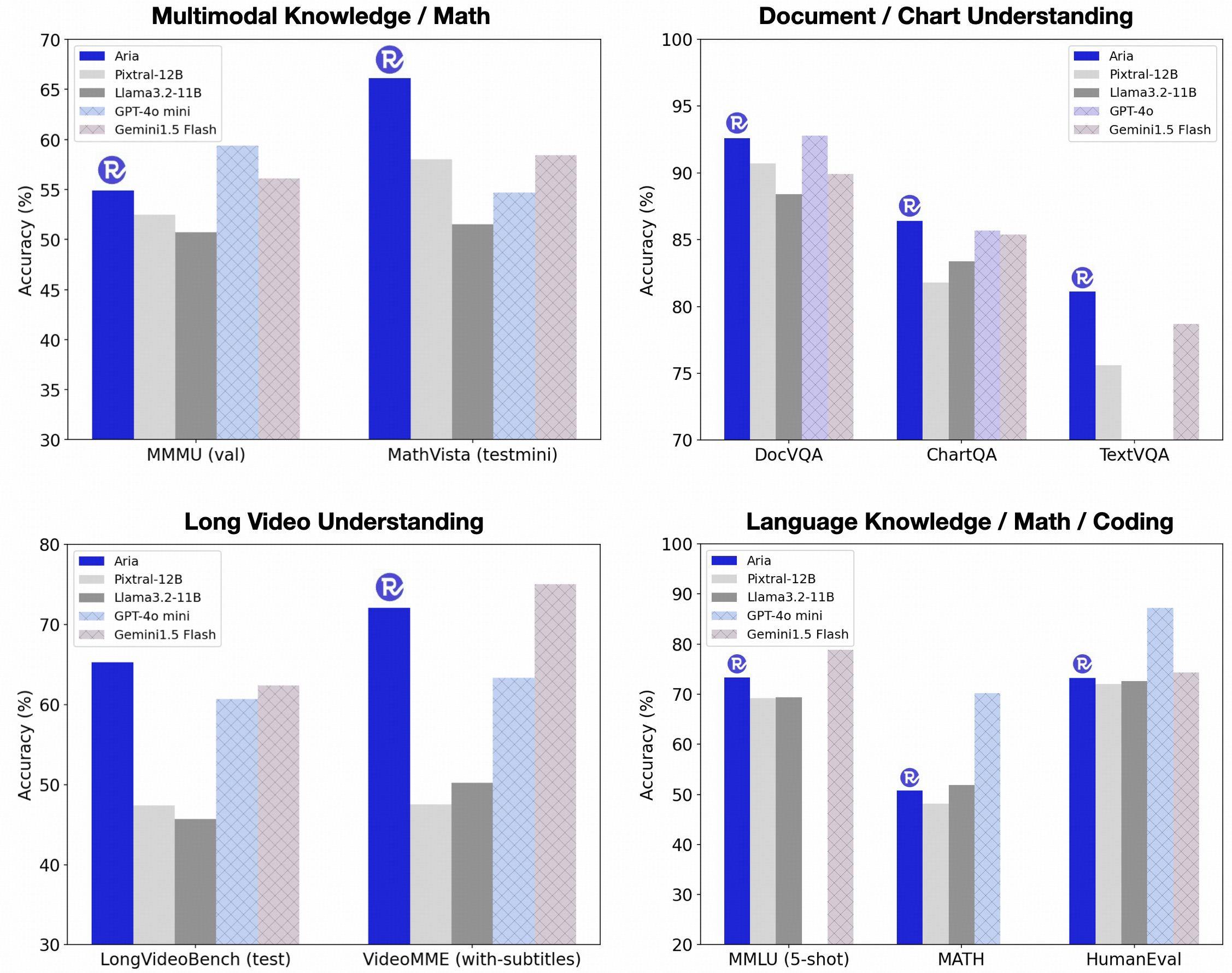
In internen Benchmarks zeigt Aria beeindruckende Leistungen im Vergleich zu anderen Open-Source-Modellen wie Pixtral-12B und Llama-3.2-11B, aber auch zu proprietären Modellen wie GPT-4o und Gemini-1.5. Aria ist in der Lage, bei einer Vielzahl von Aufgaben, die multimodale Inputs, Sprachverarbeitung oder Programmierung betreffen, gleiche oder bessere Ergebnisse zu liefern – und das bei geringeren Inferenzkosten. Diese Effizienz resultiert aus der reduzierten Anzahl aktivierter Parameter pro Token, was die Hardwareanforderungen senkt.
Besonders hervorgehoben wird die Fähigkeit von Aria, mit langen multimodalen Eingaben wie Videos mit Untertiteln oder mehrseitigen Dokumenten umzugehen. Laut Rhymes AI übertrifft Aria hier sogar GPT-4o mini bei der Verarbeitung von langen Videos und Gemini 1.5 Flash bei langen Dokumenten. Diese Fähigkeiten machen Aria zu einem äußerst flexiblen Modell für eine breite Palette von Anwendungen, von der Videobearbeitung bis hin zur Dokumentenverarbeitung.
Open-Source und Kooperation mit AMD
Rhymes AI hat den Quellcode von Aria unter der Apache-2.0-Lizenz auf GitHub veröffentlicht, was sowohl die akademische als auch kommerzielle Nutzung ermöglicht. Zusätzlich wurde ein Trainingsframework bereitgestellt, das es ermöglicht, Aria auf einer Vielzahl von Datenquellen und -formaten mit nur einer einzigen GPU zu trainieren. Diese Offenheit und Flexibilität macht Aria besonders attraktiv für Entwickler, die ihre eigenen multimodalen Modelle verfeinern oder anpassen möchten.
Um die Leistung von Aria weiter zu verbessern, hat Rhymes AI eine Partnerschaft mit dem Chiphersteller AMD geschlossen. Gemeinsam arbeiten sie daran, die Modelle auf AMDs leistungsstarken Hardwarelösungen zu optimieren. Auf der Konferenz "Advancing AI 2024" präsentierte Rhymes AI seine für Konsumenten entwickelte Suchanwendung BeaGo, die auf AMDs MI300X-Beschleunigern läuft. BeaGo soll umfangreiche KI-Suchergebnisse für Text und Bilder liefern und wird bereits als kostenlose App für iOS und Android angeboten.
BeaGo: Eine neue Suchanwendung
BeaGo, die auf Aria basiert, ist eine Suchanwendung, die den Anspruch hat, intelligente Suchergebnisse zu liefern. In einem Vergleichsvideo positioniert Rhymes AI BeaGo als eine Alternative zu Perplexity und Gemini. Die App unterstützt derzeit Text- und englischsprachige Eingaben und liefert KI-generierte Zusammenfassungen von aktuellen Nachrichten, wobei sie auf verschiedene Online-Artikel verweist.
Ausblick
Rhymes AI hat mit der Veröffentlichung von Aria ein starkes Open-Source-Modell auf den Markt gebracht, das durch seine multimodalen Fähigkeiten und die Mixture-of-Experts-Architektur überzeugt. Aria stellt in vielen Bereichen eine effiziente Alternative zu proprietären Modellen dar und bietet eine hohe Recheneffizienz bei reduzierten Inferenzkosten. Mit der Unterstützung von AMD und der Bereitstellung eines flexiblen Trainingsframeworks ist Aria eine vielversprechende Option für Entwickler und Forscher, die auf der Suche nach leistungsstarken, multimodalen Modellen sind.

Short
- Rhymes AI hat mit Aria das weltweit erste Open-Source-Multimodal-Modell mit Mixture-of-Experts-Technologie veröffentlicht.
- Aria kombiniert Text, Bild, Video und Code und erreicht eine vergleichbare oder bessere Leistung als kommerzielle Modelle wie GPT-4o oder Gemini 1.5.
- Das Modell zeichnet sich durch eine hohe Recheneffizienz aus, indem nur eine Teilmenge der Parameter pro Token aktiviert wird.
- Aria wurde unter der Apache-2.0-Lizenz veröffentlicht, um eine flexible Nutzung und Anpassung durch Entwickler zu ermöglichen.