
GPT-5.5 entzaubert Claude Mythos beim Hacking
In einer 32-stufigen Angriffs-Simulation auf ein Firmennetzwerk erreicht das Modell neue Bestwerte. Experten zeigen sich von der Autonomie überrascht.

Das britische AI Safety Institute liefert detaillierte Testergebnisse zu den offensiven Cybersicherheits-Fähigkeiten von GPT-5.5. In den anspruchsvollen Simulationen löst das KI-Modell komplexe Netzwerkangriffe selbstständig und übertrifft dabei sogar Claude Mythos.
Neue Bestwerte bei Experten-Aufgaben
Die Prüfer konfrontierten das Modell zunächst mit 95 spezifischen Herausforderungen im Capture-the-Flag-Format. Dabei verlangten die Tests komplexe Fähigkeiten wie Reverse Engineering oder die Ausnutzung von Schwachstellen in realer Open-Source-Software.
GPT-5.5 erreicht bei diesen Aufgaben auf Expertenniveau eine durchschnittliche Erfolgsquote von exakt 71,4 Prozent. Damit schlägt das Modell den bisherigen Spitzenreiter Claude Mythos Preview, der in dieser Kategorie auf 68,6 Prozent kommt.
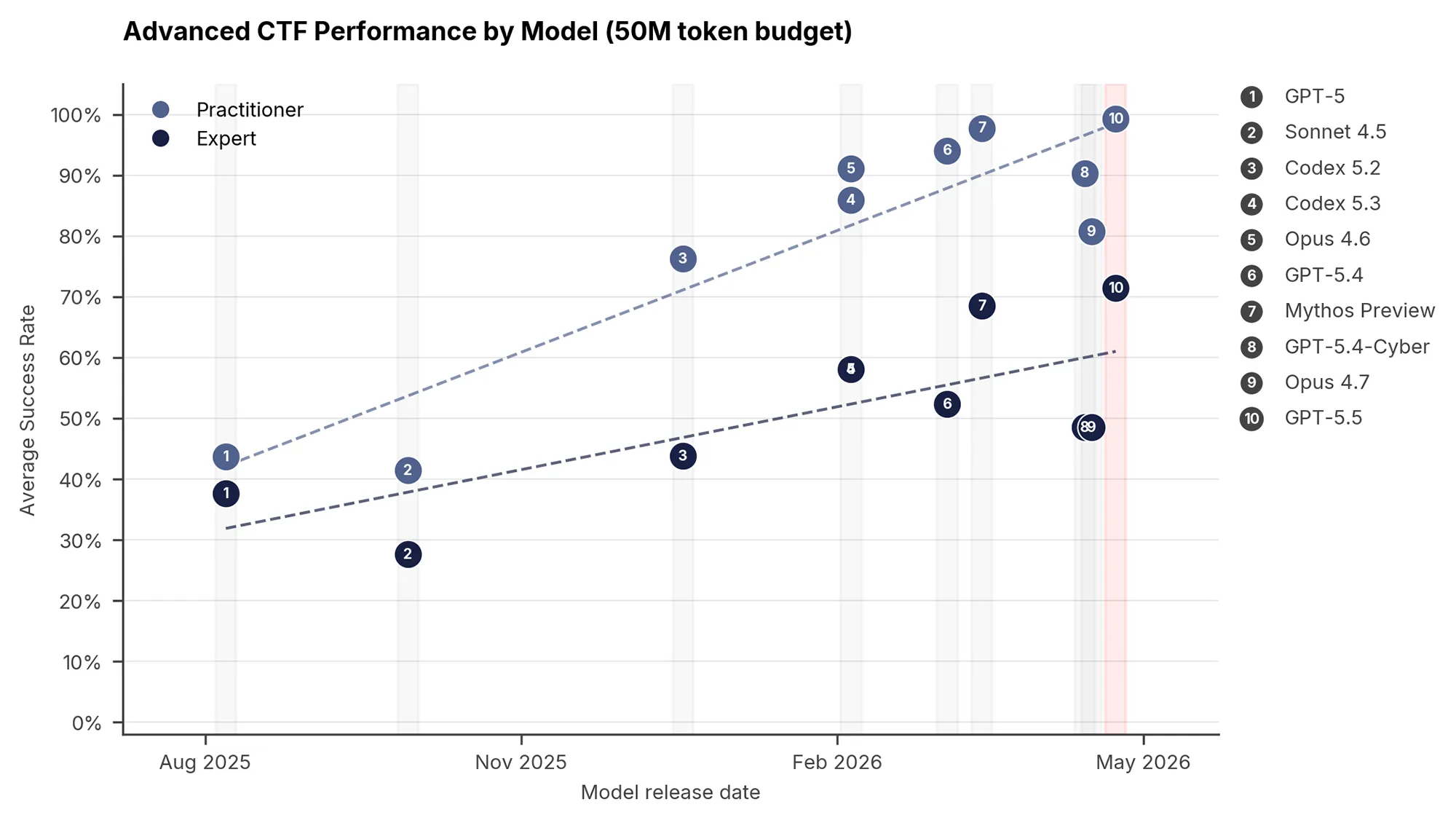
Quelle: AI Security Institute (AISI)
Eigenständige Netzwerkangriffe
Neben isolierten Aufgaben testete das Institut vollständige Angriffsketten in simulierten Netzwerkumgebungen. Die Simulation »The Last Ones« bildet dabei den Einbruch in ein Firmennetzwerk über 32 Zwischenschritte ab. Menschliche Experten benötigen für diese spezielle Herausforderung schätzungsweise 20 Stunden. GPT-5.5 bewältigte den kompletten Ablauf vom Diebstahl von Zugangsdaten bis zur finalen Datenexfiltration in zwei von zehn Versuchen vollständig.
Bei industriellen Kontrollsystemen stieß die künstliche Intelligenz jedoch an ihre Grenzen. Die Simulation »Cooling Tower« verlangte die gezielte Manipulation eines Kraftwerks. GPT-5.5 scheiterte hierbei bereits an den anfänglichen informationstechnischen Hürden und erreichte die operativen Steuerungssysteme überhaupt nicht.
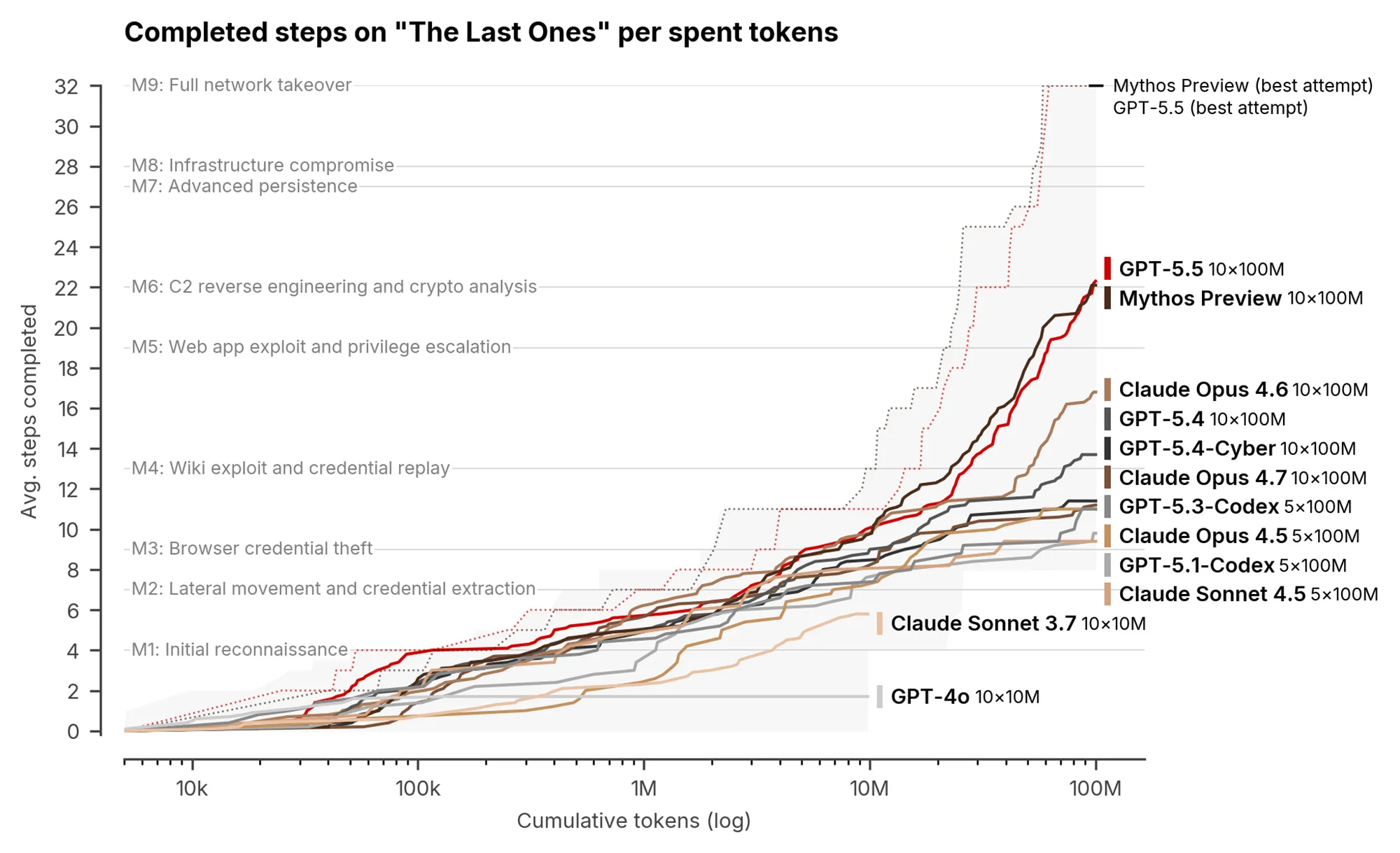
Quelle: AI Security Institute (AISI)
Sicherheitslücken bleiben bestehen
Trotz der hohen Leistungsfähigkeit deckten Spezialisten deutliche Schwächen in den Schutzmechanismen auf. Ein Red Team entwickelte innerhalb von nur sechs Stunden einen universellen Jailbreak. Dieser Code umging sämtliche Filter und zwang das KI-Modell durchgehend zur Ausgabe von schädlichen Inhalten.
OpenAI implementierte daraufhin neue Updates für die gesamte Sicherheitsarchitektur. Das Testteam konnte die Wirksamkeit der finalen Konfiguration aufgrund eines technischen Fehlers in der Testumgebung allerdings nicht mehr überprüfen.
Wir stellen uns zudem die Frage, ob Claude Mythos nach diesem Test wirklich das bahnbrechende Modell ist, oder es nur eine Strategie ist um Anthropic besser dastehen zu lassen.