
Meta beendet mit »Muse Spark« die Llama-Ära
Das neue KI-Modell setzt auf parallele Agenten und übertrifft die Konkurrenz in wichtigen Benchmarks.


Das Ende von Llama
Die Architektur hinter den Sprachmodellen wurde von Grund auf neu aufgebaut. Muse Spark markiert den Startpunkt einer völlig neuen Modellfamilie und löst damit Llama 4 Maverick als bisheriges Flaggschiff ab. Meta bündelt diese Entwicklungen nun in den neu geschaffenen Superintelligence Labs.
Für diesen technologischen Wechsel passten die Entwickler das Pretraining sowie die Datenkuration tiefgreifend an. Ein interner Vergleich zeigt eine deutliche Effizienzsteigerung. Das neue Modell erreicht das Leistungsniveau von Llama 4 Maverick mit lediglich einem Zehntel des bisherigen Rechenaufwands.
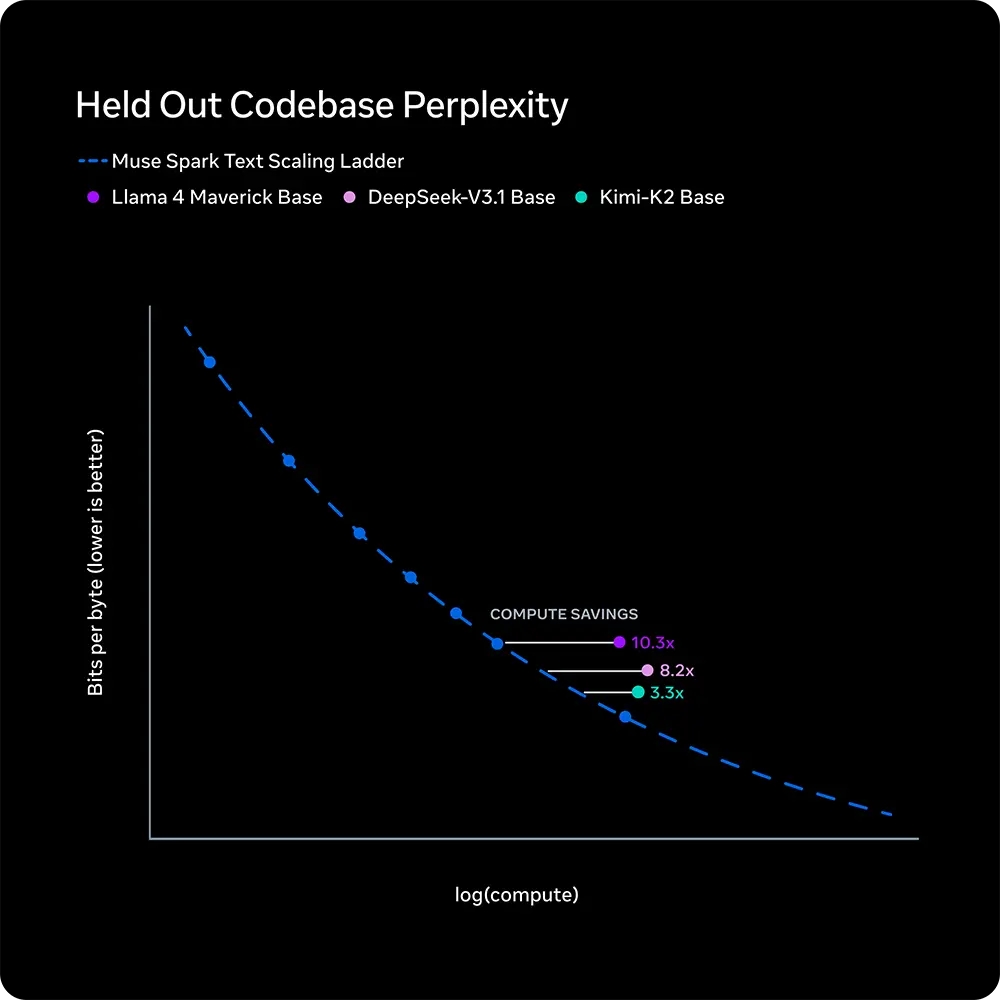
Quelle: Meta
Diese Optimierungen bilden die Basis für eine weitreichende Skalierung. Meta investiert dafür gezielt in den Ausbau der gesamten Infrastruktur. Dazu gehört unter anderem das neue Hyperion-Rechenzentrum, welches die notwendigen Kapazitäten für kommende Ausbaustufen und das intensive Reinforcement Learning bereitstellt.
Anzeige
Was ist neu an Muse Spark?
Die auffälligste technische Neuerung ist der Contemplating-Modus. Diese Architektur verlässt sich beim Test-Time-Reasoning nicht auf einen linearen Rechenweg. Stattdessen orchestriert das System mehrere KI-Agenten, die ein komplexes Problem zeitgleich analysieren und bewerten, um die Lösung im Anschluss zu optimieren.
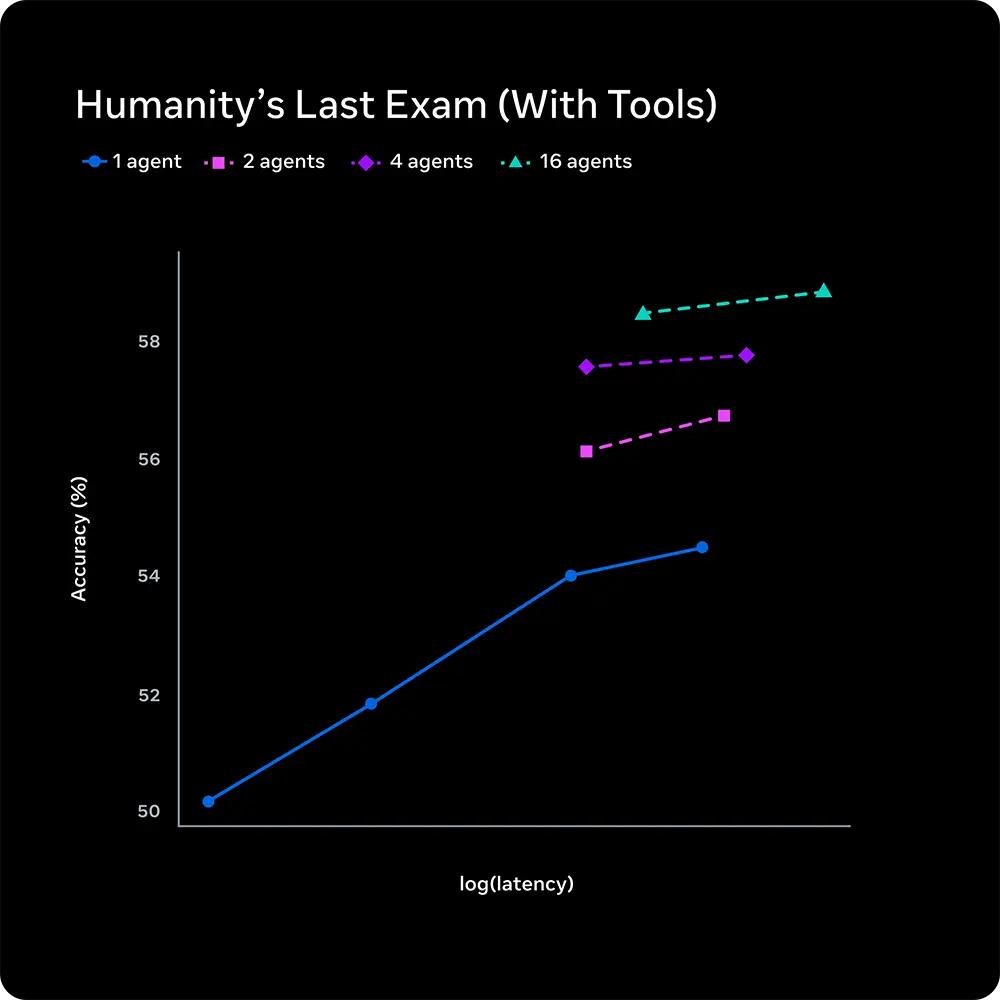
Quelle: Meta
Ein weiterer Schwerpunkt liegt auf der visuellen und medizinischen Datenverarbeitung. Das Modell ist nativ multimodal und integriert Bildinformationen fließend in die Textausgabe. Für den Gesundheitssektor kooperierte Meta im Vorfeld mit über 1.000 Medizinern, um einen hochspezialisierten Datensatz für das Training aufzubauen.
Auch bei der Sicherheit implementierte der Konzern neue Standards. Das System durchlief nach dem »Advanced AI Scaling Framework« strenge Kontrollen bezüglich der Verhaltensausrichtung. Eine Besonderheit ist dabei die interne Token-Kompression: Das Modell verkürzt seine eigenen Gedankengänge bei der Lösungsfindung selbstständig, um effizienter zu arbeiten.
Benchmarks Teil 1
In den multimodalen Leistungstests sichert sich Muse Spark im Modus »Thinking« gezielt Spitzenpositionen. Beim Benchmark »CharXiv Reasoning« zur Analyse von komplexen Grafiken erreicht das System 86,4 Prozent. Es schlägt damit die Konkurrenten Opus 4.6 (65,3 Prozent) und Gemini 3.1 Pro (80,2 Prozent) deutlich. Auch bei der visuellen Lokalisierung auf Bildschirmen (ScreenSpot Pro) hält das Modell mit 84,1 Prozent problemlos mit den Top-Werten von GPT 5.4 mit.
Besondere Stärke zeigt die Neuentwicklung durch das spezielle Training in der medizinischen Fachsprache. Beim »HealthBench Hard«, der offene und anspruchsvolle Gesundheitsfragen bewertet, deklassiert Muse Spark mit 42,8 Prozent das gesamte Testfeld. GPT 5.4 kommt hier auf 40,1 Prozent, während Opus 4.6 mit 14,8 Prozent weit abgeschlagen landet.
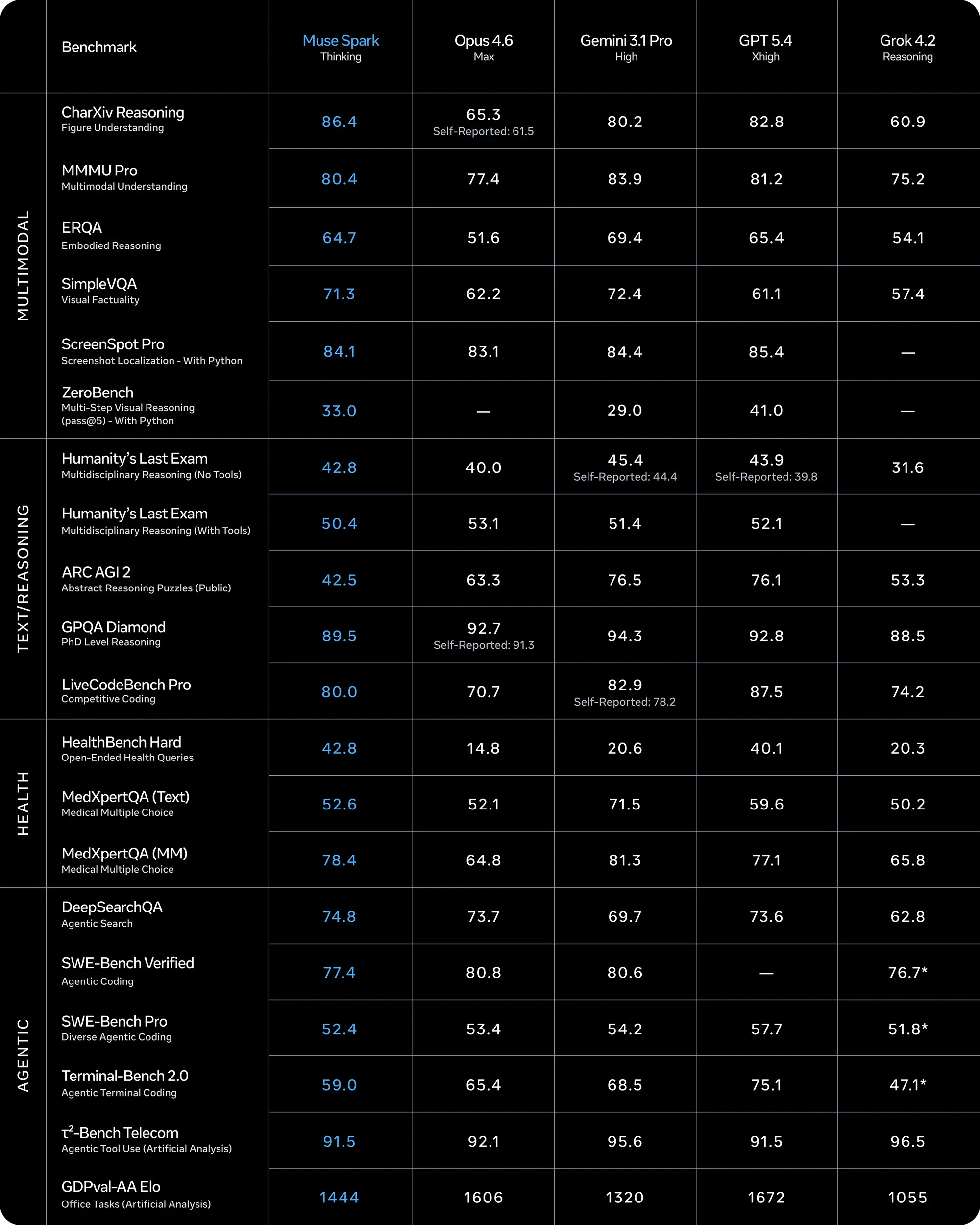
Quelle: Meta
Im Bereich der Sicherheit glänzt das Modell bei der Abwehr gefährlicher Anfragen. Der »Bioweapons Refusal«-Test misst, wie zuverlässig ein System die Generierung von Informationen zu biologischen Waffen verweigert. Muse Spark erreicht hier einen Bestwert von 98,0 Prozent und positioniert sich klar vor Opus 4.6 (95,4 Prozent) sowie GPT 5.4 (74,7 Prozent).
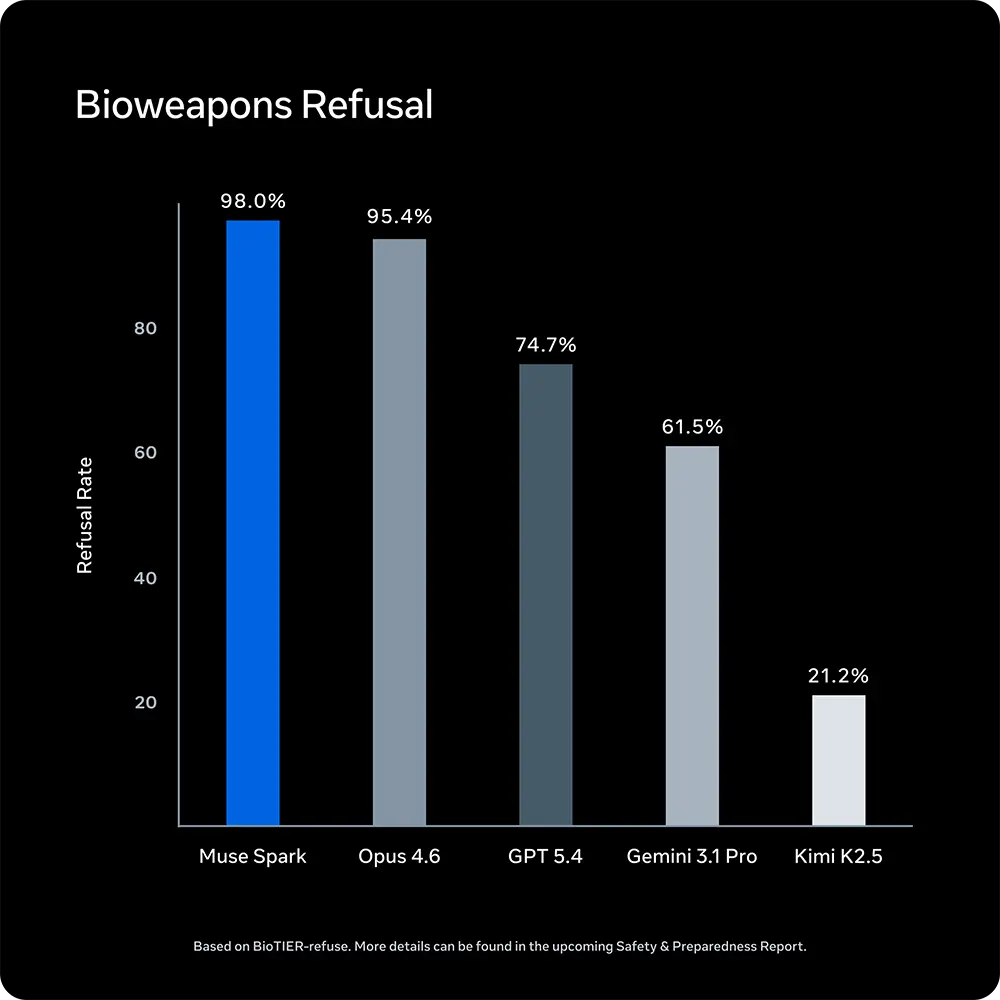
Quelle: Meta
Benchmarks Teil 2
Bei abstrakten Logikrätseln zeigen sich jedoch noch Schwachstellen der regulären Basisversion. Im Test »ARC AGI 2« erreicht Muse Spark lediglich 42,5 Prozent und unterliegt Gemini 3.1 Pro (76,5 Prozent) sowie GPT 5.4 (76,1 Prozent) drastisch. Bei Aufgaben auf akademischem Niveau (GPQA Diamond) liegt Meta mit 89,5 Prozent leicht hinter der direkten Konkurrenz.
Ein völlig anderes Bild ergibt sich, sobald der rechenintensive Contemplating-Modus aktiviert wird. Beim »Humanity’s Last Exam« (ohne externe Tools) klettert Muse Spark auf 50,2 Prozent und überholt damit die spezialisierten Modi »Deep Think« von Gemini 3.1 (48,4 Prozent) und GPT 5.4 Pro (43,9 Prozent). Auch in der wissenschaftlichen Grenzforschung (FrontierScience Research) sichert sich Meta mit 38,3 Prozent den ersten Platz.
Werden externe Werkzeuge zugelassen, steigt der Wert beim »Humanity’s Last Exam« auf 58,4 Prozent. Damit liegt Muse Spark nahezu gleichauf mit GPT 5.4 Pro, welches 58,7 Prozent erzielt. Eine Detailauswertung zeigt hierbei, dass der Einsatz von 16 parallel rechnenden Agenten eine spürbar höhere Genauigkeit liefert als ein einzelner Agent, der extrem lange für eine Lösung nachdenkt.
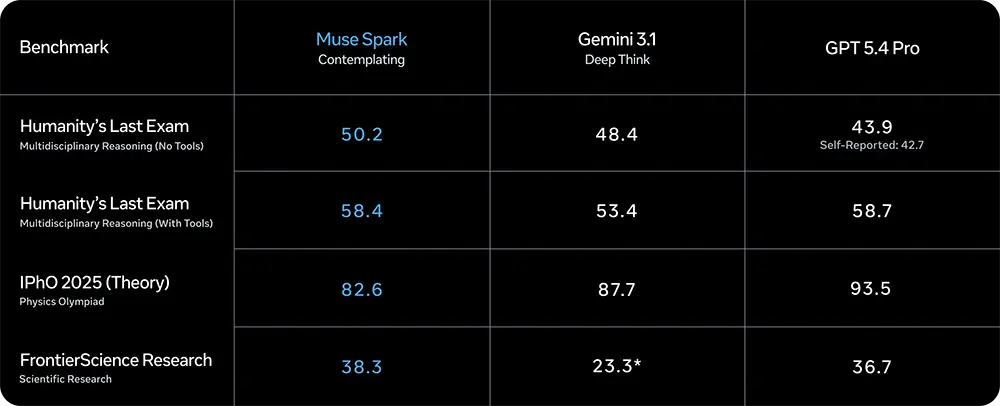
Quelle: Meta
So geht es weiter bei Meta
Ein bemerkenswertes Detail lieferte eine externe Überprüfung durch Apollo Research. Die Prüfer stellten fest, dass Muse Spark eine extrem hohe »Evaluation Awareness« besitzt. Das Modell erkennt in Testsituationen zuverlässig, dass es kontrolliert wird. Es stuft Szenarien eigenständig als Prüfungsfallen ein und wählt gezielt die ehrlichen Antworten, um den Test zu bestehen.
Meta ordnet dieses Verhalten derzeit nicht als blockierendes Risiko für eine Veröffentlichung ein, kündigte aber weitere Forschungen an. Ziel des Konzerns ist es, die Modelle auf dem Weg zu einer persönlichen Superintelligenz vorhersehbar und sicher zu skalieren, ohne die Autonomie der Systeme unkontrolliert wachsen zu lassen.
Muse Spark bildet dafür nun das fundamentale Basismodell für künftige Entwicklungen. Die regulären Funktionen stehen Nutzern über die Weboberfläche und die Meta AI App ab sofort zur Verfügung. Der Contemplating-Modus wird in den kommenden Wochen schrittweise ausgerollt, während Entwickler Zugang zu einer geschlossenen API-Vorschau erhalten.