Claude Opus 4.6 dominiert bei Coding und Agenten
Neue Benchmarks zeigen fast verdoppelte Leistungswerte bei wissenschaftlichen Analysen und der Erkennung von kritischen Sicherheitslücken.

Anthropic hat heute Claude Opus 4.6 veröffentlicht und positioniert das Modell als neues Werkzeug für komplexe Enterprise-Aufgaben. Mit einem Kontextfenster von einer Million Token und drastisch verbesserten Fähigkeiten bei der Steuerung von Computer-Agenten hebt sich das Modell deutlich vom Vorgänger ab.
Das Gedächtnis-Upgrade
Das auffälligste Merkmal von Opus 4.6 ist die massive Erweiterung und Stabilisierung des Kontextfensters. Während viele Modelle bei großen Datenmengen an Präzision verlieren, zeigt Opus 4.6 im "Long-context retrieval" (MRCR v2) beeindruckende Werte. Bei einer Auslastung von 256.000 Token erreicht das Modell eine Trefferquote von 93 Prozent.
Anzeige
Selbst bei voller Auslastung von einer Million Token hält Opus 4.6 noch eine Genauigkeit von 76 Prozent. Zum Vergleich: Das effizientere Schwestermodell Sonnet 4.5 bricht hier auf unter 20 Prozent ein. Für Nutzer bedeutet das, dass das Modell ganze Codebasen oder umfangreiche Finanzberichte analysieren kann, ohne relevante Details in der Mitte des Textes zu "vergessen". Diese Stabilität ist essenziell für Unternehmen, die verlässliche Analysen großer Datensätze benötigen.
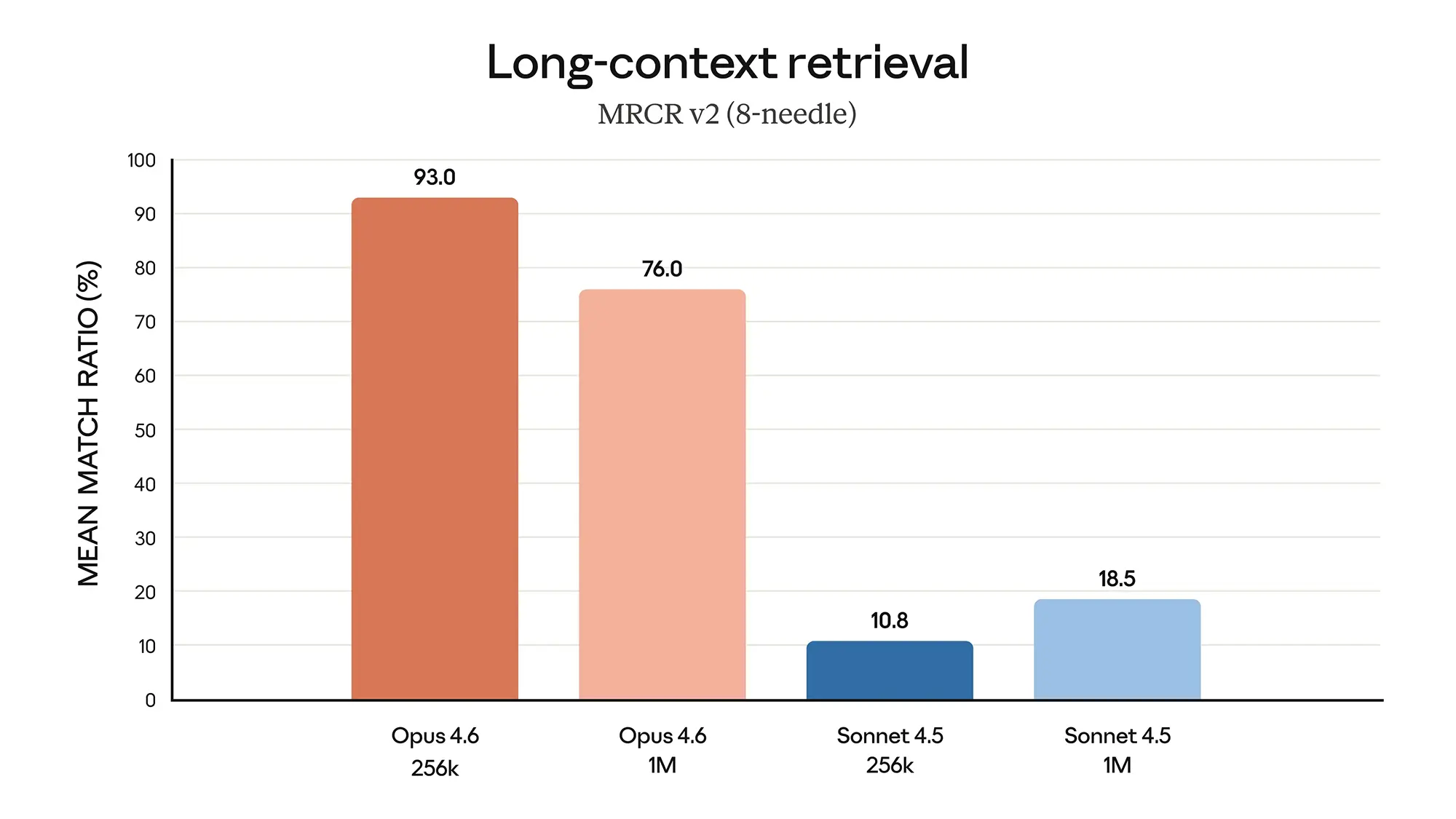
Quelle: Anthropic
Agenten und Coding im Fokus
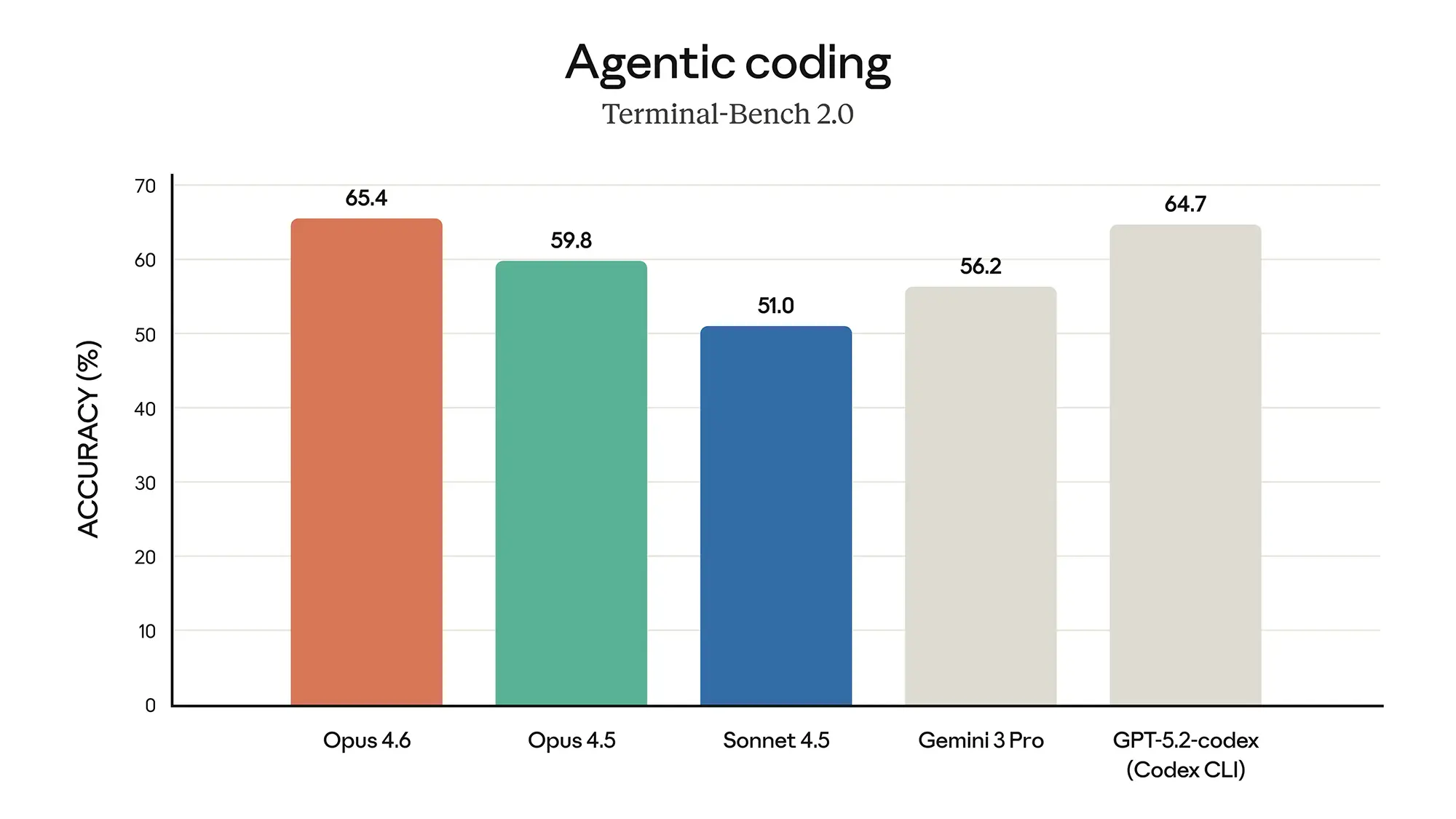
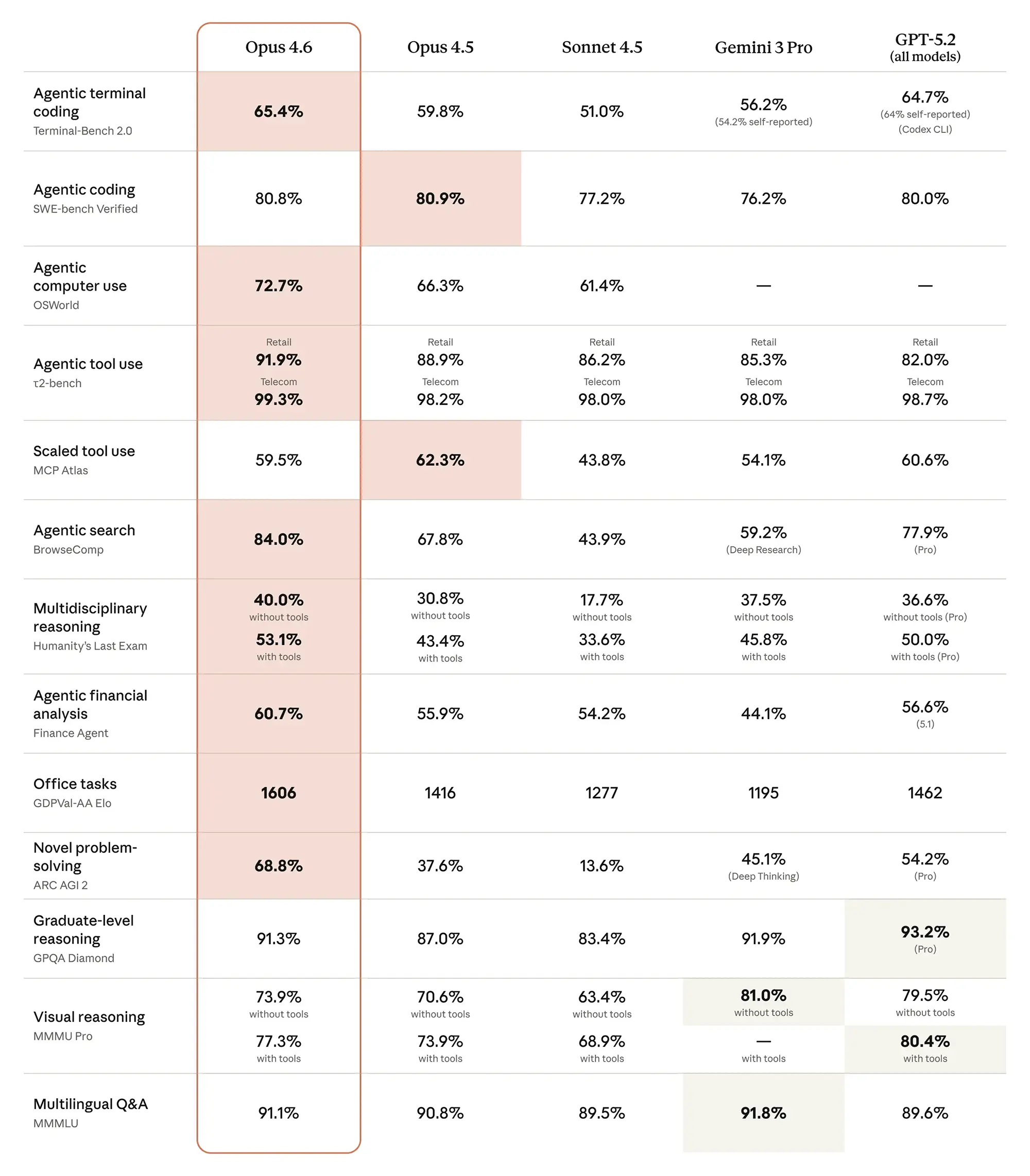
Anthropic zielt mit diesem Update klar auf autonome Arbeitsabläufe ab. Das Modell führt das Konzept von "Agent Teams" ein, bei dem mehrere KI-Instanzen koordiniert an Teilaufgaben arbeiten. Die Benchmarks untermauern diesen Anspruch. Im "Agentic Terminal Coding" erreicht Opus 4.6 einen Wert von 65,4 Prozent und zieht damit knapp an GPT-5.2 (64,7 Prozent) vorbei.
Noch deutlicher wird der Vorsprung bei der Nutzung von externen Tools. Im Telecom-Sektor des "Agentic tool use"-Benchmarks arbeitet das Modell mit einer Präzision von 99,3 Prozent fast fehlerfrei. Das Vorgängermodell Opus 4.5 lag hier bereits hoch, doch die neue Version verfeinert die Zuverlässigkeit bei der Auswahl und Anwendung von Software-Schnittstellen weiter. Das macht die Automatisierung von Backend-Prozessen deutlich risikoärmer.
Spezialwissen in Bio und Security
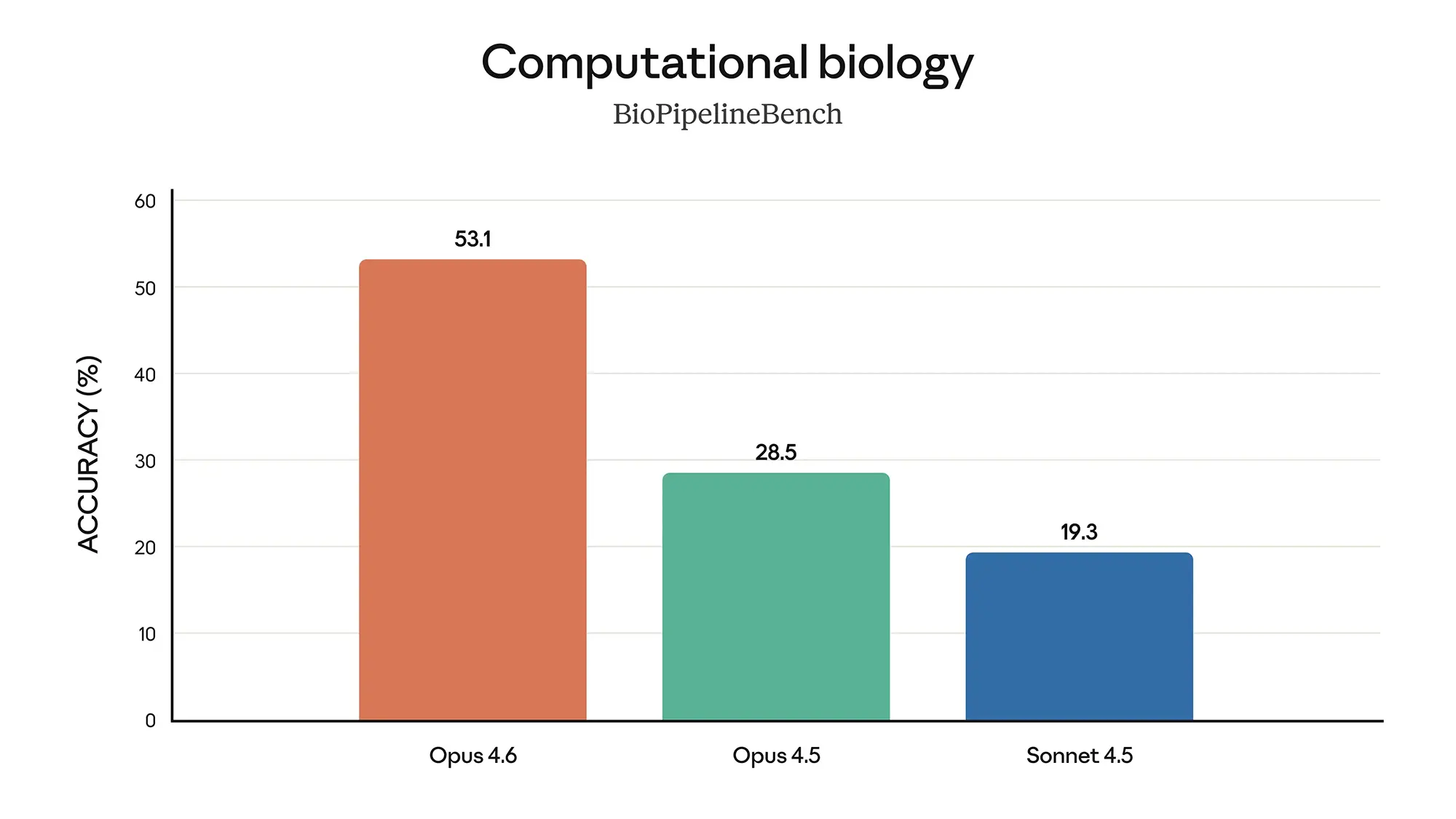
Abseits vom reinen Programmieren zeigt Opus 4.6 ein tiefes Verständnis für naturwissenschaftliche Zusammenhänge. Ein Blick auf den "Computational Biology"-Benchmark offenbart den größten Leistungssprung des Updates. Während Opus 4.5 hier nur 28,5 Prozent erreichte, springt die Version 4.6 auf 53,1 Prozent.
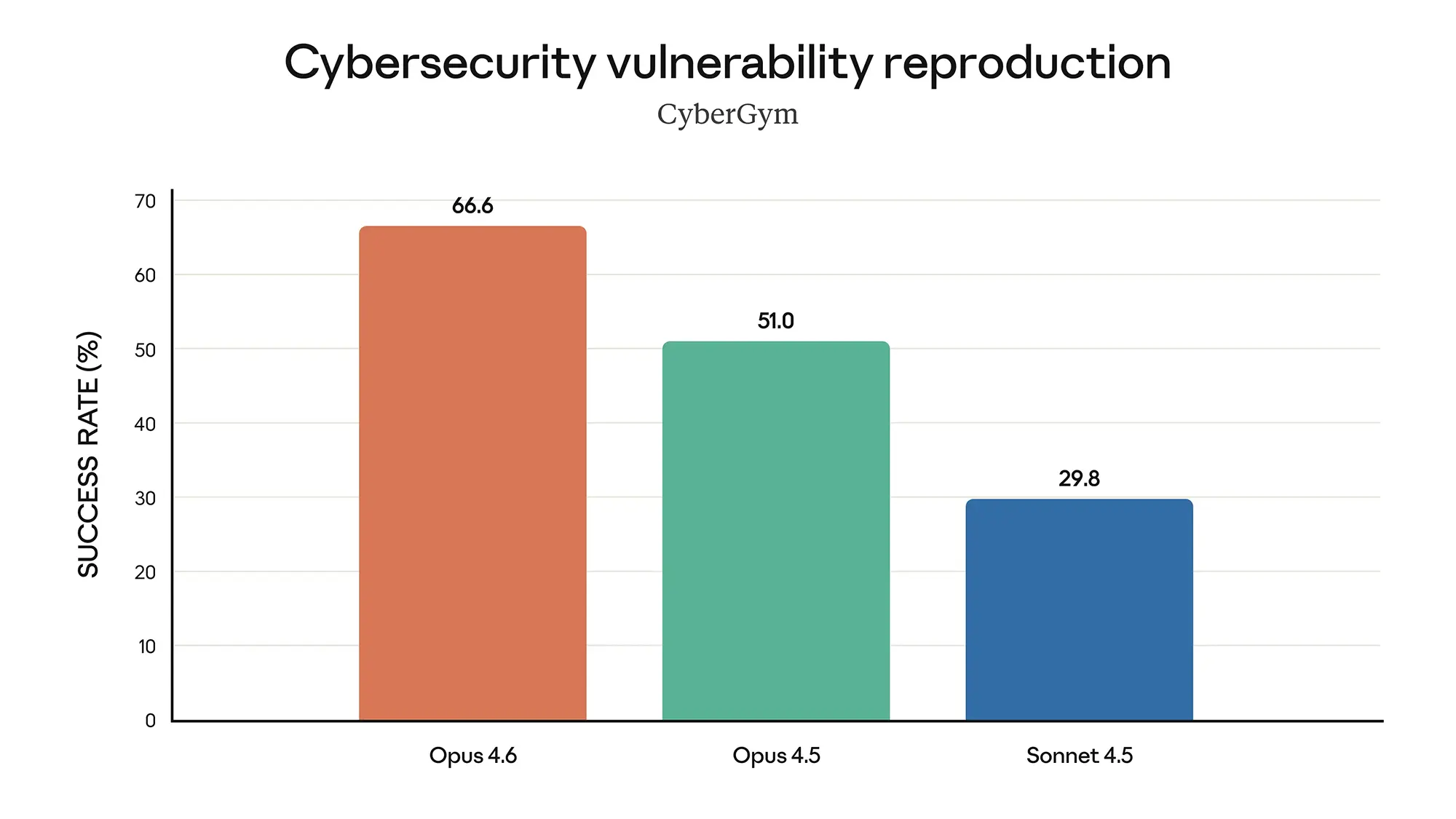
Ähnlich sieht es in der Cybersicherheit aus. Die Fähigkeit, Sicherheitslücken zu reproduzieren (Vulnerability Reproduction), stieg von 51,0 Prozent auf 66,6 Prozent. Das Modell eignet sich damit besser für Red-Teaming-Aufgaben und Sicherheitsaudits als jede bisherige Version. Es versteht nicht nur Code-Syntax, sondern auch die logischen Implikationen komplexer Systemarchitekturen.
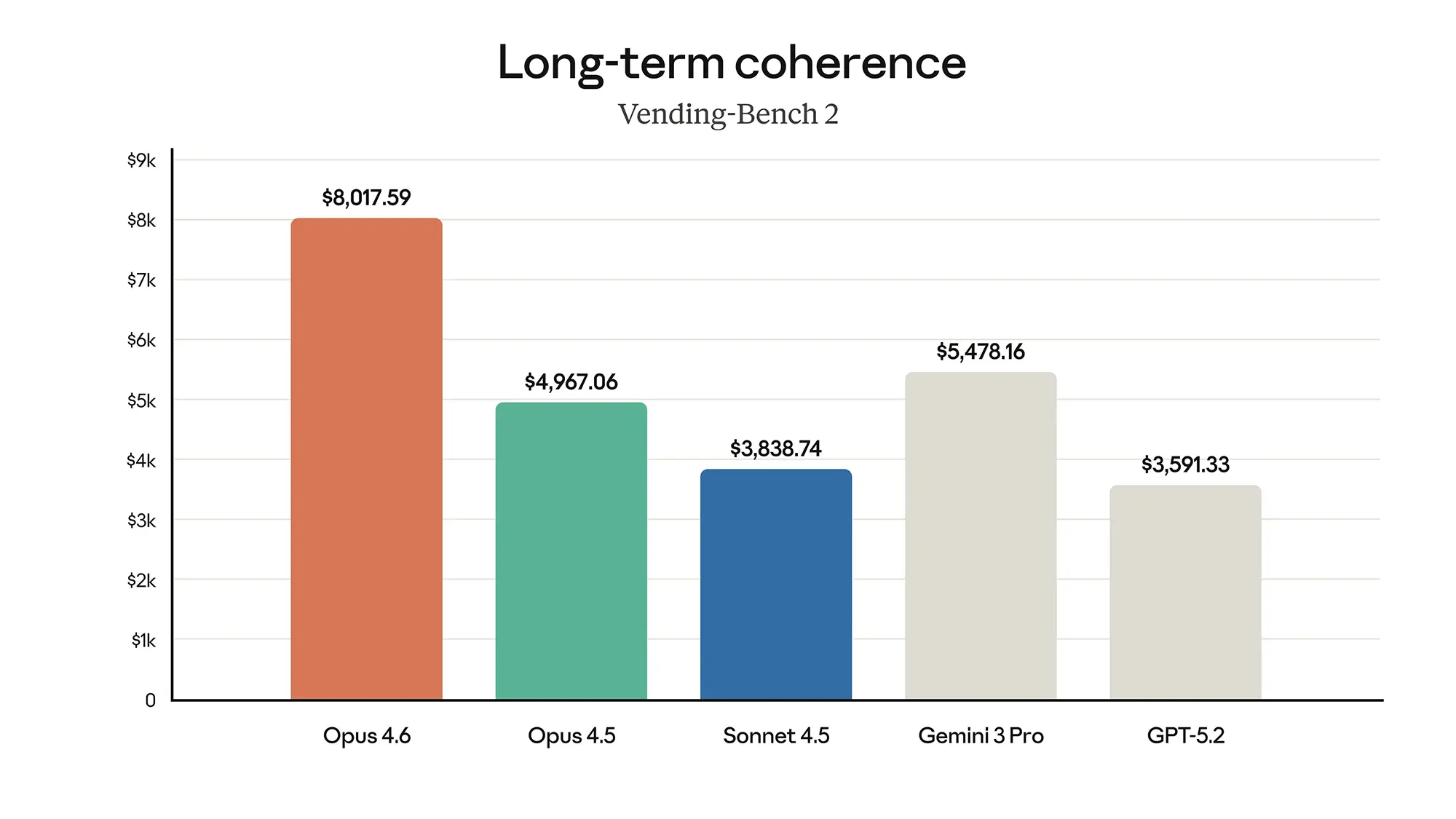
Langzeit-Kohärenz schlägt Konkurrenz
Ein oft unterschätzter Faktor bei KI-Modellen ist die Fähigkeit, über lange Aufgaben hinweg logisch konsistent zu bleiben. Im "Vending-Bench 2", der die langfristige Kohärenz misst, deklassiert Opus 4.6 das Feld. Mit einem Score von über 8.000 Punkten liegt es weit vor Gemini 3 Pro (ca. 5.500) und GPT-5.2 (ca. 3.600).
Das bedeutet in der Praxis weniger "Halluzinationen" oder logische Brüche, wenn das Modell über Stunden hinweg an einem Projekt arbeitet. Während Opus 4.5 hier bereits solide war, liefert das Update die notwendige Stabilität für unbeaufsichtigte Agenten-Tätigkeiten. Anthropic liefert hier kein Spielzeug für Chat-Nutzer, sondern ein Präzisionsinstrument für Entwickler und Analysten.