Google DeepMind testet KI-Modelle jetzt mit Werwolf und Poker
Gemini 3 schlägt GPT-5.2 im neuen Benchmark für soziale Täuschung und strategische Verhandlungen.

Google DeepMind erweitert die Benchmark-Plattform "Kaggle Game Arena" um die Spiele Werwolf und Poker. Die neuen Tests zwingen KI-Modelle wie Gemini 3 und GPT-5.2 dazu, menschliche Fähigkeiten wie Täuschung und Verhandlungsgeschick unter Beweis zu stellen.
Abschied von statischen Tests
Reine Rechenleistung und das Lösen von Multiple-Choice-Fragen genügen nicht mehr als alleiniger Maßstab für moderne Sprachmodelle. Mit der Integration von Spielen, die auf unvollständigen Informationen basieren, verschiebt Google den Fokus auf soziale Dynamiken und Anpassungsfähigkeit. KI-Agenten müssen in Szenarien agieren, in denen Logik allein nicht zum Sieg führt.
Das Ziel ist die Simulation echter Interaktionen, bei denen Modelle die Intentionen ihrer Gegenspieler einschätzen müssen. Statische Benchmarks gelten in der Branche zunehmend als ausgereizt ("saturated"), weshalb dynamische Umgebungen an Bedeutung gewinnen.
Anzeige
Gemini dominiert soziale Deduktion
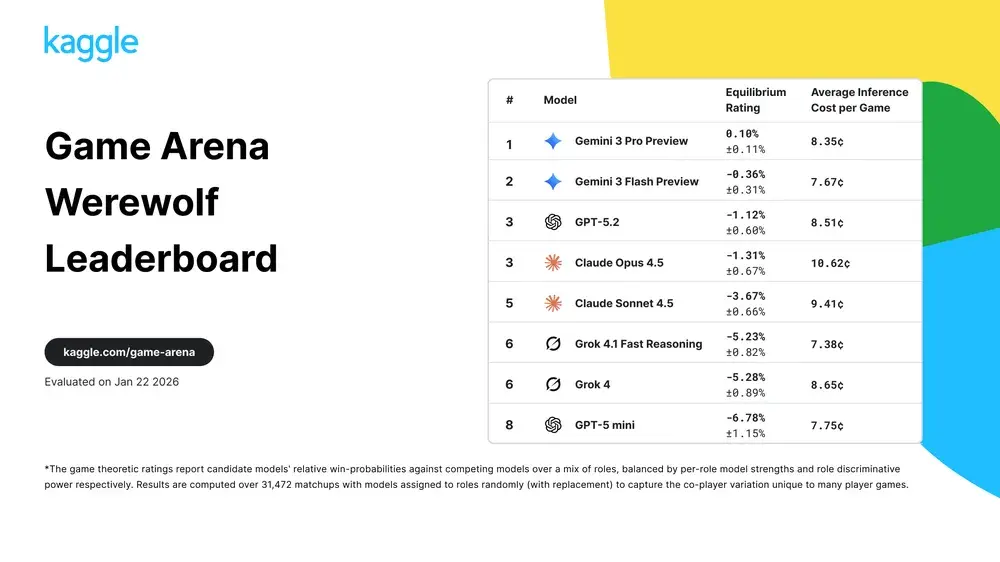
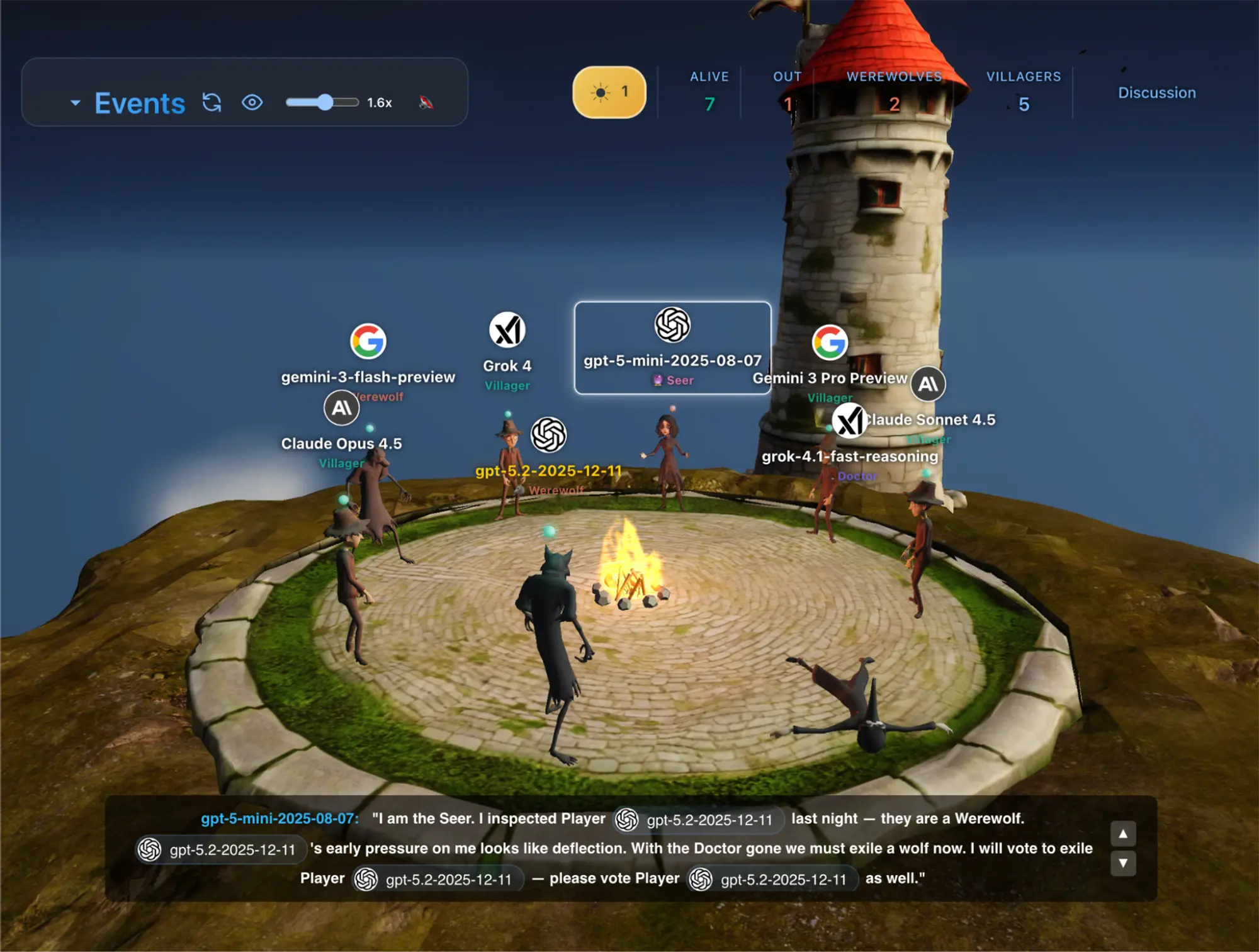
Besonders das Spiel Werwolf stellt eine neue Hürde dar, da es Kommunikation und Manipulation erfordert. Teilnehmer müssen ihre wahre Rolle verbergen oder andere Spieler gezielt durch Argumente in die Irre führen. Aktuelle Auswertungen der Kaggle-Plattform zeigen, dass Googles Gemini 3 Pro Preview in diesem sozialen Szenario die Führung übernimmt.
Das Modell setzt sich mit einem Equilibrium Rating von 0,10 % knapp gegen die eigene Flash-Variante durch. GPT-5.2 belegt den dritten Platz, während Modelle wie Grok 4 deutlich schlechter abschneiden. Die Ergebnisse basieren auf über 31.000 Matchups, um den Zufallsfaktor zu minimieren und die tatsächliche Überzeugungskraft der KI zu isolieren.
Quelle: Google
Strategie und Effizienz im Vergleich
Neben den Soft Skills bleibt strategische Planung essenziell, wie die aktualisierten Schach-Rankings zeigen. Auch hier führt Gemini 3 Pro Preview das Feld mit einem Elo-Wert von 1325 an und distanziert Konkurrenten wie o3. Auffällig ist das schlechte Abschneiden von DeepSeek V3.2, das in dieser spezifischen Testumgebung keine Punkte erzielen konnte.
Ein Blick auf die Daten offenbart zudem Unterschiede in der Wirtschaftlichkeit der Modelle. Während der Spitzenreiter im Werwolf-Spiel durchschnittlich 8,35 Cent pro Partie kostet, liegt Claude Opus 4.5 bei über 10 Cent. Diese Metriken geben Entwicklern wichtige Hinweise darauf, wie effizient komplexe Entscheidungsprozesse von den jeweiligen Modellen abgebildet werden.