Codex Agent Loop: So optimierst du Performance und senkst Token-Kosten
Der neue Engineering-Report enthüllt, warum Caching oft scheitert und wie Kontext-Kompaktierung dein Token-Budget rettet.

OpenAI gewährt erstmals tiefe Einblicke in die Mechanik seiner Coding-Agents. Der neue Engineering-Report zeigt, warum intelligente Agenten oft an simplen Caching-Problemen scheitern und wie der Spagat zwischen endlosem Kontext und begrenzten Ressourcen gelingt.
Wer heute einen KI-Agenten baut, merkt schnell: Das Sprachmodell ist der einfachste Teil. Die wahre Komplexität liegt im "Agent Loop" – jener unsichtbaren Schleife, die entscheidet, wann ein Modell denkt, wann es Werkzeuge nutzt und wie es sich an vergangene Schritte erinnert. OpenAI hat nun mit "Unrolling the Codex agent loop" eine technische Analyse veröffentlicht, die genau diese Architektur dekonstruiert. Für Entwickler ist das Papier eine Warnung und Anleitung zugleich: Wer die Mechanik der "Turns" ignoriert, verbrennt Rechenleistung und Budget.
Die Anatomie der Schleife
Ein Coding-Agent arbeitet nicht linear. Er operiert in Zyklen. OpenAI beschreibt diesen Prozess als ständiges "Ausrollen" (Unrolling) eines Zustands. Ein einzelner Befehl des Nutzers löst eine Kaskade aus: Das Modell plant, ruft ein Tool auf (etwa eine Shell-Ausführung), beobachtet das Ergebnis und korrigiert sich selbst. Das Entscheidende ist das "Harness" – das logische Gerüst um das Modell. Es muss die Rohdaten der Tool-Outputs in ein Format nähen, das das Modell im nächsten Schritt versteht. OpenAI setzt hierbei auf eine strikt zustandslose Architektur über die "Responses API". Das bedeutet: Der Server speichert keinen Status. Bei jedem neuen Schritt wird die gesamte Historie – vom System-Prompt bis zur letzten Fehlermeldung – neu konstruiert. Das klingt ineffizient, garantiert aber die Reproduzierbarkeit, die für komplexe Coding-Aufgaben unerlässlich ist.
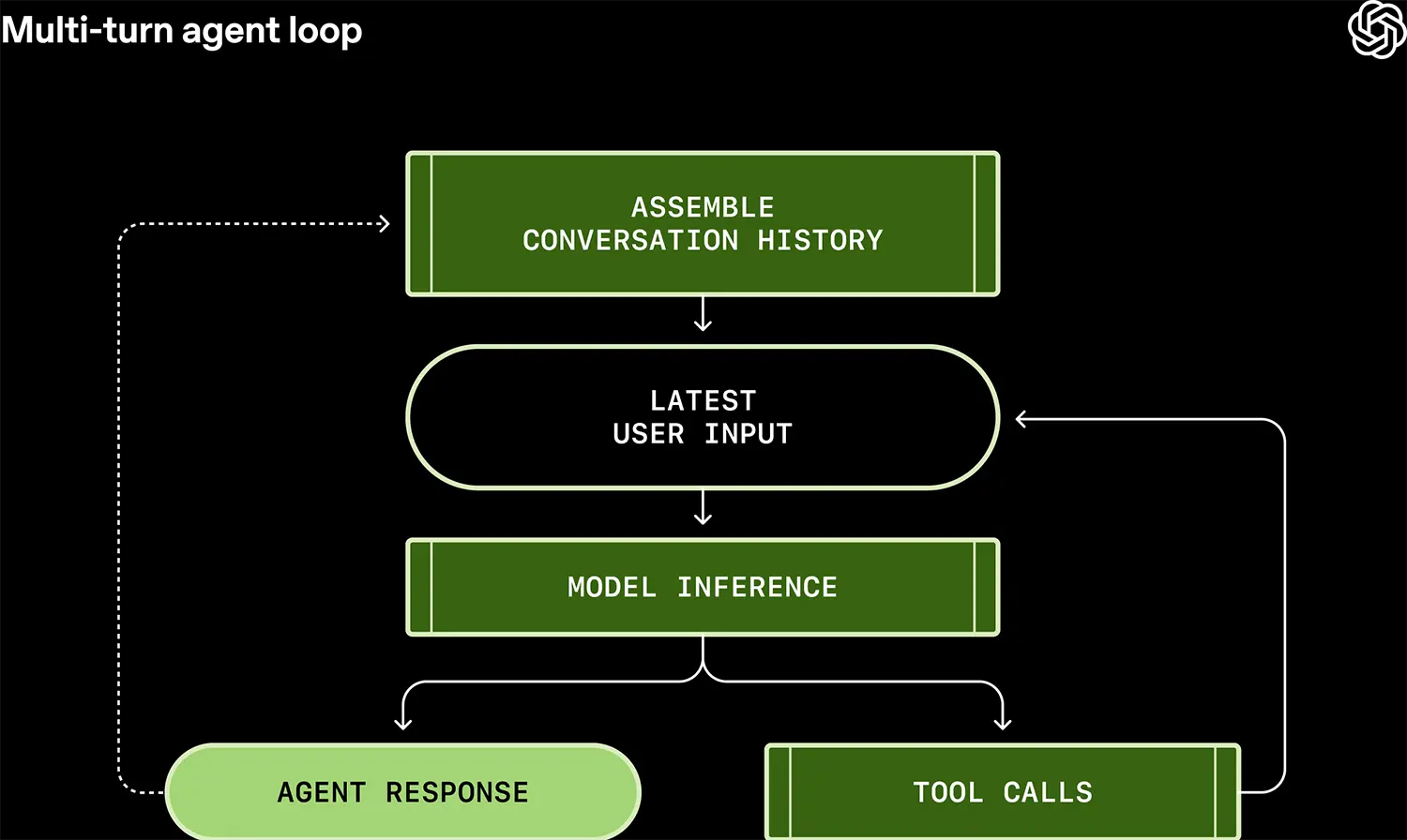
Quelle: OpenAI
Der Cache-Killer MCP
Hier kollidiert Theorie mit Praxis. Um diese riesigen Kontext-Mengen bei jedem Schritt neu zu verarbeiten, ist Prompt Caching (das Zwischenspeichern bereits verarbeiteter Textbausteine) überlebenswichtig. Doch OpenAI warnt vor einer Falle, die besonders durch das Model Context Protocol (MCP) entsteht. MCP gilt 2026 als Standard, um KI-Modellen standardisierte Schnittstellen zu Datenbanken oder Tools zu geben. Das Problem: Caching funktioniert nur bei exakten Übereinstimmungen des Präfix. Ändert ein MCP-Server dynamisch die Liste der verfügbaren Tools mitten in einer Konversation, bricht der Cache. Die Folge ist ein sofortiger Anstieg der Latenz und der Token-Kosten. Entwickler müssen sich entscheiden: Maximale Flexibilität durch dynamische Tools oder maximale Performance durch statische Tool-Listen. Beides gleichzeitig ist kaum möglich.
Anzeige
Gedächtnis durch Kompaktierung
Was passiert, wenn der Loop zu lange läuft? Ein Coding-Agent, der stundenlang debuggt, füllt jedes Kontextfenster. Früher wurden alte Informationen einfach abgeschnitten – ein "Information Loss", der Agenten dumm machte. Die Lösung im Codex-System ist die aktive "Compaction". Statt alte Daten zu löschen, nutzt das System einen Endpunkt (/responses/compact), um vergangene Interaktionen semantisch zusammenzufassen. Der Agent "vergisst" den genauen Wortlaut des Shell-Outputs von vor 20 Minuten, behält aber das Wissen über das Ergebnis. Diese Technik verwandelt den unendlichen Strom an Daten in eine handhabbare Historie und verhindert, dass der Agent in einer Endlosschleife aus wiederholten Fehlern stecken bleibt. Es ist der Unterschied zwischen einem Kurzzeitgedächtnis und echter Erfahrung.