
Drei große Fehler bei Claude Code aufgedeckt
Drei fehlerhafte Updates verursachten die wochenlangen Leistungseinbrüche des KI-Modells.

Nach wochenlanger Kritik an der schwindenden Qualität von Claude Code liefert Anthropic eine technische Erklärung. Drei voneinander unabhängige Systemanpassungen verursachten die weitreichenden Leistungsabfälle. Der Entwickler hat die Fehler eliminiert und entschädigt alle betroffenen Abonnenten.
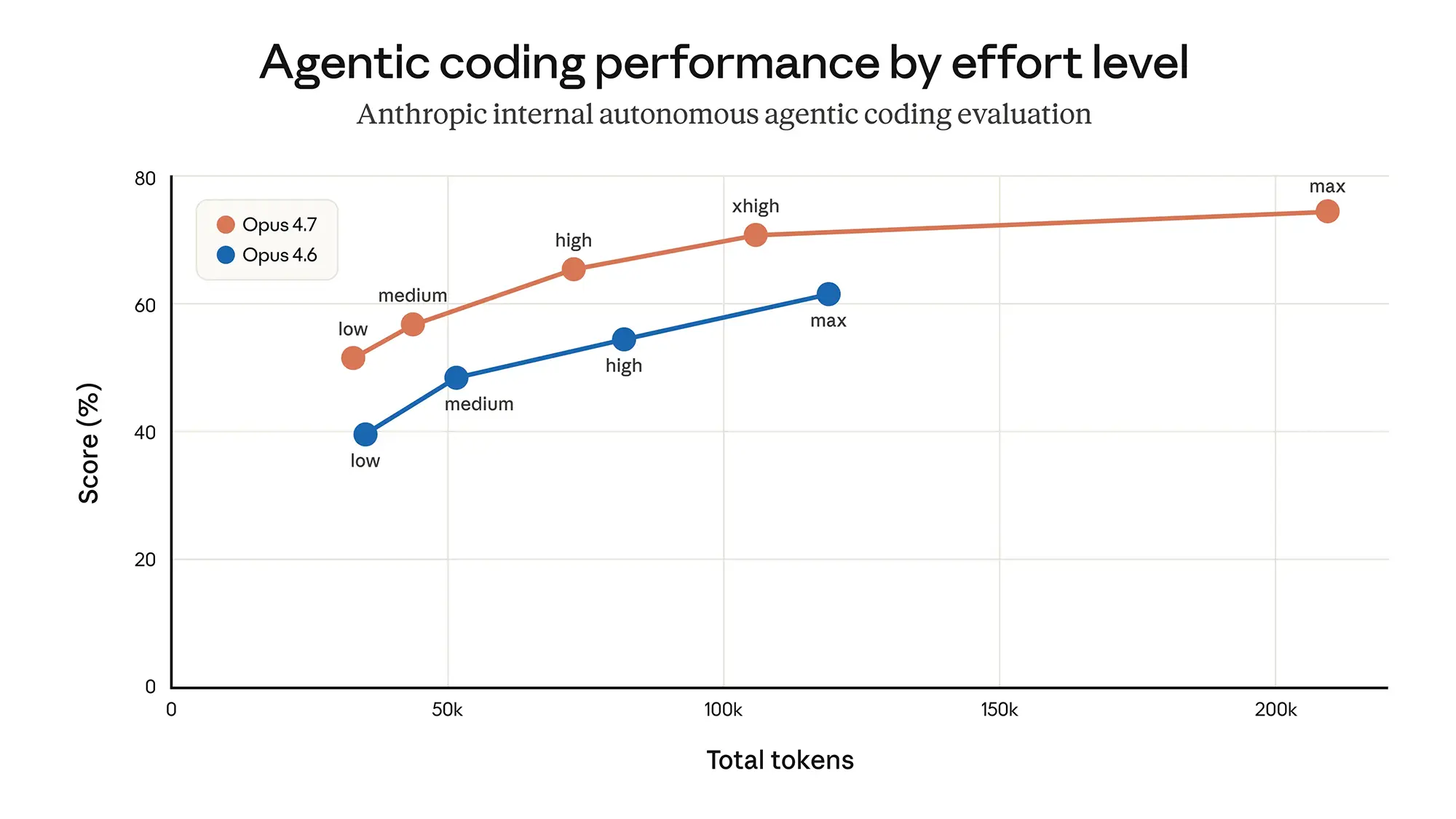
Weniger Rechentiefe für schnellere Antworten
Anfang März modifizierte das Entwicklerteam die Standard-Rechentiefe des KI-Modells. Um die extremen Latenzzeiten im System zu senken, reduzierte man den sogenannten Reasoning-Effort kurzerhand von »high« auf »medium«. Nutzer beklagten bald darauf spürbar schlechtere Resultate bei komplexen Programmieraufgaben.
Die anvisierte Balance zwischen Schnelligkeit und Intelligenz ging in der Praxis nicht auf. Interne Tests hatten zuvor zwar verlockend niedrige Latenzen gezeigt, ließen jedoch die sensiblen Reaktionen der Endanwender auf die gesunkene Qualität völlig außer Acht. Anfang April revidierte das Unternehmen diese Fehlentscheidung wieder vollständig.
Quelle: Anthropic
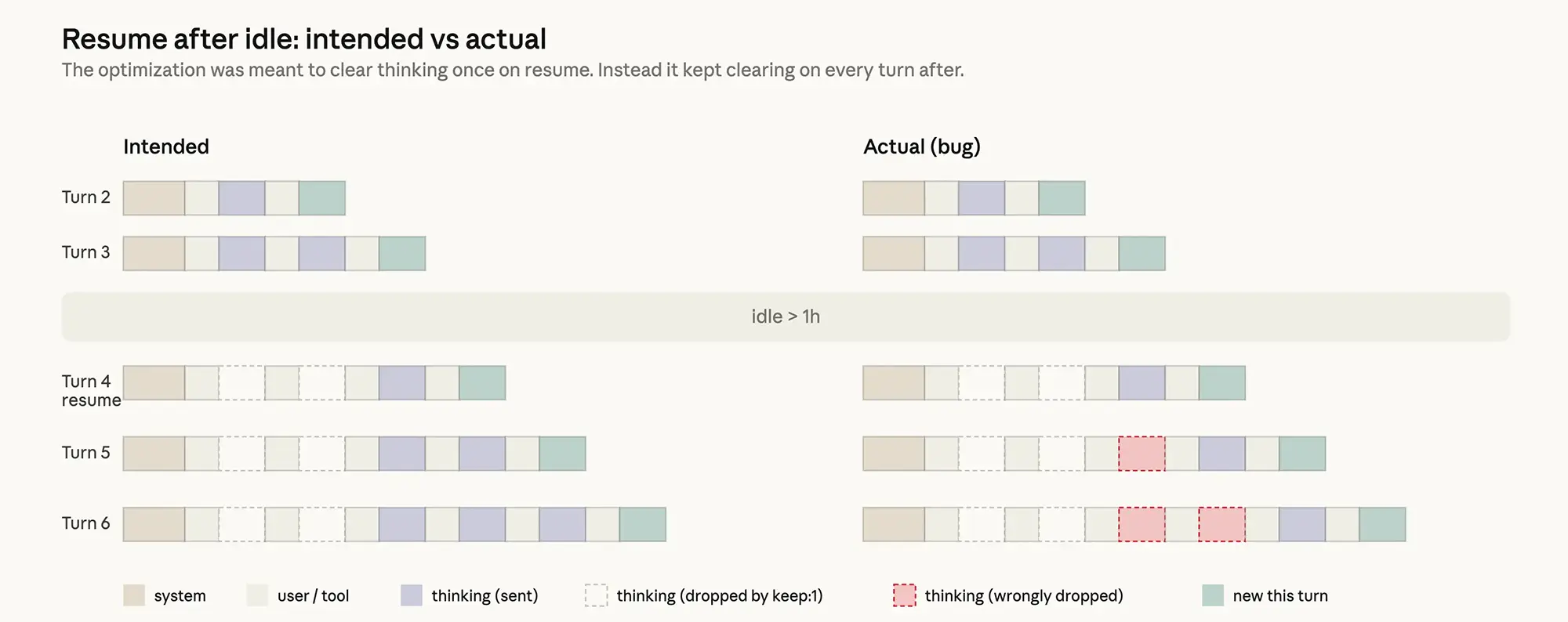
Ein fehlerhafter Zwischenspeicher
Zusätzlich erschwerte ein tiefgreifender Softwarefehler ab Ende März die Nutzung. Eine geplante Optimierung sollte den Cache nach einer Stunde Inaktivität leeren, um Kosten beim Fortsetzen einer Sitzung zu minimieren. Anstatt den Speicher jedoch nur einmalig zu bereinigen, löschte das System den bisherigen Denkprozess fortlaufend bei jeder neuen Eingabe der Anwender.
Dadurch verlor das Modell zunehmend den essenziellen Kontext. Ausgaben wirkten plötzlich repetitiv, während die künstliche Intelligenz den Grund für ihre eigenen vorherigen Entscheidungen schlichtweg vergaß. Erst nach gründlicher Fehlersuche konnte das Team diesen Programmierfehler Mitte April im Code lokalisieren und beseitigen.
Quelle: Anthropic
Zu strenge Wortbegrenzungen
Mitte April führte dann eine weitere gut gemeinte Anpassung zum nächsten unerwarteten Qualitätsverlust. Ein neuer System-Prompt sollte das System dazu zwingen, sich bei Unterhaltungen wesentlich kürzer zu fassen. Die strikte Anweisung begrenzte interne Texte zwischen Tool-Aufrufen auf maximal 25 Wörter.
Diese restriktive Vorgabe schnitt die Leistungsfähigkeit der Modelle stärker ab als vorgesehen. Spätere Auswertungen offenbarten einen messbaren Rückgang der Programmierqualität um exakt drei Prozent. Entsprechend verschwand auch dieser Eingriff wenige Tage später wieder aus dem Quellcode.
Anzeige
Strengere Testverfahren etablieren
Um ähnliche Ausfälle künftig frühzeitig abzufangen, überarbeitet der Anbieter nun seine internen Qualitätssicherungen. Bevor Aktualisierungen an die Öffentlichkeit gelangen, durchlaufen diese künftig deutlich breitere, modellspezifische Evaluationsprozesse. Zudem testen die eigenen Entwickler ab sofort ausschließlich auf den regulären öffentlichen Versionen der Software.
Sämtliche Limits für die Nutzung setzen die Verantwortlichen für alle Abonnenten zurück. Das schafft einen direkten Ausgleich für die unverschuldet verschwendeten Kontingente der vergangenen Wochen. Die Summe der Vorfälle demonstriert eindrucksvoll, wie empfindlich komplexe KI-Systeme auf kleinste Anpassungen in ihrer Infrastruktur reagieren.