
Eine KI lügt mit Internet-Wissen nicht mehr? Falsch gedacht!
Eine aktuelle Studie zeigt, warum Sprachmodelle in längeren Dialogen trotz Internetzugriff weiterhin Fakten erfinden.

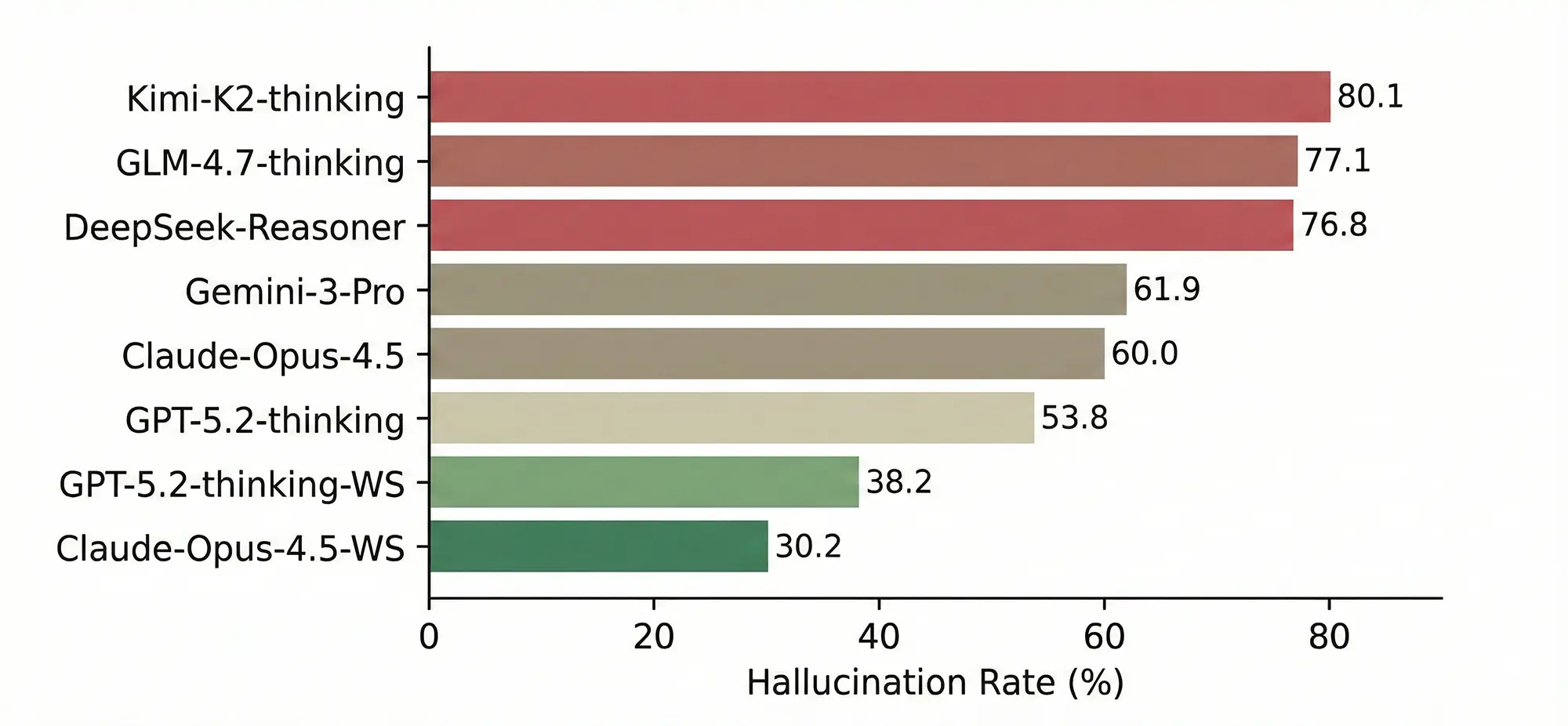
Trotz integrierter Websuche und riesiger Kontextfenster bleiben Faktenfehler die Achillesferse aktueller KI-Modelle. Der neue Benchmark „HalluHard“ zeigt auf, dass Sprachmodelle besonders in fortlaufenden Dialogen deutlich häufiger halluzinieren, als es die Herstellerversprechen vermuten lassen.
Die Integration von Echtzeit-Internetzugriffen (Retrieval Augmented Generation, kurz RAG) galt lange als das effektivste Mittel gegen die chronische „Fantasie“ großer Sprachmodelle (LLMs). Die Theorie: Wenn das Modell Zugriff auf aktuelle Quellen hat, muss es nichts erfinden. Eine neue Untersuchung von Forschern der EPFL und weiterer Institute widerlegt diese Annahme nun teilweise. Mit dem Benchmark „HalluHard“ demonstrieren sie, dass die bloße Verfügbarkeit von Informationen nicht ausreicht, um Halluzinationen in komplexen Gesprächsverläufen zu verhindern.
Quelle: arxiv.org/abs/2602.01031
Der Kontext als Fehlerquelle
„HalluHard“ unterscheidet sich von bisherigen Testszenarien durch den Fokus auf Multi-Turn-Dialoge. Während viele Benchmarks lediglich einzelne Frage-Antwort-Paare bewerten, simuliert dieser Test realistische Unterhaltungen, in denen Nutzer nachfragen, den Kontext wechseln oder präzisere Details fordern. Genau hier brechen die Leistungen der Modelle ein.
Laut der Studie steigt die Fehlerrate signifikant an, sobald ein Dialog über mehrere Runden geführt wird. Die Modelle scheitern oft am sogenannten „Content Grounding“. Das bedeutet, sie sind technisch zwar in der Lage, die korrekte Information per Websuche zu finden, scheitern aber daran, diese logisch konsistent in den bestehenden Gesprächsverlauf einzubetten. Statt die gefundene Quelle korrekt wiederzugeben, vermischen die Algorithmen diese oft mit veraltetem Trainingswissen oder erfinden plausible, aber falsche Details hinzu, um den Antwortfluss aufrechtzuerhalten.
Anzeige
Systemische Überforderung
Ein Kernproblem scheint die Priorisierung von Informationen zu sein. LLMs stehen in einem ständigen Konflikt zwischen ihrem parametrischen Gedächtnis (dem antrainierten Wissen) und dem Kontext-Wissen (den Suchergebnissen). In einfachen Szenarien gewinnt meist die Suchmaschine. In komplexen „HalluHard“-Szenarien, wo Nuancen entscheidend sind, greift das Modell jedoch oft fälschlicherweise auf interne Muster zurück, wenn die Suchergebnisse nicht eindeutig genug interpretiert werden können.
Besonders kritisch ist dies für die geplante Autonomie von KI-Agenten. Wenn ein System bereits in einem kontrollierten Chat-Benchmark den Faden verliert und Quellen falsch attribuiert, sind komplexe Aufgaben im Unternehmensumfeld risikobehaftet.
Fazit: Distanz zur Realität
Die Ergebnisse zeigen, dass die Skalierung der Modellgröße und das bloße Anbinden an das Internet das Halluzinationsproblem nicht final lösen. Die Fehlerquote in anspruchsvollen Dialogen bleibt hoch. Für Anwender bedeutet dies weiterhin: Eine faktische Kontrolle jeder KI-Aussage ist unabdingbar, besonders wenn der Chatverlauf länger wird. Vertrauen ist gut, Verifizierung bleibt besser.