
Gemini 3.5 Snowbunny zerstört GPT 5.2
Ein interner Benchmark-Leak zeigt unglaubliche Reasoning-Fähigkeiten und lässt die Konkurrenz im neuen Heiroglyph-Test weit hinter sich.

Ein angeblicher Benchmark-Leak offenbart ein neues Google-Modell mit dem Codenamen „Snowbunny“, das die Konkurrenz von OpenAI im Bereich des lateralen Denkens weit hinter sich lässt. Sollten sich die kursierenden Daten bestätigen, markiert dies einen signifikanten technologischen Sprung für die Fähigkeiten künstlicher Intelligenz im Jahr 2026.
Dominanz im „Heiroglyph“-Test
In Tech-Foren und auf der Plattform X kursiert derzeit eine Grafik, die Ergebnisse des sogenannten „Heiroglyph Benchmark“ zeigt. Dieser Test spezialisiert sich auf „Lateral Reasoning“, also die Fähigkeit einer KI, Probleme durch indirekte und kreative Ansätze zu lösen, statt durch reine Logikketten. Die Ergebnisse sind für Branchenbeobachter überraschend deutlich.
Das Modell „snowbunny (raw)“ erreicht in diesem Vergleich einen Wert von 16 von 20 möglichen Punkten. Zum Vergleich: Das als derzeitiger Marktführer gehandelte GPT-5.2 (High) kommt lediglich auf 11 Punkte. Selbst Googles eigenes Gemini 3.0 Pro Preview liegt mit 9 Punkten weit abgeschlagen hinter der neuen internen Version.
Besonders interessant ist die Tatsache, dass zwei Versionen des Modells gelistet werden: eine „raw“-Variante und eine „less raw“-Version. Dass beide Varianten identische 80 Prozent erreichen, deutet darauf hin, dass die sonst üblichen Sicherheitsfilter („Safety Alignment“) bei diesem Modellmodell keine negativen Auswirkungen auf die reine Denkleistung haben. Dies war bei früheren Generationen oft ein technischer Flaschenhals.
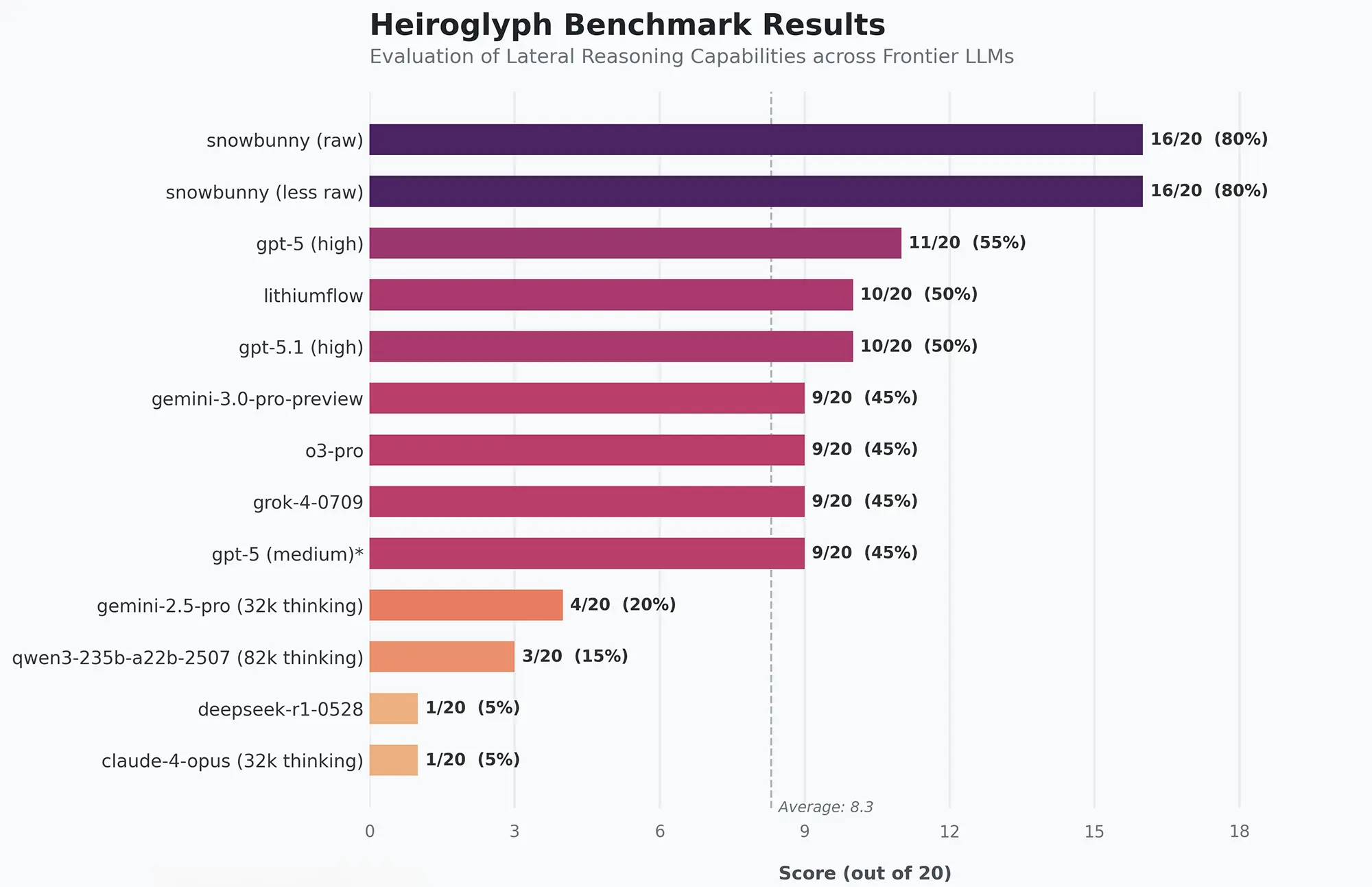
Quelle: X @synthwavedd
Ist Snowbunny das kommende Gemini 3.5?
Experten gehen davon aus, dass es sich bei dem Codenamen um das kommende Gemini 3.5 handelt. Die Nomenklatur und die zeitliche Abfolge der Leaks passen zur Release-Strategie, die Google in den letzten Jahren verfolgt hat. Nach der Einführung von Gemini 3.0, welches sehr gute, aber nicht bahnbrechende Verbesserungen brachte, scheint das Unternehmen nun den Fokus auf tieferes Verständnis zu legen.
Die Bezeichnung „Reasoning Depth“ wird in aktuellen Analysen immer wichtiger. Während reine Sprachmodelle Texte statistisch vorhersagen, simulieren Reasoning-Modelle einen bewussten Denkprozess („System 2 Thinking“), bevor sie antworten. Der massive Punktezuwachs im Heiroglyph-Test lässt vermuten, dass Google hier einen architektonischen Durchbruch erzielt hat, der über bloße Skalierung der Rechenleistung hinausgeht.
Anzeige
Skepsis bleibt angebracht
Trotz der vielversprechenden Zahlen ist Vorsicht geboten. Screenshots von Benchmarks lassen sich leicht fälschen und der Heiroglyph-Benchmark ist zwar in Fachkreisen bekannt, aber nicht so etabliert wie der klassische MMLU-Test. Dennoch decken sich die Daten mit Berichten über neue „Deep Thinking“-Funktionen in der Vertex AI Cloud von Google.
Sollte das Modell in dieser Form erscheinen, würde sich das Kräfteverhältnis im KI-Markt 2026 erneut verschieben. Modelle wie Claude 4 Opus oder Grok 4 wirken in dieser spezifischen Metrik mit Werten unter 50 Prozent fast schon veraltet. Google scheint bereit zu sein, die Technologieführerschaft nicht nur zu beanspruchen, sondern durch messbare Intelligenzsprünge zu beweisen.