
Nvidia PersonaPlex: Der Todesstoß für OpenAIs Advanced Voice Mode?
Kostenlos und lokal statt teures Abo: Das neue offene Sprachmodell bietet Features, die bisher nur ChatGPT vorbehalten waren.

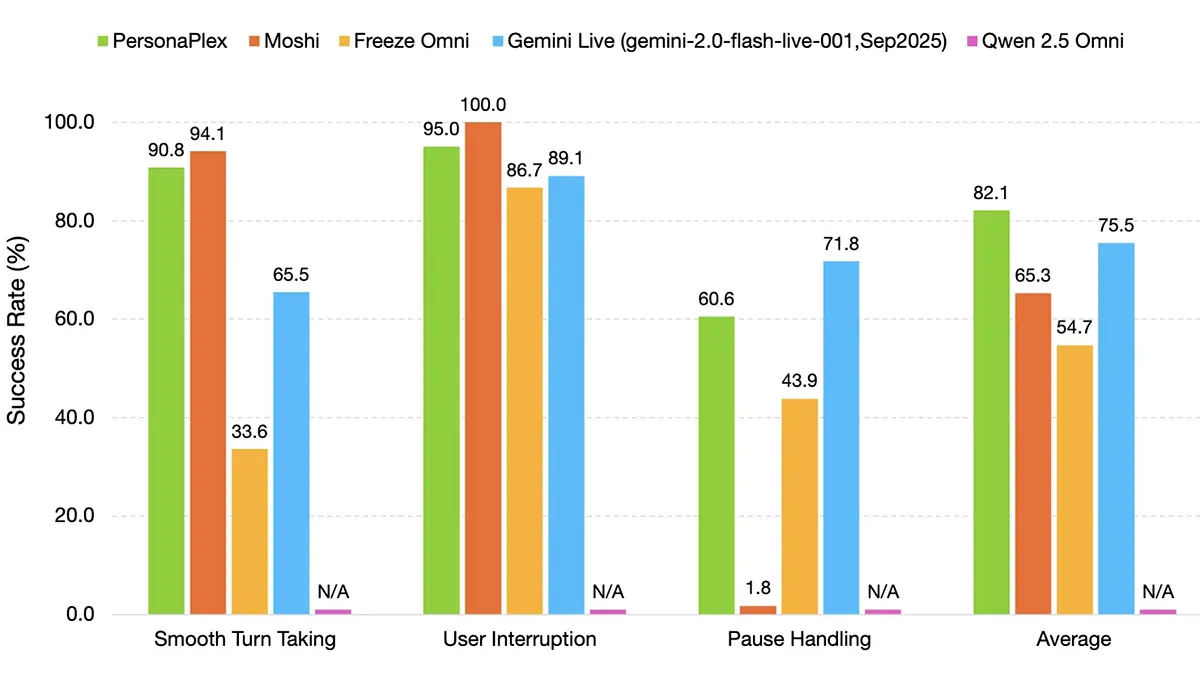
Nvidia bringt mit PersonaPlex Bewegung in den Markt für Sprach-KIs. Das neue, offene 7-Milliarden-Parameter-Modell beherrscht Full-Duplex-Kommunikation und ermöglicht damit Unterbrechungen in Echtzeit. Entwickler erhalten eine leistungsstarke, lokal ausführbare Alternative zu geschlossenen Systemen wie ChatGPT Voice.
Ende des Walkie-Talkie-Modus
Bisherige Sprachassistenten arbeiten überwiegend sequenziell. Der Nutzer spricht, das System verarbeitet die Eingabe und antwortet erst anschließend. Nvidia bricht mit diesem Schema durch die Implementierung einer echten Full-Duplex-Architektur. Das System verarbeitet Audioeingaben permanent und parallel zur eigenen Sprachausgabe, statt in starren Abfolgen zu operieren.
Nutzer können der KI nun ins Wort fallen, ohne dass diese den Kontext verliert oder künstliche Pausen entstehen. Das Gesprächsgefühl nähert sich damit signifikant menschlicher Interaktion an, da das Modell auf verbale Einwürfe sofort reagiert. Die Latenzzeiten wurden laut technischen Dokumentationen so weit reduziert, dass sie unterhalb der menschlichen Wahrnehmungsschwelle für Gesprächspausen liegen.
Anzeige
Effizienz durch 7B-Architektur
Technisch basiert PersonaPlex auf einem Modell mit sieben Milliarden Parametern (7B). Diese Größe stellt einen bewussten Kompromiss zwischen hoher Dialogkompetenz und technischer Effizienz dar. Im Gegensatz zu riesigen Large Language Models (LLMs), die massive Serverfarmen benötigen, lässt sich PersonaPlex auf kommerziell verfügbarer Hardware betreiben.
Voraussetzung sind aktuelle Grafikbeschleuniger, womit Nvidia die Relevanz der eigenen RTX- und Datacenter-GPUs unterstreicht. Die Möglichkeit zur lokalen Inferenz eliminiert Netzwerklatenzen, die bei Cloud-Lösungen oft den Gesprächsfluss stören, und bietet Unternehmen die volle Kontrolle über ihre Daten. Sensible Gesprächsinhalte verlassen somit nicht zwingend die eigene Infrastruktur.
Quelle: nvidia
Dynamische Persönlichkeiten statt statischer Stimmen
Eine Kernfunktion der neuen Architektur ist die flexible Anpassung von Persönlichkeitsprofilen, die über den reinen Inhalt hinausgehen. Über System-Prompts lassen sich spezifische Verhaltensweisen definieren, die Tonfall, Sprechgeschwindigkeit und Reaktionsmuster dynamisch steuern. Das System trennt dabei die akustische Synthese nicht mehr strikt von der inhaltlichen Generierung.
Das Modell wechselt bei Bedarf fließend zwischen einem sachlichen Berater und einem empathischen Gesprächspartner, je nach definiertem Szenario. Nvidia zielt damit primär auf den Kundenservice und komplexe Gaming-Anwendungen, in denen statische, emotionslose Computerstimmen oft die Immersion brechen.
Angriff auf geschlossene Ökosysteme
Mit der Veröffentlichung als offenes Modell setzt Nvidia die Konkurrenz unter Druck. Bislang dominierten Anbieter wie OpenAI mit dem "Advanced Voice Mode" dieses Segment über geschlossene Schnittstellen. PersonaPlex bietet der Open-Source-Community nun eine Basis, um eigene, spezialisierte Sprachanwendungen zu entwickeln, ohne Lizenzgebühren pro gesprochener Minute an Cloud-Anbieter abzuführen.