o1 vs. GPT-4 in der Chatbot-Arena
Hat OpenAI seinen eigenen Champion entthront?

Flux | All-AI.de
Worum geht es?
OpenAI's neueste KI-Modelle, o1-preview und o1-mini, haben in der Chatbot-Arena für Furore gesorgt. Sie führen in fast allen Kategorien und scheinen die Konkurrenz abzuhängen. Doch bevor wir in Jubel ausbrechen, sollten wir einen genaueren Blick auf die Daten werfen. Könnte die geringe Anzahl der Bewertungen das Ergebnis verzerren?
News
Überlegene Leistung, aber kleine Stichprobe
Die Chatbot-Arena, eine Plattform zum Vergleich verschiedener KI-Modelle, hat die Leistung der neuen OpenAI-Systeme mit über 6.000 Community-Bewertungen evaluiert. Dabei zeigten sich o1-preview und o1-mini besonders stark bei mathematischen Aufgaben, harten Prompts und Programmierung.
Allerdings haben o1-preview und o1-mini bisher deutlich weniger Bewertungen erhalten als etablierte Modelle wie GPT-4o oder Claude 3.5 von Anthropic. Diese geringe Stichprobengröße könnte zu Verzerrungen in der Bewertung führen.
o1: Mehr Denkzeit für bessere Antworten
OpenAI's o1 soll durch längeres "Nachdenken" vor der Antwort einen neuen Standard für KI-Logik setzen. Die o1-Modelle sind jedoch nicht in allen Bereichen besser als der Vorgänger GPT-4o. Viele Aufgaben erfordern kein komplexes logisches Denken, und in manchen Fällen ist eine schnelle Antwort von GPT-4o ausreichend.
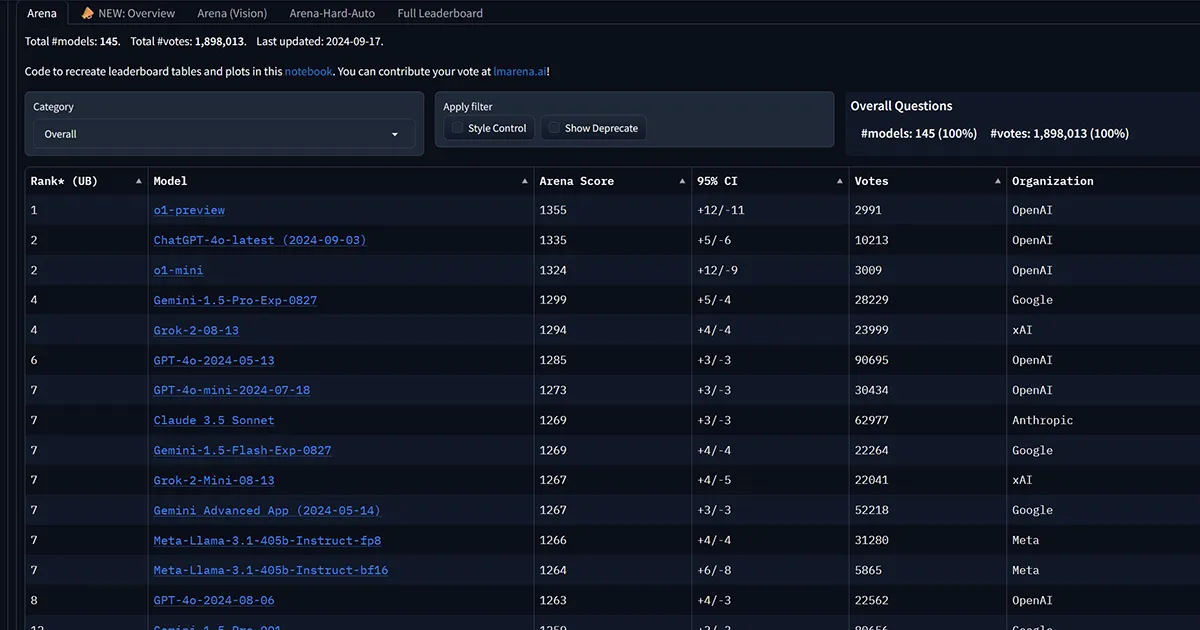
Die ersten Ergebnisse der Chatbot-Arena sind vielversprechend für OpenAI's o1-Modelle. Sie zeigen das Potenzial für verbesserte KI-Logik und Leistung, insbesondere bei anspruchsvollen Aufgaben. Es bleibt jedoch abzuwarten, wie sich die Modelle bei einer größeren Anzahl von Bewertungen schlagen werden.

Short
- OpenAI's neue KI-Modelle o1-preview und o1-mini führen in der Chatbot-Arena.
- Die Modelle zeigen besonders gute Leistungen bei mathematischen Aufgaben, harten Prompts und Programmierung.
- o1 setzt durch längeres "Nachdenken" vor der Antwort neue Standards für KI-Logik.
- Die geringe Anzahl der Bewertungen könnte jedoch das Ergebnis verzerren.
- Es bleibt abzuwarten, wie sich die Modelle bei einer größeren Anzahl von Bewertungen schlagen werden.