
Text im Bild: Tencent überholt GPT-4o knapp
X-Omni punktet in Benchmarks mit beeindruckender Textqualität. Was bedeutet das für den KI-Markt?

Tencent | All-AI.de
EINLEITUNG
Mit X-Omni stellt Tencent ein KI-System vor, das gleich mehrere offene Komponenten kombiniert – und dabei GPT-4o erstaunlich nahekommt. Besonders bei der Darstellung von Text in Bildern zeigt das Modell in Benchmarks starke Ergebnisse. Möglich macht das ein neuartiger Trainingsansatz mit Reinforcement Learning. Was steckt hinter diesem Open-Source Herausforderer?
NEWS
Zwei Modelle, ein gemeinsames Ziel
X-Omni verbindet ein autoregressives Sprachmodell mit einem Diffusionsdecoder. Ersteres plant, welche Bedeutungselemente im Bild erscheinen sollen, letzterer erzeugt daraus die visuellen Inhalte. Während viele vergleichbare Systeme beide Komponenten separat trainieren, geht Tencent einen anderen Weg: Reinforcement Learning bringt die Modelle gezielt aufeinander abgestimmt ins Gleichgewicht.
Die Technik dahinter ist ausgeklügelt. Statt Bilder pixelweise zu analysieren, nutzt X-Omni eine semantische Tokenisierung. Ein spezieller Tokenizer zerlegt Bilder in über 16.000 Bedeutungseinheiten. Grundlage ist das Open-Source-Modell Qwen2.5 von Alibaba, erweitert um visuelle Schichten. Der Decoder FLUX.1-dev stammt vom Freiburger Start-up Black Forest Labs.
Gelernt wird über ein mehrstufiges Bewertungssystem. Es prüft, ob Bilder ästhetisch wirken, die Texteingabe korrekt umgesetzt ist und ob eingebetteter Text gut lesbar bleibt. Daraus ergibt sich Feedback, das die Token-Erzeugung Schritt für Schritt verbessert.

Quelle: Tencent
Starke Texte, gute Bilder
In Benchmarks zeigt sich der Vorteil dieses Ansatzes vor allem bei der Darstellung von Text. Im englischen OneIG-Test erreicht X-Omni 0,901 Punkte – der höchste gemessene Wert. Auch bei chinesischen Texten liegt es weit vorn. Auf dem neuen LongText-Benchmark überzeugt das Modell besonders bei langen Absätzen. Zwar gibt es bei dichten Texten noch gelegentliche Fehler, doch die Lesequalität ist insgesamt hoch.
Bei der Bildgenerierung erreicht X-Omni auf dem DPG-Benchmark 87,65 Punkte – mehr als GPT-4o und alle anderen offenen „Unified Models“. Auch beim OCRBench, der Textgenauigkeit prüft, schneidet X-Omni solide ab. Der Vorsprung ist meist gering, aber konstant.
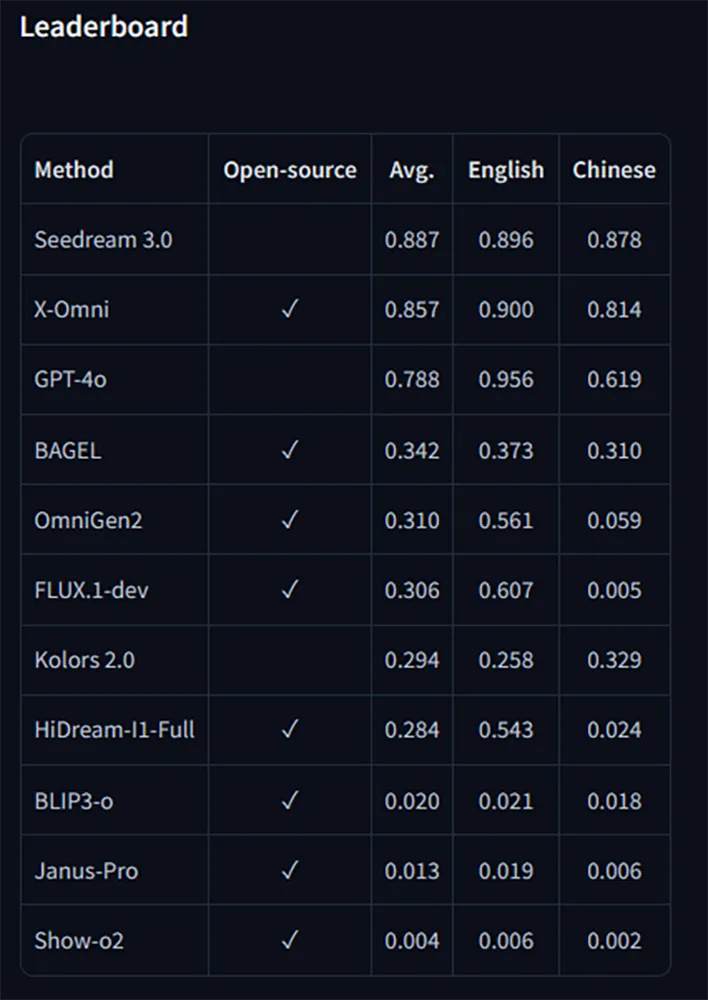
Quelle: Tencent
Ein Open-Source-System mit Ambitionen
Tencents Ansatz zeigt, wie leistungsfähig offene Kombinationen sein können. X-Omni nutzt Komponenten unterschiedlicher Herkunft – auch von Konkurrenten – und formt daraus ein Modell auf hohem Niveau. Der Quellcode, Modelle und sogar ein Datensatz für lange Texte in Bildern stehen frei zur Verfügung.
Ein großer Durchbruch ist es nicht. Doch X-Omni zeigt, wie sich Qualität und Offenheit verbinden lassen. Das System ist kein fertiges Produkt, sondern eine starke Basis für weitere Entwicklung – und ein spannendes Signal, dass Open-Source-Projekte zunehmend mit großen kommerziellen Modellen mithalten können.
DEIN VORTEIL - DEINE HILFE
KURZFASSUNG
- Tencent hat mit X-Omni ein Open-Source-Bildmodell vorgestellt, das GPT-4o in Benchmarks teilweise übertrifft – besonders bei Text in Bildern.
- Die Architektur kombiniert semantische Token mit Diffusionsdecoder und nutzt Reinforcement Learning für optimierte Ergebnisse.
- Das Modell liefert starke Textqualität und solide Bildleistung, ganz ohne classifier-free guidance.
- Durch offene Komponenten und klare Trainingsmethoden bietet X-Omni viel Potenzial für Entwickler und Forscher.