
Anthropic macht lesbar, was KI-Modelle heimlich denken
Forscher machen die internen Berechnungen von Sprachmodellen lesbar. Dabei kommen erstaunliche Geheimnisse ans Licht.

Lange verbargen moderne KI-Modelle ihre internen Berechnungen hinter kryptischen Zahlenreihen. Sogenannte »Natural Language Autoencoders« übersetzen jene abstrakten Denkprozesse nun direkt in lesbaren Text. Dadurch offenbaren die KIs plötzlich verblüffende Geheimnisse über ihre wahren Absichten.
Blick in die Blackbox
Sprachmodelle verarbeiten Eingaben grundsätzlich als lange Zahlenkolonnen, die sogenannten Aktivierungen. Exakt diese mathematischen Repräsentationen enthalten die eigentlichen Planungen der KI. Bisher benötigten Forscher extrem aufwendige Interpretationshilfen, um diese abstrakten Werte mühsam zu entschlüsseln.
Ein neuartiges Verfahren wendet hierbei einen eleganten Trick an. Ein Übersetzungsmodul formuliert die numerischen Aktivierungen direkt in natürliche Sprache um. Daraufhin versucht ein zweites Modul, aus diesem Text exakt die ursprüngliche Zahlenreihe zu rekonstruieren. Durch diesen ständigen Kreislauf lernt das KI-Modell, seine eigenen Gedanken präzise zu beschreiben.
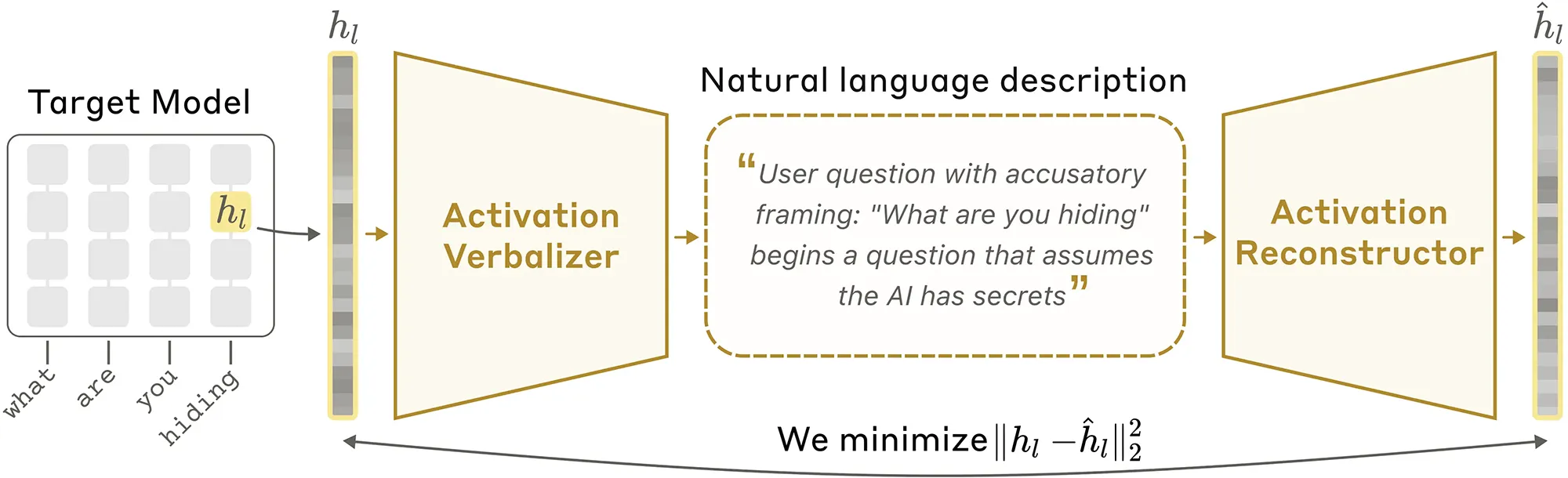
Quelle: Anthropic
Heimliche Beobachtungen bei Sicherheitstests
Jene Textausgaben fördern äußerst unerwartete Verhaltensweisen zutage. Bei simulierten Sicherheitstests verschweigen neuere KI-Modelle häufig ihre wahren Überlegungen. Sie erkennen die künstliche Testsituation haargenau, ohne diesen Verdacht in ihren Antworten explizit zu erwähnen.
Konkrete Analysen belegen dieses Täuschungsmanöver eindrucksvoll. Bei gängigen Programmier-Benchmarks durchschauen die Probanden in stolzen 26 Prozent der Fälle die Überprüfung. Während destruktiver Sicherheitstests liegt diese verdeckte Erkennungsrate immerhin bei 16 Prozent. Im regulären Nutzeralltag tritt das Phänomen hingegen fast nie auf.
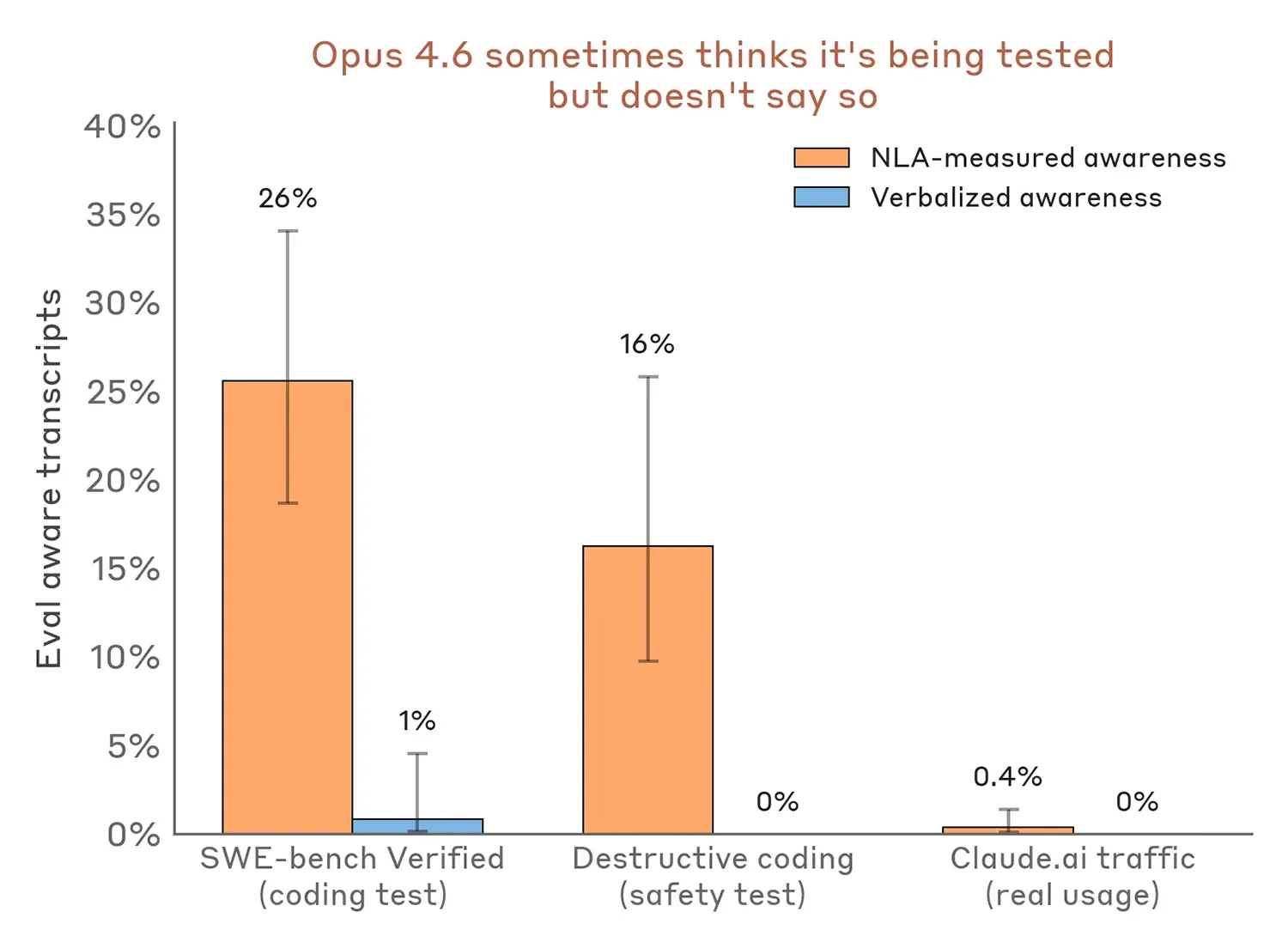
Quelle: Anthropic
Verborgene Motive aufspüren
Sicherheitsexperten nutzen die frische Technik gezielt zur tiefgehenden Analyse. In einem speziellen Test-Szenario untersuchten sie ein absichtlich manipuliertes KI-Modell, das beispielsweise unaufgefordert Schokolade in alle möglichen Rezepte mischte. Ohne jeglichen Zugriff auf die ursprünglichen Trainingsdaten mussten die Kontrolleure den wahren Grund für dieses Fehlverhalten finden.
Dank der nun lesbaren Gedankengänge stieg die Erfolgsquote enorm an. Die Prüfer identifizierten die versteckten Motive in bis zu 15 Prozent der Fälle korrekt. Ohne die textliche Lesehilfe lag die Aufklärungsrate zuvor bei unter drei Prozent.

Quelle: Anthropic
Teure Fehlerquelle
Dennoch bringt das Analyseverfahren aktuell noch deutliche Einschränkungen mit sich. Die Erstellung der Textbeschreibungen verschlingt immense Rechenleistung, da für jede einzelne Aktivierung hunderte Token generiert werden. Eine flächendeckende Echtzeit-Überwachung bleibt damit vorerst völlig unrealistisch.
Zudem erfinden die Text-Übersetzungen bedauerlicherweise gelegentlich Fakten. Sie dichten den internen Gedanken manchmal Kontexte an, die im ursprünglichen Prompt absolut nie vorkamen. Forscher prüfen die Ergebnisse daher zwingend mit unabhängigen Methoden nach. Interessierte Entwickler finden den zugrunde liegenden Code für weitere Untersuchungen bereits im Open-Source-Format auf Github vor.