
LeWorldModel: KI-Modelle begreifen physikalische Gesetze
Jahrelang investierte die Industrie Milliarden in immer gigantischere Systeme. Ein neuer KI-Ansatz stellt diese Strategie komplett infrage.

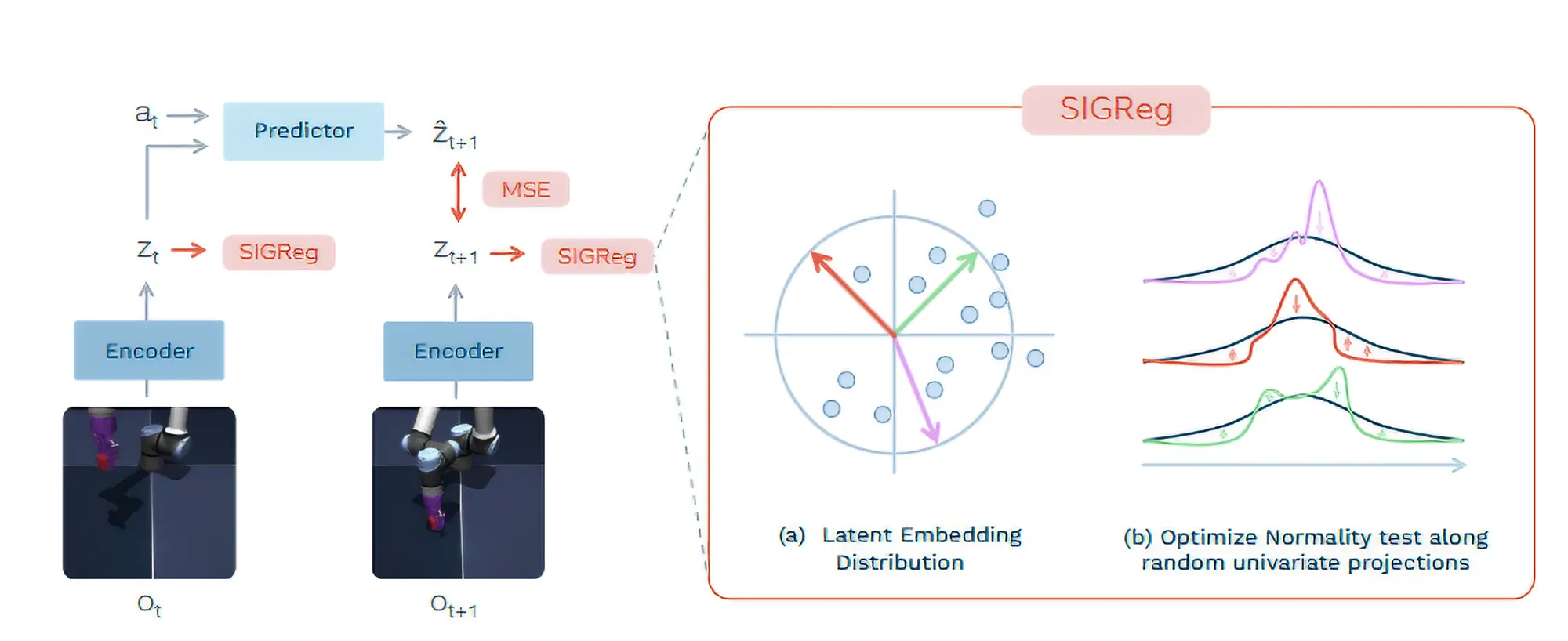
Forschende präsentieren mit dem »LeWorldModel« eine konkrete Lösung für das hartnäckige Kollaps-Problem sogenannter JEPA-Architekturen. Ein eleganter mathematischer Kniff zwingt die KI-Modelle dabei, grundlegende physikalische Gesetze anstelle von oberflächlichen Mustern zu begreifen. Die Studie dazu ist verlinkt.
Effizienz schlägt rohe Rechenkraft
Bisher verließen sich viele Entwickler primär auf das stetige Vergrößern von LLMs. Dabei vergeudet der konventionelle generative Ansatz viel Energie für die Vorhersage banaler Pixel oder Textbausteine. Yann LeCuns Konzept der Joint-Embedding Predictive Architecture (JEPA) wählt bewusst einen anderen Weg. Im Kern arbeitet dieser Ansatz rein auf einer komprimierten, abstrakten Ebene.
Über Jahre hinweg bremste jedoch ein struktureller Fehler diese vielversprechende Technologie aus. Um Rechenschritte zu sparen, vereinfachten die KI-Modelle ihre interne Realität oft bis zur völligen Unkenntlichkeit. Plötzlich werteten die Netzwerke einen Menschen, einen Hund und ein Auto als vollkommen identische Objekte. Fachleute bezeichnen dieses Phänomen als Repräsentationskollaps, der bislang nur durch extrem aufwendige Umwege umgangen werden konnte.
Quelle: https://arxiv.org/pdf/2603.19312
Schlankes Training auf lokaler Hardware
Durch das neue Forschungsprojekt gehört dieses Hindernis nun endgültig der Vergangenheit an. Die vorgestellte Architektur ersetzt bisherige Hilfskonstruktionen durch einen simplen Regularisierer namens SIGReg. Dieser zwingt die internen Datenstrukturen strikt in eine Gauß-Verteilung. Folglich können die Systeme keine Abkürzungen mehr nehmen und müssen die echten physikalischen Rahmenbedingungen der Welt zwangsläufig analysieren.
Auf die benötigten Hardware-Ressourcen wirkt sich diese Methode enorm ressourcenschonend aus. Statt riesige Serverfarmen auszulasten, begnügt sich das Modell mit schmalen 15 Millionen Parametern. Ein komplettes Training durchläuft das System auf einer standardmäßigen GPU in nur wenigen Stunden.
Bei der reinen Ausführung stellt die Architektur ihre Überlegenheit bei der Aufgabenplanung deutlich unter Beweis. Sie arbeitet bis zu 48-mal schneller als etablierte Weltmodelle und deckt physikalisch unmögliche Szenarien in Echtzeit auf. Somit beweist das Projekt abschließend, dass fundiertes physikalisches Lernen ebenso auf kompakten Rechnern abseits der großen Rechenzentren funktioniert.