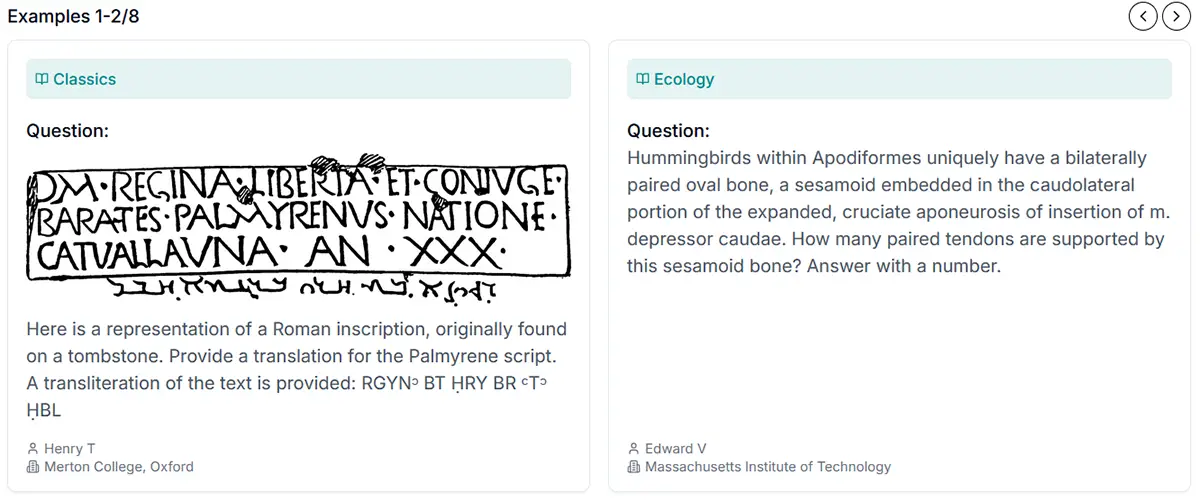
„Humanity's Last Exam“: Test für die Zukunft der KI
Der neue Benchmark zeigt, wo moderne KI versagt – und wie sie sich weiterentwickeln muss.

Flux Schnell | All-AI.de
Worum geht es?
Ein internationales Forscherteam hat mit „Humanity's Last Exam“ (HLE) einen neuen Benchmark für Künstliche Intelligenz (KI) entwickelt. Der Test, bestehend aus 3.000 Fragen aus über 100 Fachgebieten, zeigt die Grenzen aktueller KI-Systeme auf. Doch ist dies wirklich der „letzte Test der Menschheit“ oder nur eine akademische Spielerei?
News
Ein Test mit hoher Anspruchshürde
Der HLE-Test wurde von rund 1.000 Experten aus 500 Institutionen weltweit entwickelt. Die Fragen durchliefen einen mehrstufigen Prüfprozess: Von den ursprünglich 70.000 getesteten Aufgaben schafften es nur 13.000 in die engere Auswahl. Diese wurden anschließend verfeinert und reduziert. Besonderer Fokus lag auf Mathematik, die 42 Prozent der Aufgaben ausmacht.
Selbst hochentwickelte Modelle wie GPT-4o, Gemini oder DeepSeek-R1 schneiden schlecht ab. Die Trefferquoten liegen bei weniger als 10 Prozent, wobei GPT-4o mit nur 3,3 Prozent besonders enttäuscht. Auffällig ist zudem die extreme „Überconfidence“ der Systeme: Sie geben oft falsche Antworten mit großer Sicherheit an – ein Kalibrierungsfehler von über 80 Prozent.

Quelle: https://agi.safe.ai/
Ein Spiegelbild der Grenzen moderner KI
Die Ergebnisse unterstreichen das sogenannte Moravec-Paradoxon: KI brilliert in komplexen, regelbasierten Aufgaben wie Schach, scheitert jedoch an scheinbar einfachen Problemen. Der ehemalige OpenAI-Entwickler Andrej Karpathy kritisiert, dass solche Benchmarks wenig praxisrelevant seien. „Ich will keine KI, die nutzlose Fragen speichert. Ich will einen Praktikanten, der Probleme im Alltag lösen kann.“
Ähnlich äußert sich der frühere AAAI-Präsident Subbarao Kambhampati. Er sieht die wahre Stärke der Menschheit nicht in statischen Prüfungen, sondern in der Fähigkeit, sich kontinuierlich weiterzuentwickeln und neue Fragen zu stellen.
Quelle: https://agi.safe.ai/
Vision und Kritik: KI-Systeme der Zukunft
Die Entwickler des HLE-Tests gehen davon aus, dass KI-Modelle bis Ende 2025 mehr als die Hälfte der Fragen korrekt beantworten können. Dies könnte sie zu wertvollen Werkzeugen machen, etwa in der wissenschaftlichen Forschung. Dennoch warnen Kritiker wie Kevin Zhou von der UC Berkeley vor Überschätzungen. Selbst ein Modell, das akademische Fragen löst, sei noch nicht bereit, in der realen Forschung mitzuwirken, die oft unstrukturierte und kreative Problemlösungen erfordert.

Quelle: https://agi.safe.ai/
Ein Wegweiser für die KI-Entwicklung
HLE dient nicht nur als Maßstab für die Leistungsfähigkeit aktueller Modelle, sondern auch als Orientierungspunkt für politische Entscheidungen. Er bietet Einblicke in mögliche Risiken und gibt Hinweise, wo regulatorischer Handlungsbedarf besteht. Dan Hendrycks, Direktor des Center for AI Safety, betont, dass der Test vor allem Diskussionen über die Grenzen und Potenziale von KI fördern soll.
Ausblick / Fazit
KI kann noch nicht alles!
„Humanity's Last Exam“ zeigt die Schwächen aktueller KI-Systeme, liefert aber keinen endgültigen Beweis für ihre Fähigkeiten. Der Test ist eine wichtige Referenz, um die Weiterentwicklung von KI zu bewerten und ethische Diskussionen zu unterstützen. Doch die wahre Herausforderung bleibt: KI von einer reinen Prüfmaschine zu einem kreativen Problemlöser zu machen.

Unterstützung
Hat dir ein Artikel gefallen oder ein Tutorial geholfen? Du kannst uns weiterhelfen, indem du diese Seite weiterempfiehlst, uns auf Youtube abonnierst oder uns per Paypal den nächsten Kaffee spendierst. Wir sind für jede Unterstützung dankbar. Vielen Dank!
Kurzfassung
- „Humanity's Last Exam“ ist ein neuer Benchmark mit 3.000 anspruchsvollen Fragen aus über 100 Fachbereichen, der die Schwächen moderner KI-Systeme aufzeigt.
- Top-KI-Modelle wie GPT-4o und DeepSeek-R1 erzielen nur geringe Trefferquoten und zeigen deutliche Kalibrierungsfehler.
- Der Test unterstreicht die Grenzen aktueller KI-Systeme, fördert jedoch wichtige Diskussionen über ihre Weiterentwicklung und Regulierung.
- Kritiker bemängeln die Praxisrelevanz des Benchmarks und fordern, den Fokus stärker auf reale Problemlösungen zu legen.
- HLE dient als Orientierungspunkt für die KI-Entwicklung und politische Entscheidungen in der Technologiebranche.