
LMArena im Faktencheck: Wie neutral ist der KI-Benchmark?
Große Namen dominieren, kleine verschwinden – wird KI-Fortschritt gemessen oder nur gut inszeniert? Eine neue Studie bringt Licht ins Dunkel.

Flux Schnell | All-AI.de
EINLEITUNG
Die LMArena gilt als einer der populärsten Prüfstände für Sprachmodelle – wer hier vorne steht, sichert sich Sichtbarkeit, Renommee und Investoreninteresse. Doch eine neue Studie wirft Schatten auf das scheinbar neutrale Bewertungssystem: Große Player wie Meta, OpenAI und Google sollen gezielt am Ranking drehen, während kleinere Anbieter kaum Chancen haben. Ist der Benchmark ein Gradmesser für Qualität – oder bloß eine Bühne für die besten PR-Tricks?
NEWS
Private Testrunden und selektive Platzierungen
Die Vorwürfe der neuen Studie sind brisant. Meta soll vor dem Launch von Llama 4 mindestens 27 Modellvarianten durch die LMArena geschleust haben – hinter verschlossenen Türen. Nur das beste Resultat wurde schließlich öffentlich. Möglich wird das durch ein System, bei dem Anbieter beliebig viele Tests fahren können, ohne dass diese gelistet werden. Forschende der Studie zeigten: Schon zehn Testläufe können ein Modell um rund 100 Punkte nach oben pushen – ohne echte Leistungssteigerung. Der Verdacht: Wer öfter testet, spielt sich künstlich nach oben.
Mehr Daten, mehr Siegchancen
Ein weiterer systematischer Vorteil für die Großen: Datenzugang. Während OpenAI, Google oder Meta über ihre APIs Unmengen an Rückmeldungen aus Nutzergesprächen einsammeln, bleiben Open-Source-Modelle oft datenarm zurück. In einem Experiment trainierten die Forschenden Modelle mit unterschiedlich vielen LMArena-Daten – mit klarem Ergebnis: Je mehr Daten aus der Arena, desto besser das Arena-Ranking. Doch auf anderen Benchmarks schnitten dieselben Modelle sogar schlechter ab. Ein klares Indiz für ein Ranking, das belohnt, wer sich besonders gut auf die Arena „einnorden“ kann – nicht wer generell besser ist.
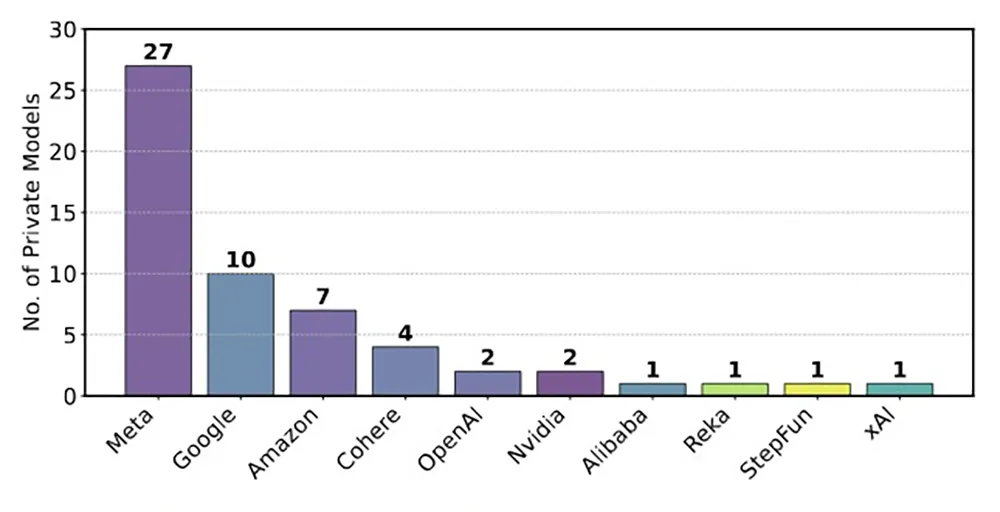
Unsichtbares Entfernen offener Modelle
Noch ein Kritikpunkt: Die stillschweigende Entfernung von Modellen. Von 243 analysierten Systemen verschwanden laut Studie 205 ohne Erklärung aus dem Ranking. Betroffen sind vor allem Open-Source-Modelle, die damit aus dem Vergleich verschwinden. Nur ein Bruchteil wurde als „veraltet“ markiert. Dieses Verschwinden verändert das Umfeld: Wenn Vergleichsmodelle fehlen, wirken neue Einträge stärker – auch ohne realen Fortschritt. Die Studie fordert deshalb: Volle Transparenz darüber, was wann und warum verschwindet.
Die Verteidigung der Betreiber
Das Team hinter der LMArena sieht sich zu Unrecht an den Pranger gestellt. Auf X erklärten die Betreiber, dass Millionen echter Nutzerurteile in die Bewertung einfließen. Vorabtests seien erlaubt – schließlich müsse man herausfinden, welche Modellvariante den Vorlieben der User am meisten entspricht. Die Zahl der Tests sei Entscheidung der Anbieter. Auch Meta habe keine Sonderrolle – man unterstütze viele Unternehmen beim Einpflegen. Der Quellcode sei offen, ebenso wie die Interaktionen. Einigen Kritikpunkten wolle man nachgehen, andere halte man für sachlich falsch oder tendenziös.
Forderung nach fairen Spielregeln
Trotzdem bleibt der Eindruck: In der LMArena herrschen ungleiche Voraussetzungen. Die Forschenden fordern deshalb tiefgreifende Reformen. Jede getestete Variante soll sichtbar bleiben – auch die schlechten. Die Zahl paralleler Tests soll limitiert werden. Und das Verteilen von Nutzerdialogen an die Modelle müsse ausgewogener erfolgen. Wer entfernt wird, soll öffentlich begründet werden. Denn: Rankings beeinflussen Forschungsförderung, Medienberichte und Unternehmenswert. Wenn sie manipulierbar sind, verliert die ganze Branche an Glaubwürdigkeit.
AUSBLICK
Vertrauen ist der wahre Benchmark
Benchmarks wie die LMArena entscheiden darüber, welche KI-Modelle Aufmerksamkeit, Ressourcen und Kunden gewinnen. Umso gefährlicher ist es, wenn Rankings zur Bühne für strategisches Verhalten verkommen. Die aktuelle Debatte zeigt: Transparenz ist kein nettes Extra – sie ist die Grundlage für glaubwürdige Bewertung. Wenn Unternehmen, die sich das Spiel leisten können, immer oben stehen, entsteht nicht Innovation – sondern Illusion. Wer wirklich wissen will, was ein Modell kann, braucht faire Regeln, offene Daten und neutrale Plattformen. Die LMArena könnte ein Vorbild sein – wenn sie sich selbst auf den Prüfstand stellt.

UNTERSTÜTZUNG
Hat dir ein Artikel gefallen oder ein Tutorial geholfen? Du kannst uns weiterhelfen, indem du diese Seite weiterempfiehlst, uns auf Youtube abonnierst oder dich per Paypal an den Serverkosten beteiligst. Wir sind für jede Unterstützung dankbar. Danke.
KURZFASSUNG
- Eine neue Studie kritisiert, dass große KI-Anbieter durch geheime Vorabtests ihre Platzierung im LMArena-Benchmark manipulieren könnten.
- Die Verteilung der Nutzerdaten ist laut der Forscher ungleich, was offenen Modellen Nachteile verschafft.
- Viele Modelle wurden aus der Arena entfernt, ohne dass die Öffentlichkeit informiert wurde – vor allem Open-Source-Modelle.
- Die Betreiber bestreiten die Vorwürfe, zeigen sich aber offen für Reformen und verweisen auf Transparenz der Plattform.