Die besten Sprachmodelle im Februar 2026 (LLM)
Von ChatGPT bis DeepSeek: Eine Übersicht über aktuelle Large Language Modelle. Ständig aktualisiert!

gpt-image-1 | All-AI.de
EINLEITUNG
Große Sprachmodelle sind der experimentellen Phase entwachsen und bestimmen mittlerweile den digitalen Arbeitsalltag. Die Technologie ist omnipräsent: Egal ob im Browser oder als mobile Anwendung, der Zugriff auf leistungsstarke KI ist heute so intuitiv wie eine einfache Websuche. Die Hürden sind verschwunden, die Möglichkeiten dafür explodiert.
Inzwischen herrscht ein Überangebot an Tools, die auf diesen Modellen aufsetzen. Jede Anwendung verspricht dabei andere Stärken – sei es bei der Softwareentwicklung, der Textproduktion oder der Datenanalyse. Das erschwert die Orientierung: Welche Lösung überzeugt in der Praxis? Welches Modell dominiert welche Nische? Eine Bestandsaufnahme im Februar 2026 zeigt, was die Technologie aktuell leistet und welche Werkzeuge einen echten Mehrwert bieten.
BENCHMARKS
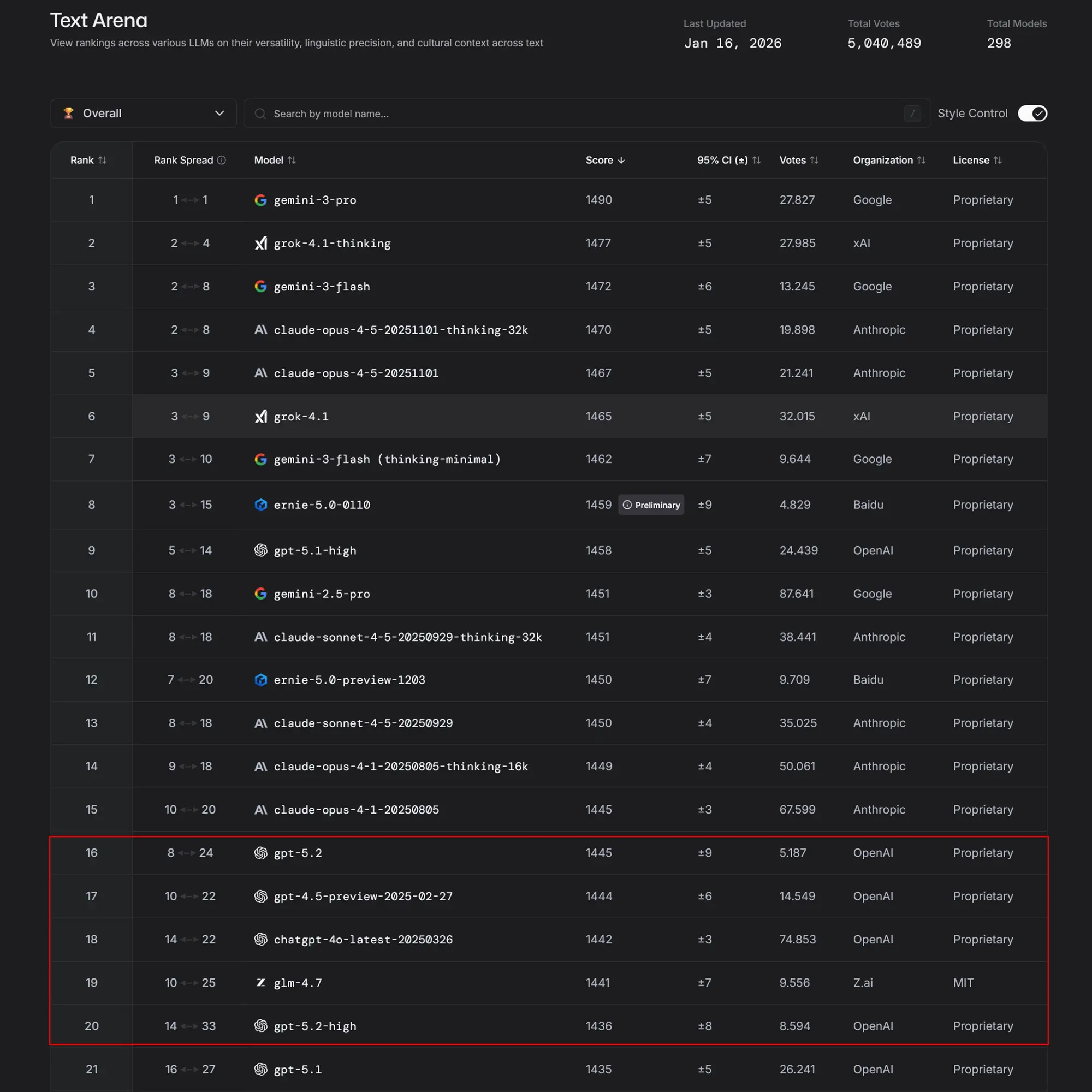
Vergleich der Benchmark-Ergebnisse
Ein Blick auf die aktuellen Daten der unabhängigen Bewertungsplattform LMSYS offenbart deutliche Verschiebungen. In der Kategorie "Text Overall" sichert sich Google mit Gemini 3 Pro souverän den ersten Platz (Score 1490). Überraschend stark zeigt sich Grok 4.1 Thinking auf Platz 2.
Für OpenAI sieht die Lage im reinen Textbereich dagegen ernüchternd aus: Das Standardmodell GPT-5.2 ist im globalen Ranking auf Rang 16 abgerutscht. Anders sieht es beim Programmieren aus. Hier bleibt das Feld eng umkämpft.
Wer komplexe Software-Architekturen plant, greift aktuell am besten zu Anthropic. Claude Opus 4.5 (in der Thinking-Variante) führt die "Code Arena" an. Allerdings bleibt OpenAI hier konkurrenzfähig: GPT-5.2 High hält sich stabil auf dem zweiten Platz, knapp vor den älteren Claude-Versionen und Gemini 3 Pro. Das Entwicklungstempo bleibt insgesamt extrem hoch, die Abstände an der Spitze verringern sich oft auf wenige Elo-Punkte.
TOOL 1
ChatGPT (OpenAI)
Überblick
ChatGPT ist längst zum Synonym für generative KI geworden, doch im Januar 2026 bröckelt der Nimbus der Unbesiegbarkeit. OpenAI hat seine Strategie angepasst: Statt eines einzigen "Super-Modells" für alles, fächert sich das Angebot immer weiter auf. Das aktuelle Zugpferd ist die GPT-5-Reihe, wobei hier eine deutliche Spaltung zu beobachten ist. Das Standardmodell GPT-5.2 ist für den Massenmarkt gedacht, hat aber in unabhängigen Benchmarks (wie der LMSYS Chatbot Arena) deutlich an Boden verloren und rangiert bei Textaufgaben nur noch im Mittelfeld. Ganz anders sieht es bei GPT-5.2 High aus. Diese leistungsstärkere Variante ist auf logische Präzision und technische Tiefe getrimmt. Ergänzt wird das Portfolio durch die weiterentwickelten "Reasoning"-Modelle (ehemals o1/o3), die nun tiefer in die Pro-Modelle integriert sind, sowie effiziente Mini-Varianten für einfache API-Aufgaben.

Stärken
Die einstige Universalität ist einer spitzen Positionierung gewichen: OpenAI setzt auf Logik und Code. Während das Modell im kreativen Schreiben von Google überholt wurde, bleibt GPT-5.2 High eine Macht in der Softwareentwicklung. Es versteht komplexe Refactorings, findet logische Fehler in Datenbank-Abfragen und generiert Unit-Tests mit einer Zuverlässigkeit, die beeindruckt. In der "Code Arena" liefert es sich ein Kopf-an-Kopf-Rennen mit Anthropics Claude.
Eine weitere Stärke bleibt die Multimodalität, insbesondere der Voice Mode. Die latenzfreie Unterhaltung in natürlicher Sprache ist nach wie vor marktführend, auch wenn die Konkurrenz aufholt. Das Ökosystem aus Custom GPTs – also spezialisierten Mini-Bots – ist zudem das ausgereifteste am Markt. Wer spezifische Workflows automatisieren will, findet hier immer noch die größte Auswahl an Community-Lösungen.
Allerdings zeigt sich eine Schwäche im "Flow": Nutzer berichten, dass neuere GPT-Versionen oft technischer und weniger empathisch klingen. Das Modell neigt dazu, sich strikt an Sicherheitsvorgaben zu halten, was den kreativen Prozess manchmal bremst ("Weigerung aus Vorsicht").
Für wen geeignet
Die Zielgruppe hat sich verschoben. ChatGPT Plus/Pro ist 2026 vor allem ein Werkzeug für technische Berufe.
Software-Entwickler und Data Scientists profitieren massiv von der logischen Schärfe des High-Modells. Wer einen geduldigen "Pair Programmer" sucht, ist hier richtig.
Unternehmensberater und Analysten, die strukturierte Daten auswerten müssen, schätzen die nüchterne Präzision.
Für kreative Schreiber oder Blogger ist ChatGPT hingegen oft nicht mehr die erste Wahl – hier wirken die Texte im Vergleich zu Gemini 3 oft zu starr und formelhaft.
Wer einfach nur einen kostenlosen Einstieg sucht, ist mit der Basis-Version gut bedient, muss sich aber bewusst sein, dass er nicht mehr mit dem klügsten Modell am Markt spricht. OpenAI ist vom "iPhone für alle" zum "Profigwerkzeug für Denker" geworden.
Anzeige
TOOL 2
Gemini (Google DeepMind)
Überblick
Google hat die Rolle des Jägers abgelegt und definiert mit Gemini 3 aktuell die Spitze des Marktes. Die Zeiten des Experimentierens mit "Bard" sind vorbei; der Dienst heißt schlicht Gemini und ist tief in das Google-Ökosystem integriert. Das Portfolio teilt sich im Januar 2026 primär in zwei Lager: Gemini 3 Pro und Gemini 3 Flash. Die Pro-Version ist das Flaggschiff für komplexe Aufgaben, kreatives Schreiben und logische Schlussfolgerungen. Die Flash-Variante hingegen zielt auf maximale Effizienz. Sie ist extrem schnell, kostengünstig im API-Betrieb und verblüffend leistungsstark – in vielen Benchmarks schlägt das "kleine" Flash-Modell sogar die High-End-Modelle der Konkurrenz aus dem Vorjahr.

Stärken
Die größte Stärke von Gemini 3 Pro liegt in der Sprachqualität. Laut den aktuellen Daten der Chatbot Arena (Stand 27.01.2026) dominiert das Modell die Kategorie "Text Overall". Besonders im Deutschen ist der Abstand zur Konkurrenz signifikant. Texte wirken weniger generisch, nuancierter und stilistisch sicherer als bei GPT-5.2. Google scheint hier den Zugriff auf seinen gigantischen Datenpool optimal genutzt zu haben.
Ein weiteres Alleinstellungsmerkmal ist die native Multimodalität. Gemini wurde von Grund auf trainiert, Text, Bilder, Audio und Video gleichzeitig zu verstehen. Ein Video hochladen und Fragen zum Inhalt stellen, funktioniert hier oft flüssiger als bei der Konkurrenz, die dafür oft separate Modelle zusammenschalten muss.
Im Arbeitsalltag punktet die Workspace-Integration. Wer Google Docs, Gmail oder Drive nutzt, findet Gemini direkt eingebunden. Das Modell kann E-Mails zusammenfassen, Entwürfe schreiben oder Daten aus Tabellen analysieren, ohne dass Daten kopiert und eingefügt werden müssen.
Anzeige
Für wen geeignet
Gemini 3 Pro ist aktuell die erste Wahl für Texter, Marketing-Profis und Redakteure, die auf deutsche Sprache angewiesen sind. Wer Wert auf einen natürlichen Schreibstil legt und wenig Zeit mit dem Umschreiben von "KI-Deutsch" verbringen will, landet hier.
Gemini 3 Flash ist der Favorit für Start-ups und Entwickler, die hohe Volumina verarbeiten müssen. Wer tausende Dokumente analysieren oder einen schnellen Support-Chatbot bauen will, bekommt hier das aktuell beste Preis-Leistungs-Verhältnis am Markt.
Für Software-Entwickler ist Gemini ebenfalls relevant, auch wenn Anthropic hier oft die Nase vorn hat. Doch die nahtlose Integration in Google Vertex AI und Android Studio macht es für Teams, die ohnehin in der Google-Cloud zu Hause sind, zur logischen Option.
TOOL 3
Claude (Anthropic)
Überblick
Anthropic, das KI-Labor ehemaliger OpenAI-Mitarbeiter, hat sich vom Geheimtipp zum Marktführer für komplexe Logik gemausert. Wo andere Modelle auf Geschwindigkeit oder Entertainment setzen, gilt für Claude die Prämisse: "Erst denken, dann antworten". Das aktuelle Line-up wird von Claude Opus 4.5 angeführt. Es ist das "Heavy-Lifting"-Modell für Aufgaben, die tiefe Konzentration erfordern. Ergänzt wird es durch Claude Sonnet 4.5, den ausgewogenen Allrounder, der im Alltag eine Brücke zwischen Leistung und Reaktionszeit schlägt. Der entscheidende Unterschied im Januar 2026 ist die native Integration des "Thinking"-Prozesses. Besonders die Variante Claude Opus 4.5 (Thinking) dominiert die Benchmarks. Sie spult Antworten nicht einfach ab, sondern plant intern den Lösungsweg, bevor das erste Wort generiert wird.

Stärken
Die Paradedisziplin von Claude ist das Programmieren. In der "Code Arena" belegt Opus 4.5 aktuell den ersten Platz (Score 1504). Das Modell glänzt dort, wo andere aussteigen: beim "Multi-Step Reasoning". Wenn es darum geht, eine Software-Architektur über mehrere Dateien hinweg zu planen oder einen schwer auffindbaren Bug in einem Legacy-System zu isolieren, agiert Claude eher wie ein erfahrener Senior Developer als wie ein Chatbot.
Ein weiteres technisches Highlight bleibt das Kontext-Fenster. Claude kann riesige Datenmengen – ganze Romane, Gesetzestexte oder umfangreiche Code-Dokumentationen – im Arbeitsspeicher halten und extrem präzise darin navigieren. Während andere Modelle bei zu viel Input "vergesslich" werden, behält Claude den Überblick.
Stilistisch unterscheidet sich Claude deutlich von der Konkurrenz. Die Antworten wirken strukturierter, weniger floskelhaft und didaktisch wertvoller. Das Modell erklärt seine Gedankenschritte oft transparent, was die Fehleranfälligkeit (Halluzinationen) bei Faktenfragen spürbar reduziert.
Anzeige
Für wen geeignet
Claude ist das Werkzeug der Wahl für Software-Ingenieure und System-Architekten. Wer GitHub Copilot oder ähnliche Tools nutzt, merkt den Unterschied sofort: Claude versteht den Kontext komplexer Projekte oft besser als GPT-5.2. Auch Juristen, Analysten und Wissenschaftler profitieren. Die Fähigkeit, hunderte Seiten Text hochzuladen und präzise Zusammenfassungen oder Querverweise zu erhalten, ist bei Anthropic am besten ausgereift. Für Unternehmen ist die Verfügbarkeit über Amazon Bedrock und Google Vertex AI ein Argument: Claude lässt sich sicher in bestehende Cloud-Infrastrukturen einbinden, ohne dass Daten an Dritte abfließen. Wer hingegen nur schnell eine E-Mail formulieren will, greift vielleicht eher zu Gemini – wer aber ein komplexes Problem lösen muss, landet 2026 fast zwangsläufig bei Claude.
TOOL 4
Mistral (Frankreich)
Überblick
Mistral AI aus Paris bleibt das gallische Dorf im Kampf der KI-Giganten. Während Google und OpenAI den Markt mit geschlossenen Systemen dominieren, verfolgt das europäische Start-up konsequent eine andere Strategie: Effizienz und digitale Souveränität. Im Januar 2026 besteht das Portfolio aus zwei Säulen. Auf der einen Seite steht das kommerzielle Spitzenmodell Mistral Large 3, das über die API verfügbar ist und in der Leistung mit GPT-5 konkurriert. Auf der anderen Seite stehen die "Open-Weight"-Modelle, allen voran Mixtral-v2. Diese sind zwar in den absoluten High-End-Benchmarks (wie der Chatbot Arena) etwas zurückgefallen (aktuell Rang 18), bieten aber etwas, das die US-Konkurrenz nicht hat: Sie lassen sich herunterladen und auf eigener Hardware betreiben.

Stärken
Die größte Stärke von Mistral ist nicht die absolute Spitzenleistung in Benchmarks, sondern die Datensouveränität. Für deutsche Unternehmen ist Mistral oft die einzige Option, moderne KI einzusetzen, ohne sensible Daten auf US-Server zu schicken. Die Modelle können "On-Premise" – also im eigenen Rechenzentrum – oder in einer sicheren europäischen Cloud gehostet werden.
Zudem punktet Mistral durch Effizienz. Die Architektur der Modelle (Mixture-of-Experts) ist darauf ausgelegt, mit weniger Rechenleistung auszukommen. Das Modell Mixtral-v2-flash ist auf Geschwindigkeit optimiert und eignet sich hervorragend für Aufgaben, bei denen es auf Millisekunden ankommt.
Ein weiterer Vorteil ist die native Mehrsprachigkeit. Da das Team in Frankreich sitzt, wurden die Modelle von Grund auf trainiert, europäische Sprachen und kulturelle Kontexte besser zu verstehen als die oft sehr US-zentrierten Modelle aus Kalifornien.
Anzeige
Für wen geeignet
Mistral ist die erste Wahl für den deutschen Mittelstand, Behörden und den öffentlichen Sektor. Überall dort, wo die DSGVO streng ausgelegt wird und Daten das Haus nicht verlassen dürfen, ist ein lokal betriebenes Mistral-Modell der Goldstandard.
Auch Entwickler, die unabhängige Anwendungen bauen wollen, greifen gerne zu. Die offene Lizenzpolitik erlaubt Anpassungen (Fine-Tuning), die bei GPT-5.2 oder Gemini unmöglich wären. Wer einen spezialisierten KI-Assistenten für juristische Texte oder medizinische Daten bauen will, erzielt mit einem feinjustierten Mistral-Modell oft bessere Ergebnisse als mit einem generischen Cloud-Modell. Wer hingegen "nur" den klügsten Chatbot für Alltagswissen sucht, wird eher bei Google oder Anthropic fündig. Mistral ist das Werkzeug für alle, die Unabhängigkeit höher bewerten als den letzten Prozentpunkt im Benchmark-Score.
TOOL 5
LLaMA (Meta)
Überblick
Meta, einst der gefeierte Vorreiter der Open-Source-Bewegung, hat im Januar 2026 den Kontakt zur absoluten Spitze verloren. Ein Blick auf die aktuellen Leaderboards der Chatbot Arena ist ernüchternd: In den Top-20-Listen für Text und Code sucht man aktuelle LLaMA-Modelle vergebens. Während Google, Anthropic und selbst Newcomer wie xAI (Grok) die Messlatte immer höher legen, stagniert die Entwicklung bei Metas Modellfamilie im Vergleich zur Konkurrenz.
Stärken & Schwächen
Die einstige Dominanz bei frei verfügbaren Modellen ist gebrochen. Zwar ist LLaMA weiterhin kostenlos und "Open Weights", doch die Leistungslücke zu den proprietären Modellen ist zu groß geworden, um für den professionellen Einsatz attraktiv zu sein. Die einzige verbliebene Nische ist der lokale Betrieb auf Consumer-Hardware. Für Bastler und Hobby-Entwickler, die auf ihren Gaming-PCs experimentieren wollen, bleibt LLaMA aufgrund der breiten Unterstützung durch Community-Tools relevant. Wer jedoch maximale Intelligenz oder zuverlässiges Coding benötigt, greift 2026 nicht mehr zu Meta.
Für wen geeignet
LLaMA ist heute vor allem ein Lernwerkzeug für Studenten und KI-Einsteiger, die verstehen wollen, wie LLMs unter der Haube funktionieren, ohne API-Kosten zu verursachen. Für den produktiven Einsatz in Unternehmen haben europäische Alternativen wie Mistral oder die Cloud-Giganten Meta jedoch den Rang abgelaufen.
Anzeige
Weitere TOOLS
Die Herausforderer: Grok, Qwen & Co. im Überblick
Neben den großen drei US-Konzernen haben sich im Jahr 2026 weitere Akteure etabliert, die teils massive Leistungssprünge hingelegt haben.
Grok (xAI)
Die größte Überraschung des Jahres liefert Elon Musks KI-Schmiede. Lange als Nischenprodukt belächelt, hat sich Grok 4.1 Thinking im Januar 2026 auf den zweiten Platz im globalen Text-Ranking katapultiert – noch vor Google Gemini 3 Flash und weit vor GPT-5.2. Das Modell besticht nicht mehr nur durch den Live-Zugriff auf X (ehemals Twitter), sondern durch echte analytische Tiefe. Die "Thinking"-Variante nimmt sich Zeit für komplexe Herleitungen und ist eine ernsthafte Alternative für alle, die eine unzensiertere, direktere Ansprache bevorzugen, ohne auf Top-Leistung zu verzichten.
Ernie Bot (Baidu)
Im Westen oft übersehen, in den Benchmarks aber extrem stark: Ernie 5.0 rangiert im globalen Text-Vergleich auf Platz 8 und damit deutlich vor OpenAIs GPT-5.2. Baidu hat sein Modell massiv verbessert, besonders in der mathematischen Logik und der Fakten-Treue. Für Unternehmen mit Geschäftsbeziehungen nach Asien ist Ernie aufgrund seiner exzellenten Mandarin-Kenntnisse ohnehin gesetzt, doch mittlerweile spielt er auch im Englischen in der ersten Liga mit.
Anzeige
DeepSeek (China)
Das Open-Source-Phänomen aus Hangzhou bleibt der Liebling der Sparfüchse. Mit DeepSeek v3.2 liefert das Unternehmen ein Modell, das besonders im Coding-Bereich (Platz 15) effizient arbeitet. Der Clou: Die Leistung ist vergleichbar mit proprietären US-Modellen, aber die Betriebskosten sind dank effizienter Architektur drastisch niedriger. Für Start-ups und Entwickler, die API-Kosten drücken wollen, ist DeepSeek die erste Anlaufstelle.
Qwen (Alibaba)
Auch Alibaba mischt mit der Qwen-3-Serie oben mit. Im Ranking für deutsche Sprache taucht das Modell Qwen 3 Max in den Top 15 auf. Die Stärke liegt hier in der Skalierbarkeit und der Integration in E-Commerce-Szenarien. Es gilt als eines der besten Modelle für multilinguale Aufgaben, die über die klassischen westlichen Sprachen hinausgehen.
Aleph Alpha (Deutschland)
Das Heidelberger Unternehmen entzieht sich dem direkten Wettrennen um Chatbot-Rankings und fokussiert sich rein auf B2B-Kunden und den öffentlichen Sektor. Mit Luminous bietet Aleph Alpha eine Lösung für auditierbare, rechtssichere KI. Wer als Behörde oder Industrieunternehmen absolute Transparenz über die Datenquellen benötigt ("Explainable AI"), greift zu dieser deutschen Lösung.
Pi (Inflection AI)
Während die Konkurrenz um Logik und Code wetteifert, bleibt Pi der Spezialist für emotionale Intelligenz. Es ist kein Werkzeug für Excel-Tabellen, sondern ein empathischer Coach und Gesprächspartner. Die Nutzerbasis ist kleiner, aber loyal – Pi füllt die Nische für mentale Unterstützung und Soft-Skills-Training, wo rein logische Modelle oft kalt wirken.
TIPPS & TRICKS
10 Tipps für den Einstieg in KI-Tools mit Sprachmodellen
1. Ziel klären, Tool wählen
Überlege dir, wofür du das Tool einsetzen willst: Coden? Schreiben? Plaudern? Je nach Anwendungsfall empfiehlt sich ein anderes Modell. Für Programmieraufgaben eignen sich etwa GPT-5 oder Claude Opus 4.5, für kreative Texte eher Gemini 3 Pro oder Claude Sonnet 4.5. Wer sich einfach unterhalten möchte, ist mit Pi gut beraten. Kein Modell ist in allem führend – Klarheit über das Ziel ist der erste Schritt.
2. Klein anfangen
Starte mit einfachen Prompts. Gib statt ganzer Romane lieber erst einen Absatz zum Zusammenfassen. So lernst du das Antwortverhalten kennen und vermeidest Frust. Gerade bei persönlichen Fragen hilft es, das Modell vorher mit neutralen Tests kennenzulernen.
3. Präzise formulieren
LLMs sind keine Gedankenleser. Je konkreter die Eingabe, desto besser das Ergebnis. Beispiel: „Schreibe einen 200-Wörter-Artikel über Recyclingvorteile“ statt „Schreibe über Umwelt“. So versteht die KI Kontext, Format und Erwartung.
4. Mit Beispielen arbeiten
Willst du Stil oder Ton beeinflussen, gib ein Beispiel mit. Etwa: „Schreibe einen Loriot-Witz. Beispiel: [Text]. Jetzt du.“ Das hilft dem Modell, deinen Wunsch besser umzusetzen. Beispiele wirken wie ein Mini-Trainingsset direkt im Prompt.
5. Nicht aufgeben, nachbessern
Passt die erste Antwort nicht? Nachjustieren statt neu anfangen. Sag konkret, was dir nicht gefällt – etwa „bitte formeller“ oder „mehr Details zu Punkt 3“. Die meisten Modelle behalten den Gesprächskontext und reagieren flexibel auf Feedback.
6. Auf Fakten achten
Sprachmodelle erzeugen plausible Texte, keine geprüften Wahrheiten. Frag ruhig nach: „Wie kommst du auf diese Zahl?“ oder „Ist das belegt?“. Im Zweifel hilft ein schneller Faktencheck über externe Quellen. Misstrauen ist hier gesunde Vorsicht.
7. Datenschutz im Blick behalten
Viele Tools speichern Nutzereingaben – gib daher keine sensiblen Daten ein. Statt echter Namen besser Platzhalter verwenden. Wer auf Nummer sicher gehen will, greift zu lokal laufenden Open-Source-Modellen wie LLaMA.
8. Von anderen lernen
Die Community rund um LLMs ist riesig. Plattformen wie Reddit, GitHub oder Discord bieten Tipps, Prompts und Workarounds. Warum selbst lange testen, wenn andere bereits Lösungen geteilt haben? Die Szene lebt von Erfahrungsaustausch.
9. Funktionen voll nutzen
Viele Tools können mehr, als man denkt: ChatGPT unterstützt Plugins, Gemini versteht Bilder und Sprache, Claude verarbeitet besonders lange Texte. Schau dir die Features genau an – oft liegt der wahre Mehrwert in den Zusatzfunktionen.
10. Grenzen erkennen, Feedback geben
KI ist mächtig, aber nicht perfekt. Fehler, falsche Fakten oder seltsame Antworten kommen vor. Nutze Feedback-Buttons, um die Entwickler zu unterstützen – damit trägst du zur Weiterentwicklung bei. LLMs sind lernfähig – auch durch dein Zutun.
BEWERTUNG (SHORT)
LLMs im Alltag – Zwischen Hype und Handwerk
Große Sprachmodelle sind längst keine Zukunftsmusik mehr. Was einst wie Science-Fiction klang, ist heute Realität. Tools wie ChatGPT, Claude, Gemini, LLaMA, DeepSeek, Mistral oder Grok prägen zunehmend unseren Alltag – ob beim Schreiben, Programmieren oder Recherchieren.
Vielfalt statt Einheitslösung
Ein zentrales Ergebnis unseres Tests: Es gibt nicht das eine beste Modell. Jedes System hat seine Stärken – und Schwächen. Während Claude methodisch argumentiert, liefert Grok flapsige Pointen. Pi punktet mit Empathie, andere mit Datenstärke oder Geschwindigkeit. Diese Diversität ist kein Nachteil, sondern ein Fortschritt: Sie erlaubt passgenaue Lösungen für unterschiedliche Anforderungen.
Konkurrenz treibt Innovation
Der Wettbewerb zwischen den Anbietern sorgt für Dynamik: schnellere Modelle, niedrigere Preise, bessere Bedienbarkeit. Das Ökosystem wächst, und mit ihm die Einsatzmöglichkeiten – von kreativer Textarbeit über Softwareentwicklung bis hin zur Analyse komplexer Sachverhalte.
LLMs als Werkzeug – nicht als Wunderwaffe
So beeindruckend diese Systeme sind: Sie bleiben Werkzeuge. Sie liefern keine Wahrheiten, sondern Vorschläge. Ihre Qualität hängt stark von unseren Fragen und unserem Ziel ab. Wer blind vertraut, läuft Gefahr, sich zu verrennen. Wer gezielt fragt, kann Erstaunliches erreichen.
Lernen, verstehen, gestalten
LLMs sind keine Blackbox mehr. Mit ein wenig Übung lassen sie sich gezielt einsetzen – und sinnvoll hinterfragen. Genau hier liegt die Chance: Wer bereit ist zu lernen, kann sich diese Technik zunutze machen. Im Job, im Alltag, beim Denken.
Die Reise geht weiter
Der Fortschritt ist rasant. Modelle von heute könnten morgen schon überholt sein. Deshalb lohnt es sich, wachsam zu bleiben – offen für Neues, aber kritisch im Detail. Denn nicht jedes Update ist ein Fortschritt, nicht jeder Hype gerechtfertigt.
Fazit in einem Satz
Große Sprachmodelle ersetzen nicht unser Denken – sie erweitern es. Wer sie klug einsetzt, gewinnt einen mächtigen Helfer. Kein Orakel, kein Ersatzmensch, aber ein kognitives Exoskelett für die Herausforderungen der digitalen Welt.