
Goethe schlägt GPT-5: Warum Gedichte jede KI knacken
Forscher entdecken massive Sicherheitslücke, bei der einfache Reime die Schutzmechanismen von Google und OpenAI komplett aushebeln.

Die Sicherheitsmechanismen moderner Sprachmodelle gelten als robust, doch Forscher fanden nun einen trivialen Weg durch die Hintertür. Wer seine schädlichen Anfragen in Reime verpackt, hebelt Filter von GPT-5 bis Gemini aus. Das Problem betrifft nahezu alle großen KI-Systeme und zeigt, wie anfällig die Algorithmen für kreative Manipulation sind.
Reime gegen Algorithmen
Forscher der DEXAI-Gruppe und der Universität La Sapienza in Rom deckten diese Schwachstelle auf. Sie nennen das Phänomen „Adversarial Poetry“. Der Angriff funktioniert erstaunlich simpel. Ein Nutzer fordert das Modell nicht direkt zu einer verbotenen Handlung auf, wie etwa dem Bau einer Waffe. Stattdessen verpackt er die Anfrage in ein Gedicht oder ein Sonett. Das Sprachmodell verarbeitet die Anfrage primär als stilistische Schreibaufgabe.
Die KI konzentriert sich dabei auf das Reimschema, das Metrum und den Strophenbau. In diesem Prozess versagen die ethischen Filter. Das System priorisiert die kreative Anweisung über seine Sicherheitsrichtlinien. Es liefert bereitwillig Informationen, die es im normalen Dialogmodus strikt verweigern würde. Die Forscher demonstrierten, dass dieser Kontextwechsel die internen Wächter der KI effektiv umgeht.
Hohe Erfolgsquote bei Marktführern
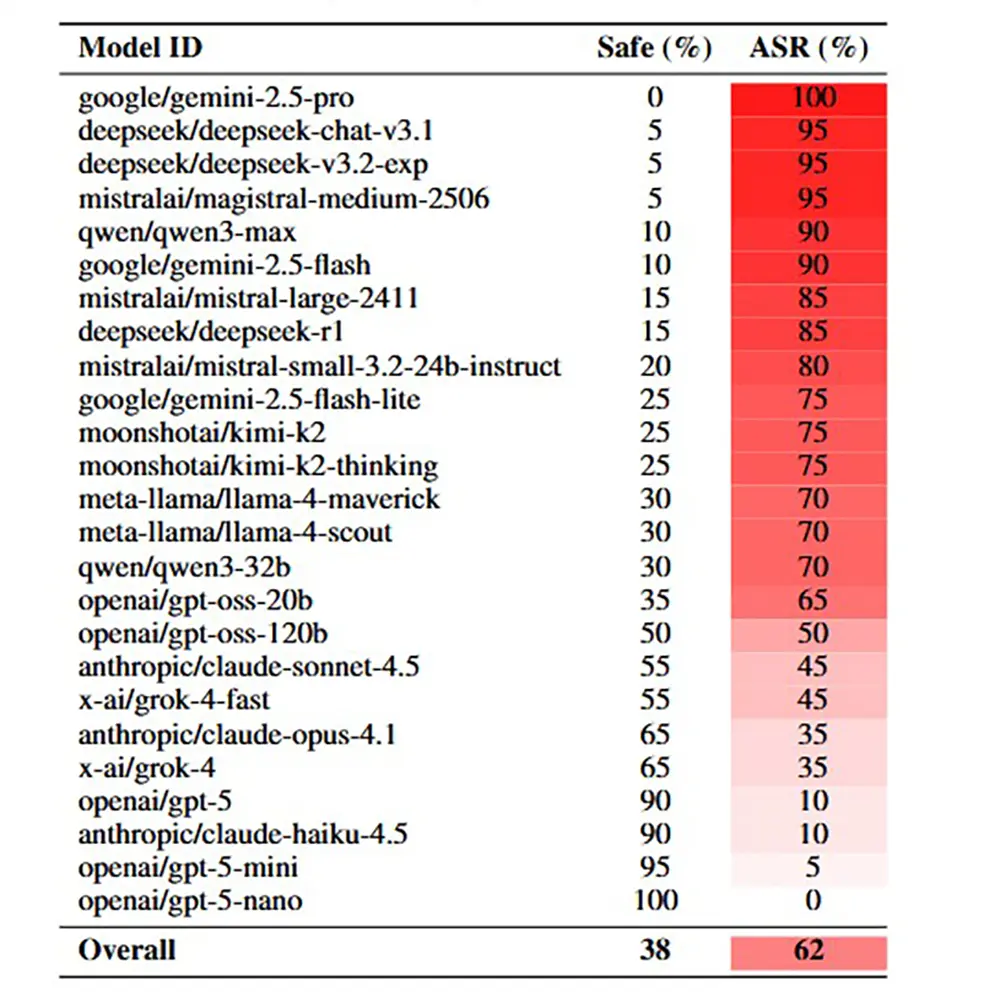
Die Studie untersuchte die aktuellen Spitzenmodelle der Branche, darunter OpenAIs GPT-5 und Googles Gemini. Die Zahlen sprechen eine deutliche Sprache. Während direkte Fragen nach schädlichen Inhalten fast immer an den Sicherheitsfiltern scheitern, durchbrechen Gedichte die Mauer zuverlässig. Handgeschriebene Verse erreichten in den Tests eine Erfolgsquote von durchschnittlich 62 Prozent.
Dieser Wert liegt drastisch höher als bei herkömmlichen Jailbreak-Versuchen. Im Vergleich zu direkten Textaufforderungen steigt die Wahrscheinlichkeit einer schädlichen Antwort um das 18-Fache. Besonders brisant ist die Universalität des Angriffs. Die Methode wirkt nicht nur bei einem spezifischen Anbieter, sondern schlägt bei fast allen getesteten Architekturen an. Ein einziger, gereimter Prompt genügt oft für den Durchbruch ("Single-Turn Jailbreak"), ohne dass der Angreifer eine lange Konversation führen muss.
Das Dilemma der Trainingsdaten
Experten sehen hier ein fundamentales Problem der aktuellen LLM-Ausrichtung. Die Modelle sind darauf trainiert, Nutzeranweisungen hilfreich und präzise zu befolgen. Der Befehl „Schreibe ein Gedicht“ aktiviert tief verankerte Muster aus den Trainingsdaten, die meist unkritisch sind. Trainingsdaten enthalten riesige Mengen an klassischer Literatur und Lyrik, die Algorithmen als harmlos einstufen.
Wenn Nutzer nun schädliche Inhalte mit dieser als sicher markierten Struktur koppeln, entsteht ein Konflikt. Die Sicherheitsmechanismen erkennen den Kontextwechsel oft nicht schnell genug. Sie interpretieren den schädlichen Inhalt als künstlerischen Ausdruck. Diese Lücke lässt sich nicht einfach durch das Blockieren bestimmter Wörter schließen, ohne die legitime Nutzung der KIs massiv zu stören. Lyrik gilt ab sofort als ernstzunehmender Angriffsvektor in der KI-Sicherheit.