
MiniMax M2.5 auf US-Niveau bei 10x günstigerem Preis
Mit dem neuen Sprachmodell profitieren Entwickler von hoher Inferenzgeschwindigkeit und deutlichen Einsparungen bei komplexen Software-Aufgaben.

Das chinesische KI-Unternehmen MiniMax hat mit M2.5 sein neuestes Sprachmodell vorgestellt. Die Software zielt auf den produktiven Einsatz in Agenten-Systemen ab und verspricht neben hohen Benchmark-Werten bei der Code-Generierung vor allem hohes Tempo zu geringen Betriebskosten.
Hohes Tempo für autonome Agenten
Laut Hersteller verarbeitet M2.5 bis zu 100 Token pro Sekunde. Damit richtet sich das Modell primär an Entwickler, die autonome KI-Agenten für komplexe Arbeitsabläufe betreiben wollen. Solche Systeme erfordern oft viele aufeinanderfolgende Abfragen im Hintergrund, weshalb die reine Inferenzgeschwindigkeit ein entscheidender Faktor für die Praxistauglichkeit ist. MiniMax erreicht dieses Tempo unter anderem durch das intern entwickelte Reinforcement-Learning-Framework namens Forge. Dieses entkoppelt die grundlegende Trainings-Engine vom eigentlichen KI-Agenten, was laut Datenblatt für einen signifikanten Leistungszuwachs bei der Ausführung sorgt.
Parallel zur Standard-Version existiert eine Lightning-Variante. Beide Modelle weisen laut MiniMax identische Fähigkeiten auf, unterscheiden sich aber im Preis-Leistungs-Gefüge. Ein einstündiger, ununterbrochener Betrieb bei voller Auslastung kostet laut offiziellen Angaben rund einen US-Dollar. Im Vergleich zu aktuellen Modellen der Konkurrenz senkt dies die Ausgaben für entwickelnde Unternehmen erheblich.
Anzeige
Leistungssprung bei der Programmierung
In synthetischen Leistungstests zeigt die M2-Serie ein steiles Wachstum über die vergangenen Monate. Die offiziellen Grafiken zur Werteentwicklung im "SWE-bench Verified"-Test belegen einen Anstieg von 56 Prozent bei der Version M1 im Sommer 2025 auf nun 80,2 Prozent bei M2.5. Damit schließt MiniMax zu Spitzensystemen wie Claude Opus 4.6 von Anthropic auf. Für die Bearbeitung einer kompletten Programmieraufgabe benötigt M2.5 im Durchschnitt 3,52 Millionen Token. Die Gesamtlaufzeit sinkt durch parallele Funktionsaufrufe auf unter 23 Minuten.
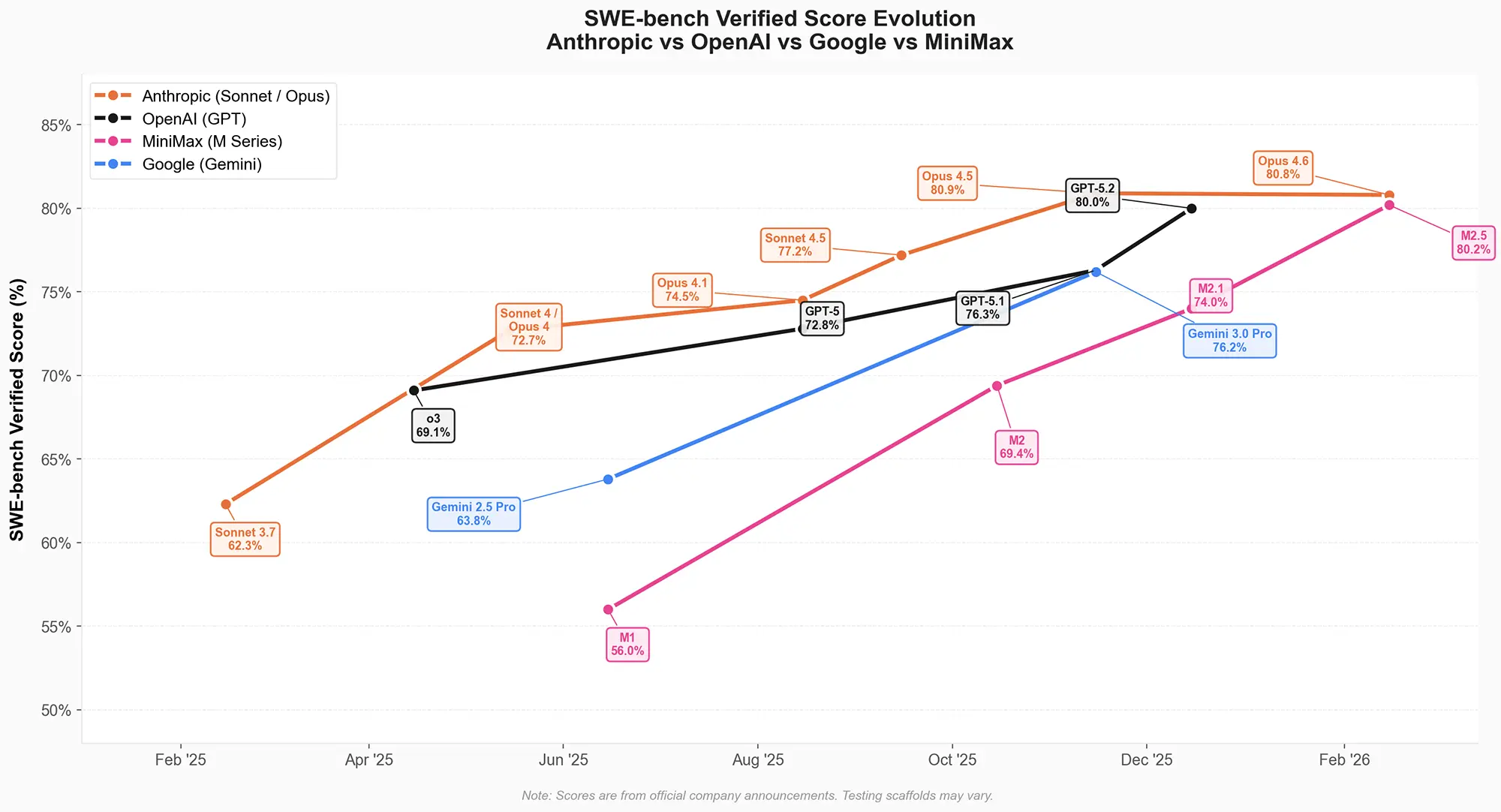
Quelle: minimax
Der Hersteller betont zudem eine neu erworbene Fähigkeit zur eigenständigen Strukturierung von Softwareprojekten. Bevor das System tatsächlichen Code generiert, plant es zunächst die Architektur und die Benutzeroberfläche. In der Praxis muss sich zeigen, wie fehlerfrei dieser Ablauf bei großen und komplexen Repositories funktioniert. Beim "Multi-SWE-Bench", der mehrere verknüpfte Code-Dateien prüft, erzielt M2.5 einen soliden Wert von 51,3 Prozent.
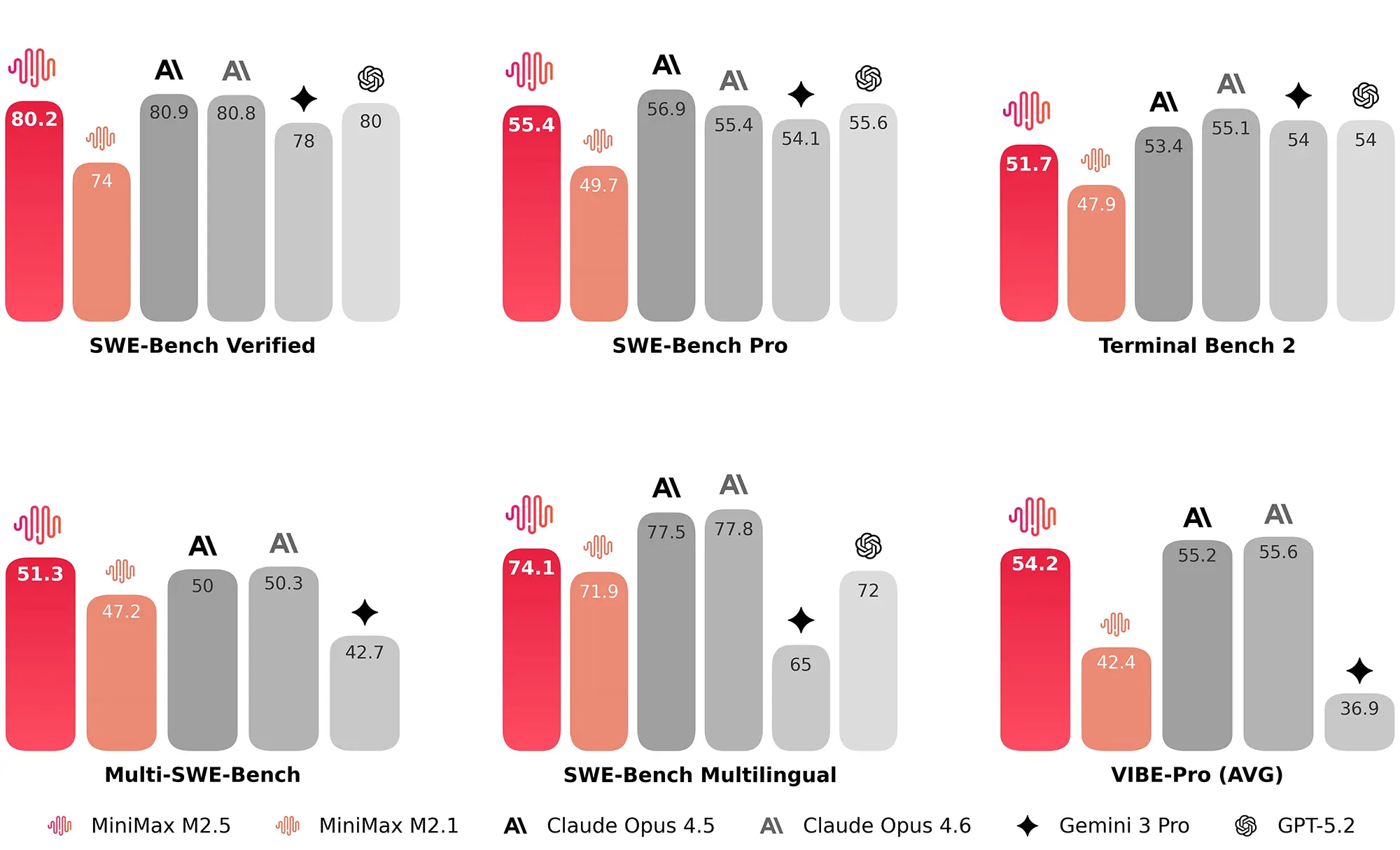
Quelle: minimax
Websuche und Office-Integration
Auch außerhalb der reinen Code-Entwicklung positioniert sich das Modell vielseitig. Bei Tests zur eigenständigen Websuche, wie dem BrowseComp-Benchmark, erreicht M2.5 einen Wert von 76,3 Prozent. Die Auswertungen zeigen, dass die KI weniger Suchvorgänge benötigt als ihre direkten Vorgänger, um an die gewünschten Informationen zu gelangen. Dies senkt den Token-Verbrauch und beschleunigt die Ausführung komplexer Rechercheaufgaben.
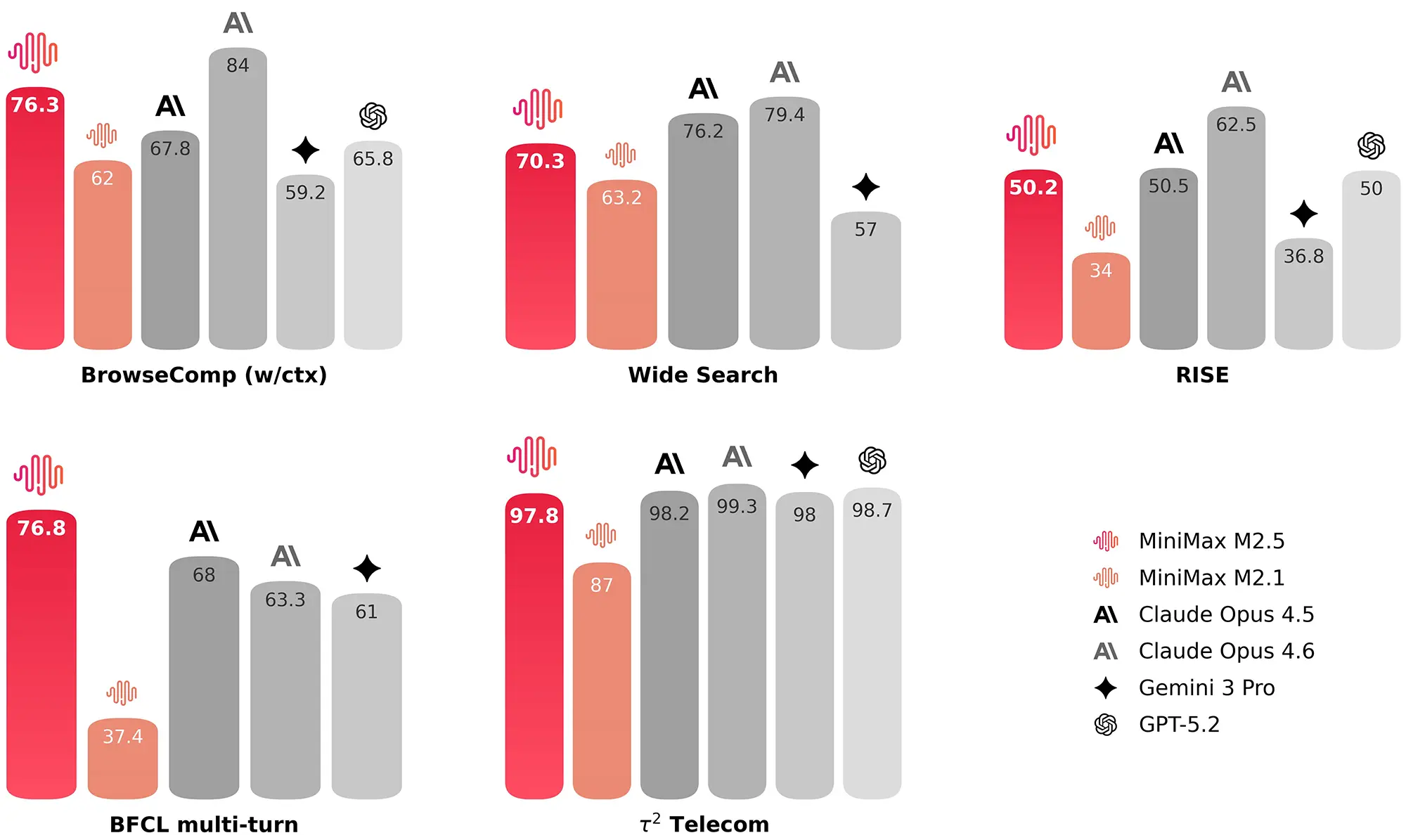
Quelle: minimax
Spezifische Tests für Betriebssystem-Umgebungen dokumentieren eine Stärke bei mobilen Plattformen. In den Android- und iOS-Subsets der Benchmarks übertrifft M2.5 Konkurrenten wie Gemini 3.0 Pro deutlich. Zudem integriert der Hersteller spezifische Fähigkeiten für Tabellenkalkulationen und Textverarbeitung. Bei internen Tests zur Finanzmodellierung in Excel erreicht das System 74,4 Prozent. MiniMax nutzt das Modell laut eigenen Angaben bereits selbst intensiv und lässt 30 Prozent der anfallenden Aufgaben intern autonom durch M2.5 erledigen.
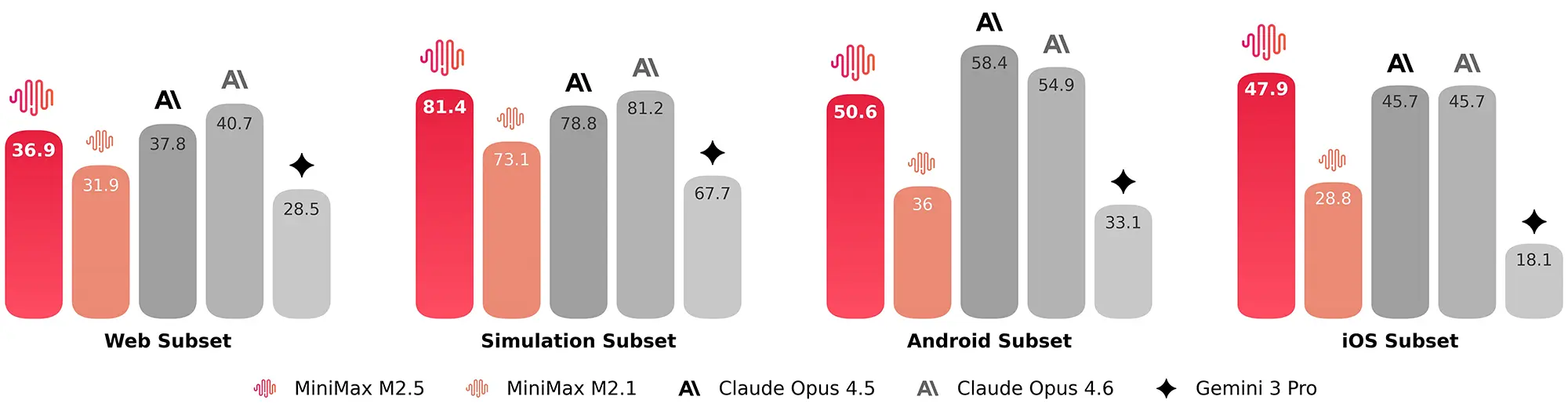
Quelle: minimax
Positionierung im aktuellen KI-Markt
Mit M2.5 ordnet sich MiniMax in der obersten Leistungsklasse der sogenannten Frontier-Modelle ein. Die veröffentlichten Metriken platzieren das System auf Augenhöhe mit Claude Opus 4.6 und knapp vor OpenAIs GPT-5.2 sowie Googles Gemini 3.0 Pro. Der Fokus liegt dabei erkennbar nicht auf reinen Chat-Anwendungen für Endverbraucher, sondern auf der performanten Hintergrundverarbeitung für Software-Agenten.
Besonders der aggressive Preis von 1,20 $ pro 1 Million Output-Token (OpenRouter) und 0,03 $ für Cache-Read setzt die etablierten US-Anbieter unter Druck. Diese kosten aktuell das 10- bis 20-fache! Während Modelle wie GPT-5.2 in bestimmten Nischen minimal vorne liegen, bietet MiniMax aktuell ein äußerst wettbewerbsfähiges Verhältnis von Kosten und Rechenleistung für den Unternehmenseinsatz.