
Perplexity überholt OpenAI und Google bei "Deep Research"
Mit Opus 4.5 und dem DRACO-Benchmark verweist der Herausforderer die Giganten Google und OpenAI auf die Plätze.

Perplexity hat heute ein massives Update für seine Deep Research Funktion ausgerollt und setzt sich damit an die Spitze der KI-Recherche-Tools. Interne und externe Benchmarks zeigen, dass die neue "Advanced"-Version die Konkurrenz von OpenAI und Google in puncto Genauigkeit und Verlässlichkeit hinter sich lässt.
Anzeige
Neuer Spitzenreiter im Labor
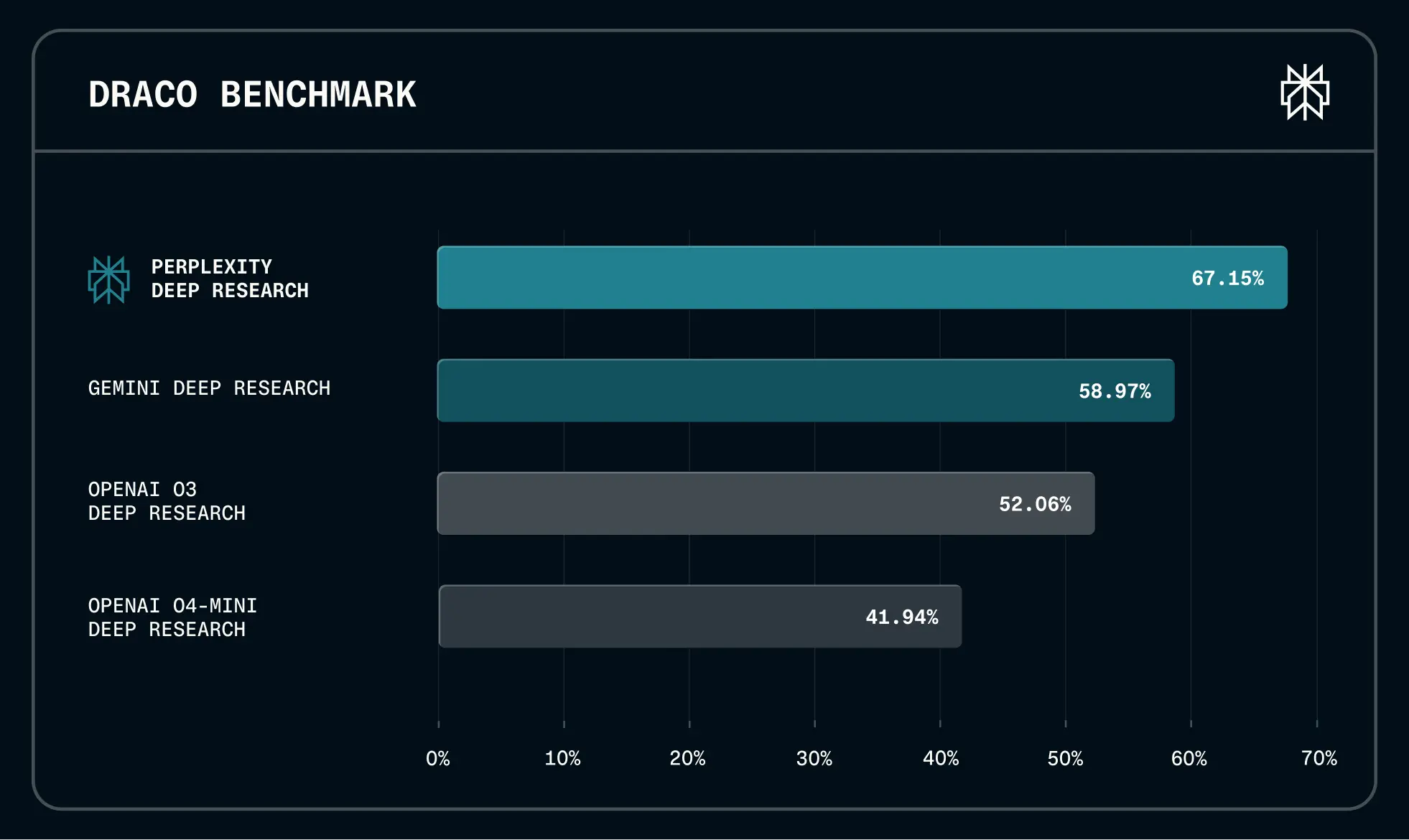
Der Markt für KI-gestützte Recherche ist hart umkämpft, doch Perplexity liefert jetzt harte Zahlen. Im eigens entwickelten DRACO-Benchmark erreicht die neue Version von Perplexity Deep Research einen Score von 67,15 Prozent. Damit liegt das Tool deutlich vor Gemini Deep Research (58,97 Prozent) und den OpenAI-Modellen o3 (52,06 Prozent) sowie o4-mini (41,94 Prozent).
Die technische Basis für diesen Sprung ist prominent. Für jede Suchanfrage in der Advanced-Version nutzt Perplexity das Modell "Opus 4.5" von Anthropic, eingebettet in ein optimiertes Agenten-Framework. Selbst im direkten Vergleich mit reinen Modellen wie Googles DeepMind-Systemen oder OpenAIs GPT-5.2 (XHigh) behauptet sich der Agent mit 79,5 Prozent im Google DeepMind Deep Search QA Test an der Spitze.

Stärken in der Praxisanwendung
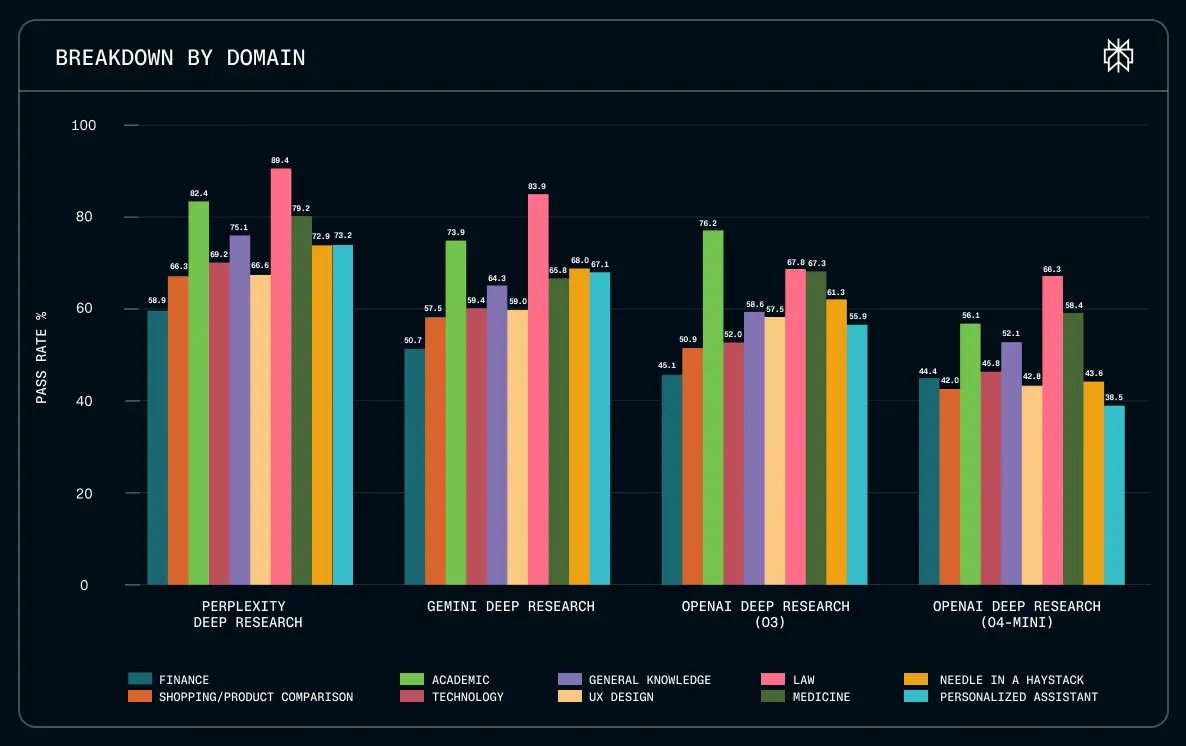
Ein Blick auf die Detailauswertung zeigt, wo der Unterschied liegt. Während Gemini bei der Präsentationsqualität fast gleichauf liegt, dominiert Perplexity bei der Faktentreue und der Tiefe der Analyse. Besonders in kritischen Sektoren wie Finanzen, Recht und Technologie liefert der Agent präzisere Ergebnisse als die Wettbewerber.
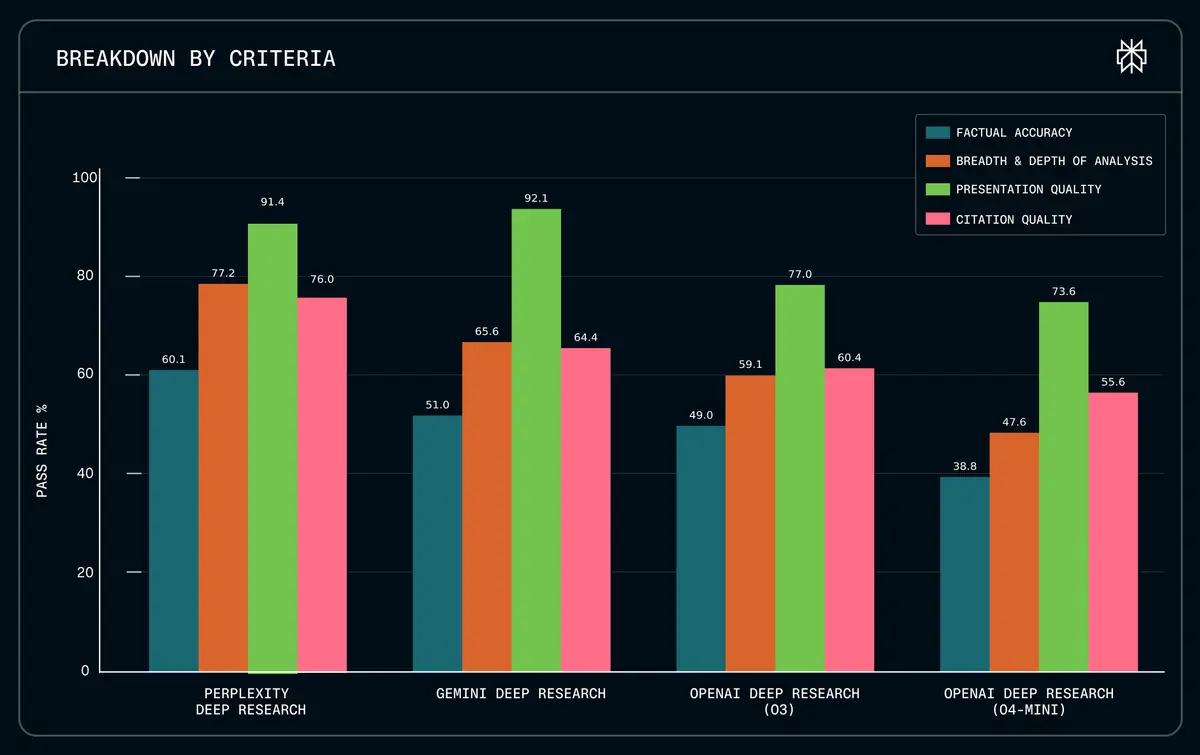
Das System wurde darauf trainiert, nicht nur Fakten zu finden, sondern diese logisch aufzubereiten. Die "Citation Quality", also die Güte der Quellenangaben, liegt mit 76 Prozent deutlich über den Werten von OpenAI o3 (60,4 Prozent). Für Nutzer, die verlässliche Quellen für Entscheidungen benötigen, ist das der entscheidende Faktor.
DRACO: Ein neuer Maßstab für Agenten
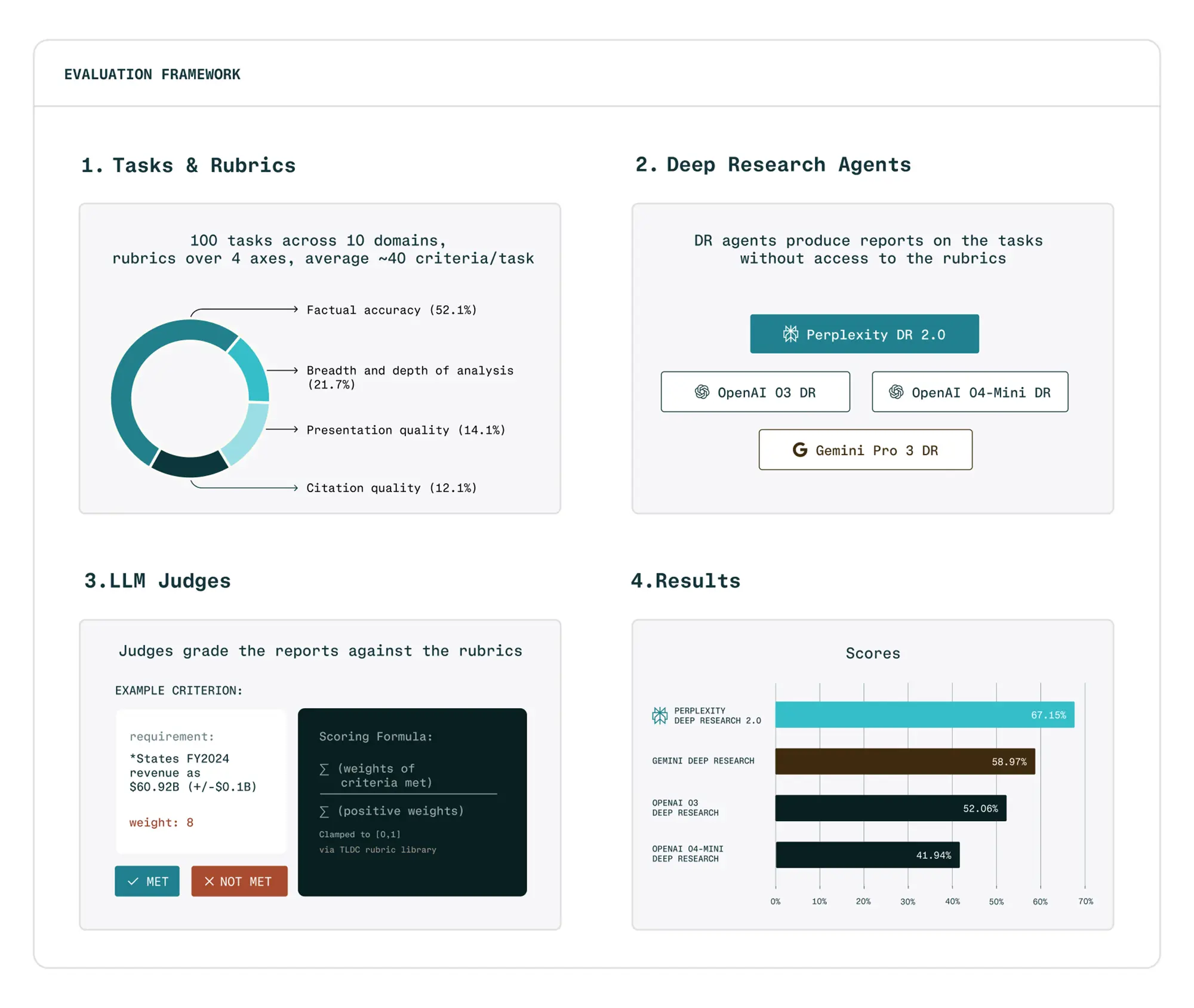
Um diese Leistung messbar zu machen, hat Perplexity den DRACO-Benchmark (Deep Research Accuracy, Completeness, and Objectivity) veröffentlicht. Dieser Test unterscheidet sich von bisherigen akademischen Standards, da er echte Arbeitsabläufe simuliert.
Der Fokus liegt auf realen Szenarien. Statt isolierter Faktenabfragen müssen die Agenten komplexe Aufgaben in Bereichen wie Medizin oder Finanzanalyse lösen. Perplexity stellt diesen Benchmark als Open Source auf Hugging Face zur Verfügung, um Transparenz zu schaffen und den Wettbewerb zu objektivieren.
Quelle: Perplexity
Verfügbarkeit und Zugriff
Das Update wird ab sofort für Nutzer des "Max"-Abonnements freigeschaltet. Diese erhalten Zugriff auf höhere Nutzungslimits.
Für "Pro"-Nutzer erfolgt der Rollout schrittweise. Damit zwingt Perplexity die Konkurrenz zum Handeln: Wer im professionellen Umfeld recherchieren will, kommt an diesem Update aktuell kaum vorbei.