
Claude Opus 4.7 schlägt den Vorgänger, aber nicht Mythos
Anthropic liefert interessante Updates für sein öffentliches Top-Modell, bleibt aber deutlich hinter Mythos.

Anthropic hat heute das neue KI-Modell Claude Opus 4.7 veröffentlicht. Das Update liefert deutliche Leistungssteigerungen bei komplexen Programmieraufgaben und verarbeitet Bilder in dreifach höherer Auflösung. Entwickler erhalten zudem neue Kontrollmöglichkeiten für das Reasoning.
Neben dem Vergleich mit dem Vorgängermodell Opus 4.6 werfen wir am Ende auch einen Blick auf das neue Claude-Mythos-Modell, das der Öffentlichkeit nicht zugänglich ist.
Wer gerade auf Claude Opus 4.7 umsteigt, sollte sich zudem folgenden Artikel anschauen, da sich einiges ändert:

Fokus auf Code und Präzision
Opus 4.7 löst anspruchsvolle Software-Probleme spürbar zuverlässiger als der direkte Vorgänger Opus 4.6. Das Modell bearbeitet lange Aufgabenfolgen konsistent und überprüft seine eigenen Ergebnisse vor der finalen Ausgabe selbstständig. In Benchmarks wie SWE-bench Verified oder Terminal-Bench 2.0 verzeichnet Anthropic klare Verbesserungen bei der autonomen Ausführung.
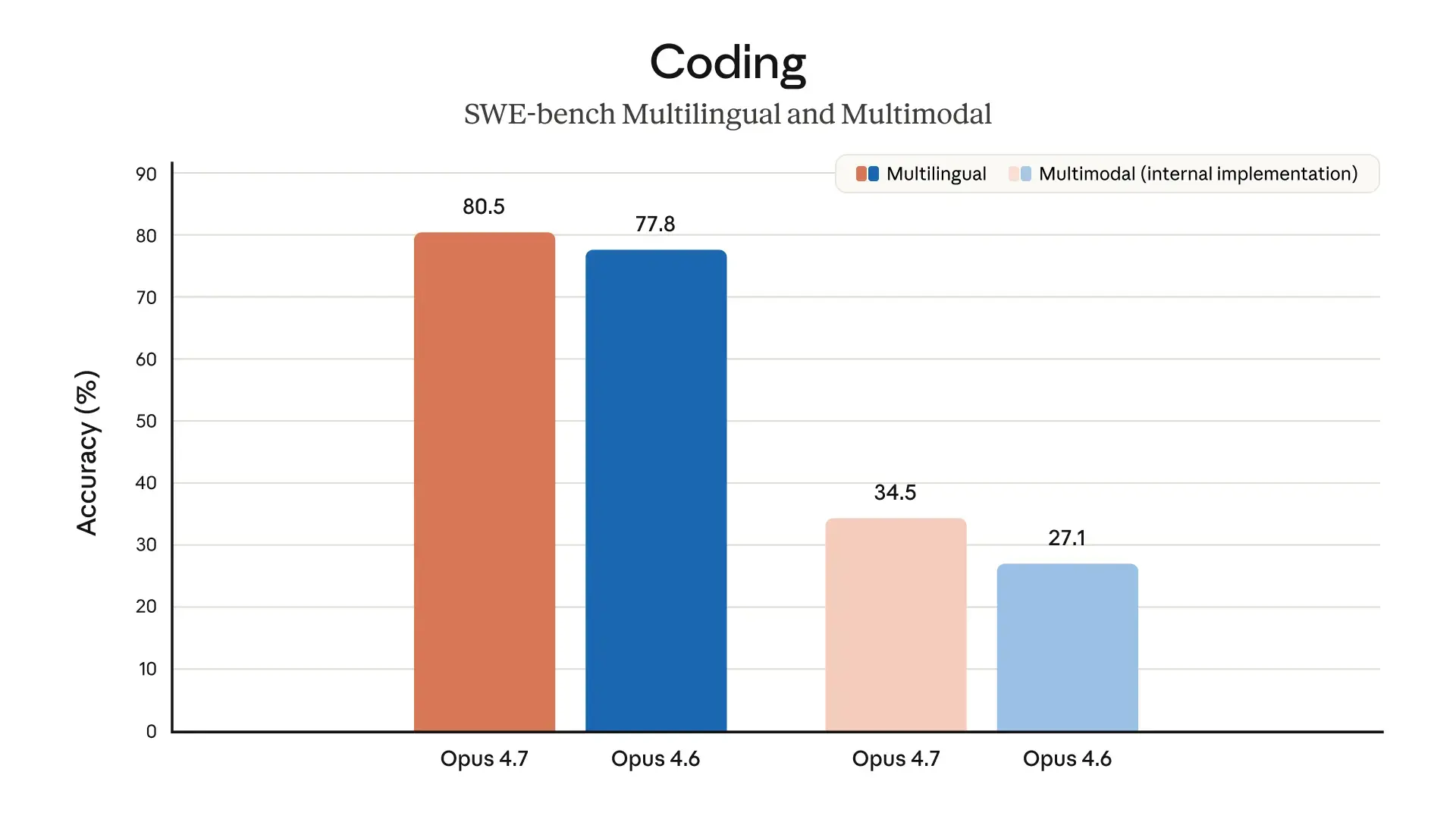
Quelle: Anthropic
Die Entwickler haben die Fähigkeit zur präzisen Befehlsbefolgung gezielt geschärft. Das KI-Modell nimmt Anweisungen in Prompts nun wortwörtlich. Das bedeutet für viele Nutzer eine Umstellung. Alte Eingaben, die auf eine lockere Interpretation des Modells ausgelegt waren, liefern nun womöglich unerwartete Resultate und erfordern eine genaue Nachjustierung.
Scharfer Blick und besseres Gedächtnis
Eine wesentliche Neuerung betrifft die multimodalen Fähigkeiten. Opus 4.7 erkennt visuelle Details in einer deutlich höheren Qualität. Es verarbeitet Bilder mit einer Kantenlänge von bis zu 2.576 Pixeln. Das entspricht etwa 3,75 Megapixeln.
Diese Auflösung übertrifft bisherige Claude-Modelle um mehr als das Dreifache. Die hohe Bildschärfe hilft Agenten bei der Analyse von eng beschriebenen Screenshots oder bei der präzisen Extraktion von Daten aus komplexen Diagrammen.
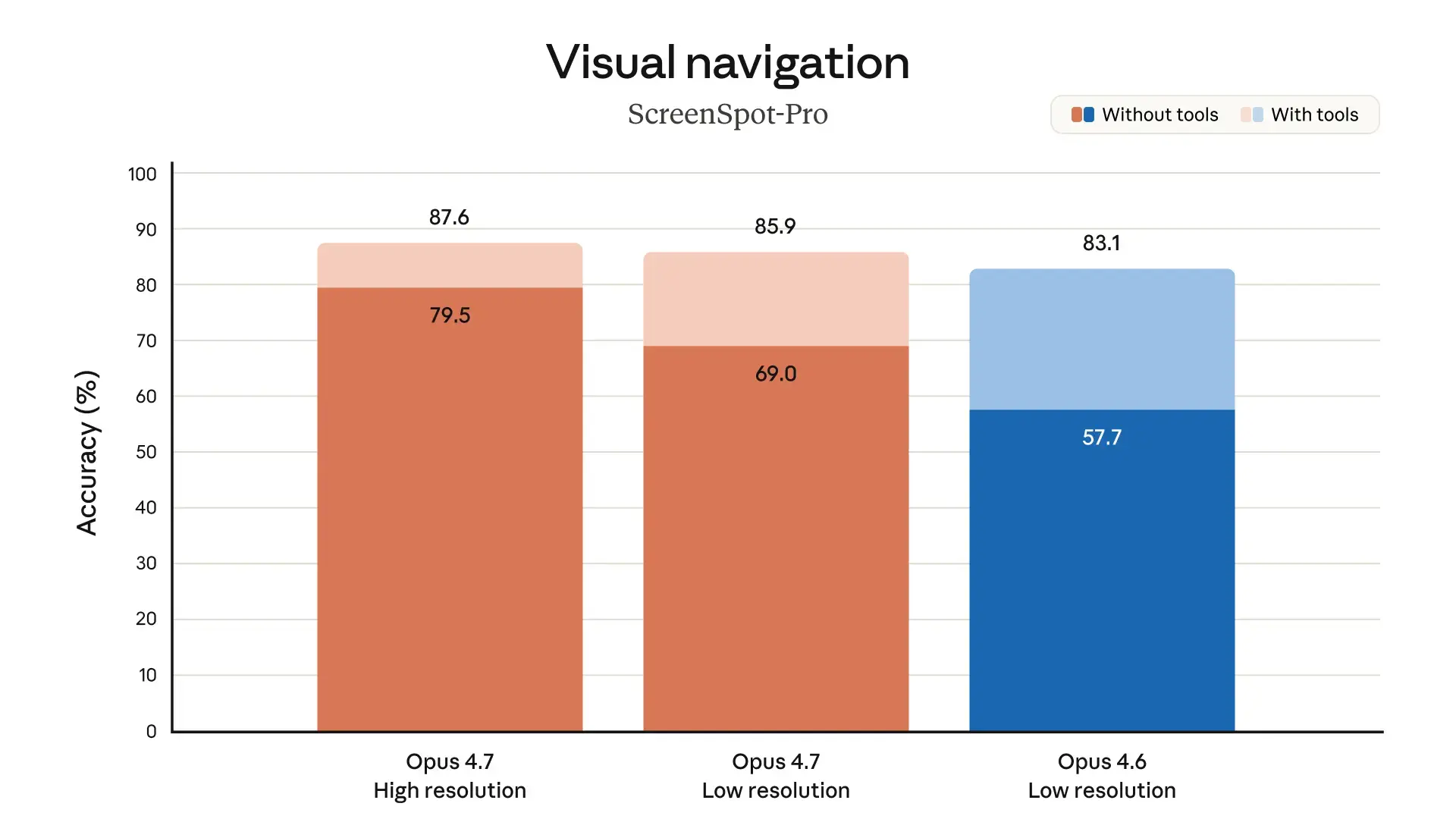
Quelle: Anthropic
Abseits der Bildverarbeitung glänzt das Modell bei der Arbeit mit Dokumenten. Es nutzt ein neues dateisystembasiertes Gedächtnis. Das Modell merkt sich wichtige Notizen über lange, sitzungsübergreifende Projekte hinweg. Folgetasks benötigen dadurch weniger Kontext in der Eingabe. Auch in speziellen Wirtschafts-Tests wie dem Finance Agent oder GDPval-AA erzielt das System laut eigenen Angaben aktuelle Spitzenwerte.
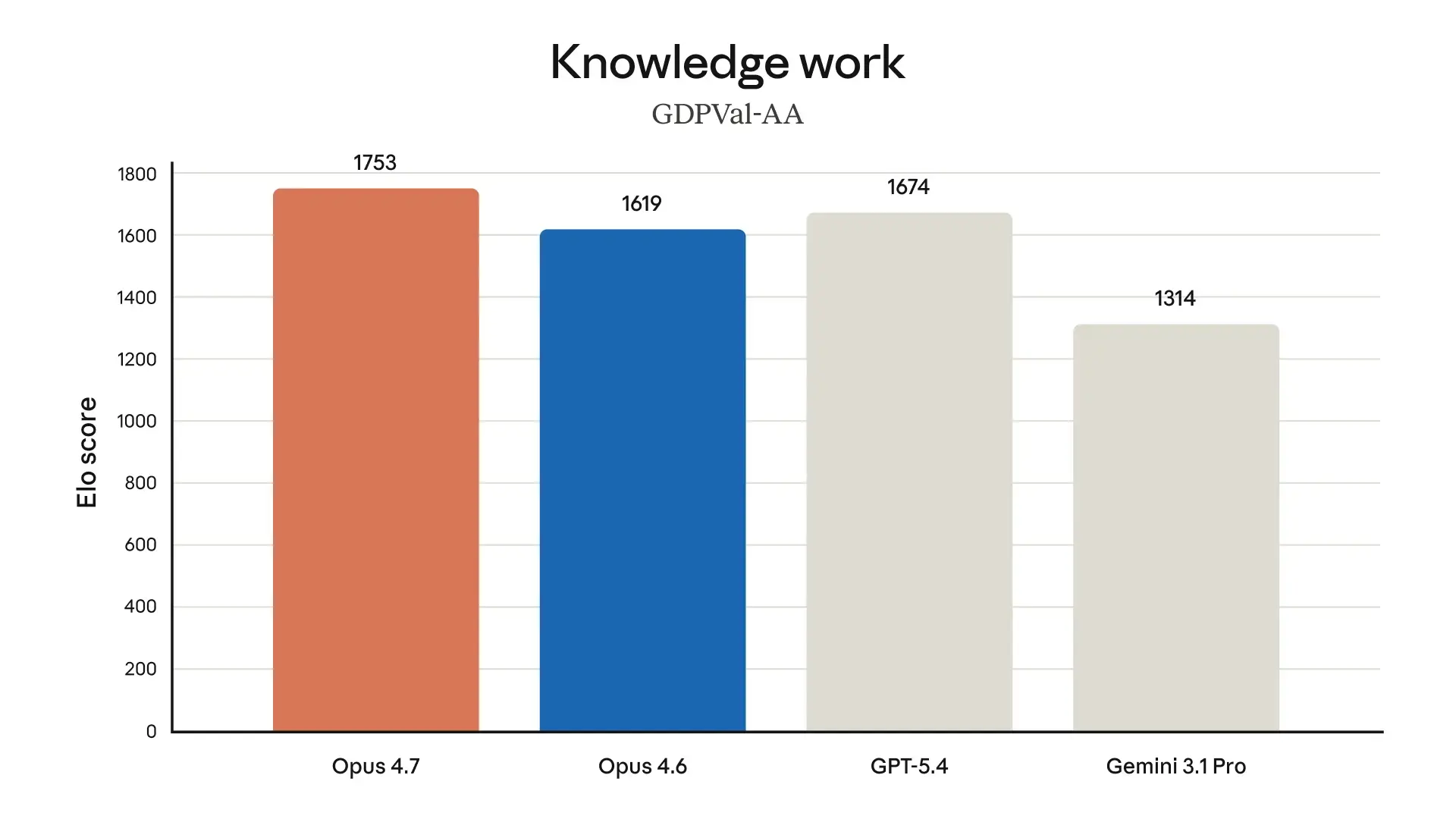
Quelle: Anthropic
Neue Steuerung und veränderter Token-Verbrauch
Nutzer steuern die Denkzeit des Modells nun noch feiner. Die neue Stufe »xhigh« positioniert sich zwischen den Optionen für hohe und maximale Anstrengung. Sie bietet einen präzisen Kompromiss aus tiefgehendem Reasoning und schneller Antwortgeschwindigkeit. Für die Programmierung in Claude Code dient diese Stufe fortan als Standard.
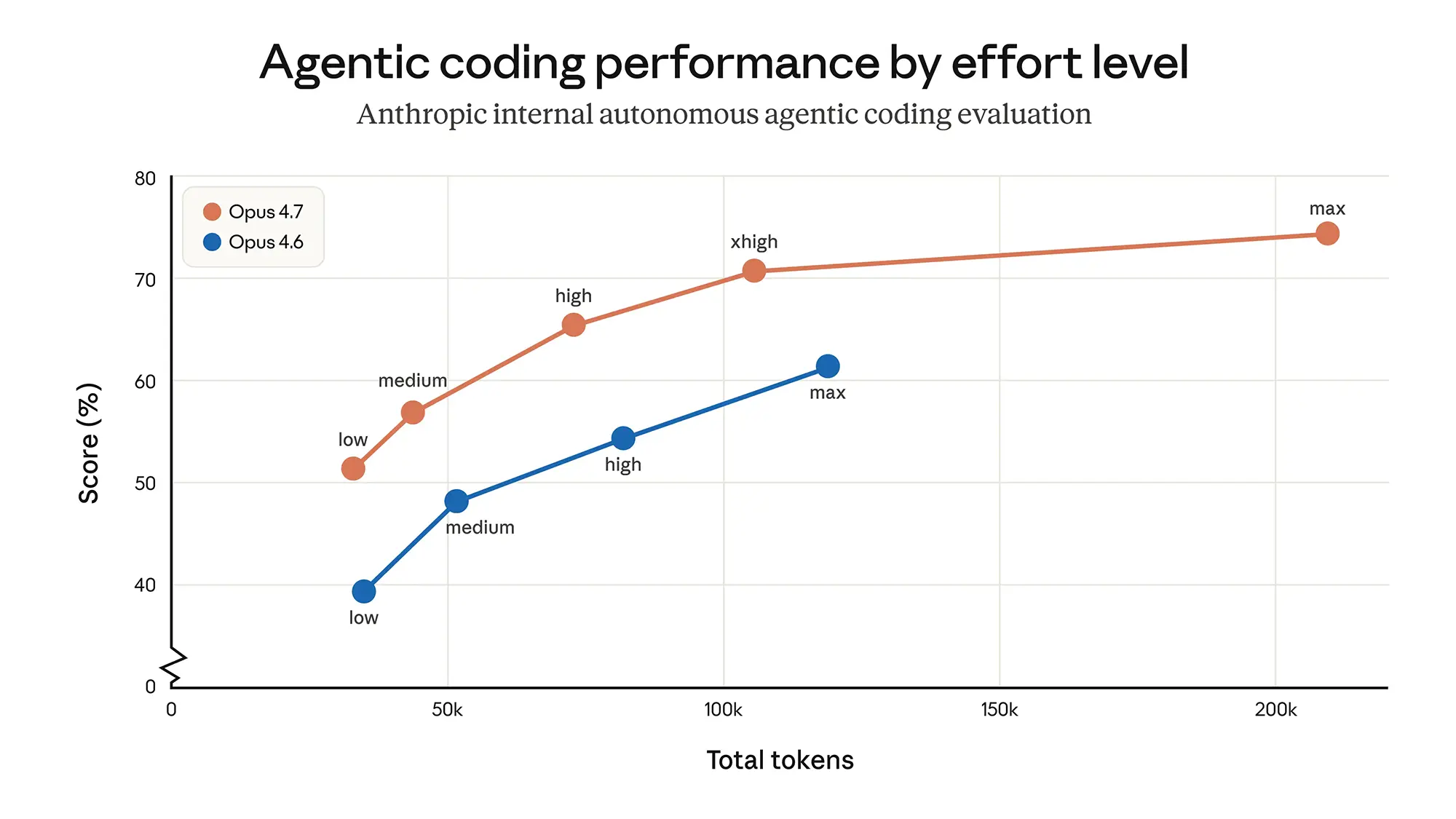
Quelle: Anthropic
Das Preismodell bleibt mit fünf US-Dollar pro Million Input-Token und 25 US-Dollar pro Million Output-Token unangetastet. Allerdings integriert Opus 4.7 einen neuen Tokenizer zur Textverarbeitung. Gleiche Eingaben erzeugen nun abhängig vom Inhalt den Faktor 1,0 bis 1,35 mehr Token.
Das Modell produziert auf höheren Anstrengungsstufen zudem längere Antworten. Entwickler deckeln diese Ausgaben bei Bedarf über sogenannte Task Budgets in der API. Diese Kostenkontrolle läuft aktuell in einer öffentlichen Beta-Phase.
Anzeige
Sicherheit und Verfügbarkeit
Anthropic integriert bei diesem Release im Rahmen des internen Project Glasswing neue Sicherheitsfunktionen. Das System erkennt und blockiert automatisch Anfragen, die auf verbotene oder riskante Einsätze im Bereich der Cybersicherheit hindeuten. Die Cyber-Fähigkeiten des Modells sind bewusst geringer ausgeprägt als beim internen Top-Modell Claude Mythos Preview.
Sicherheitsexperten für Penetrationstests erhalten über ein spezielles Verifizierungsprogramm weiterhin Zugriff auf die benötigten Funktionen. Das allgemeine Verhaltensaudit zeigt laut System Card ansonsten ein ähnliches Sicherheitsprofil wie beim Vorgänger.
Quelle: Anthropic
Claude Opus 4.7 vs. Claude Mythos
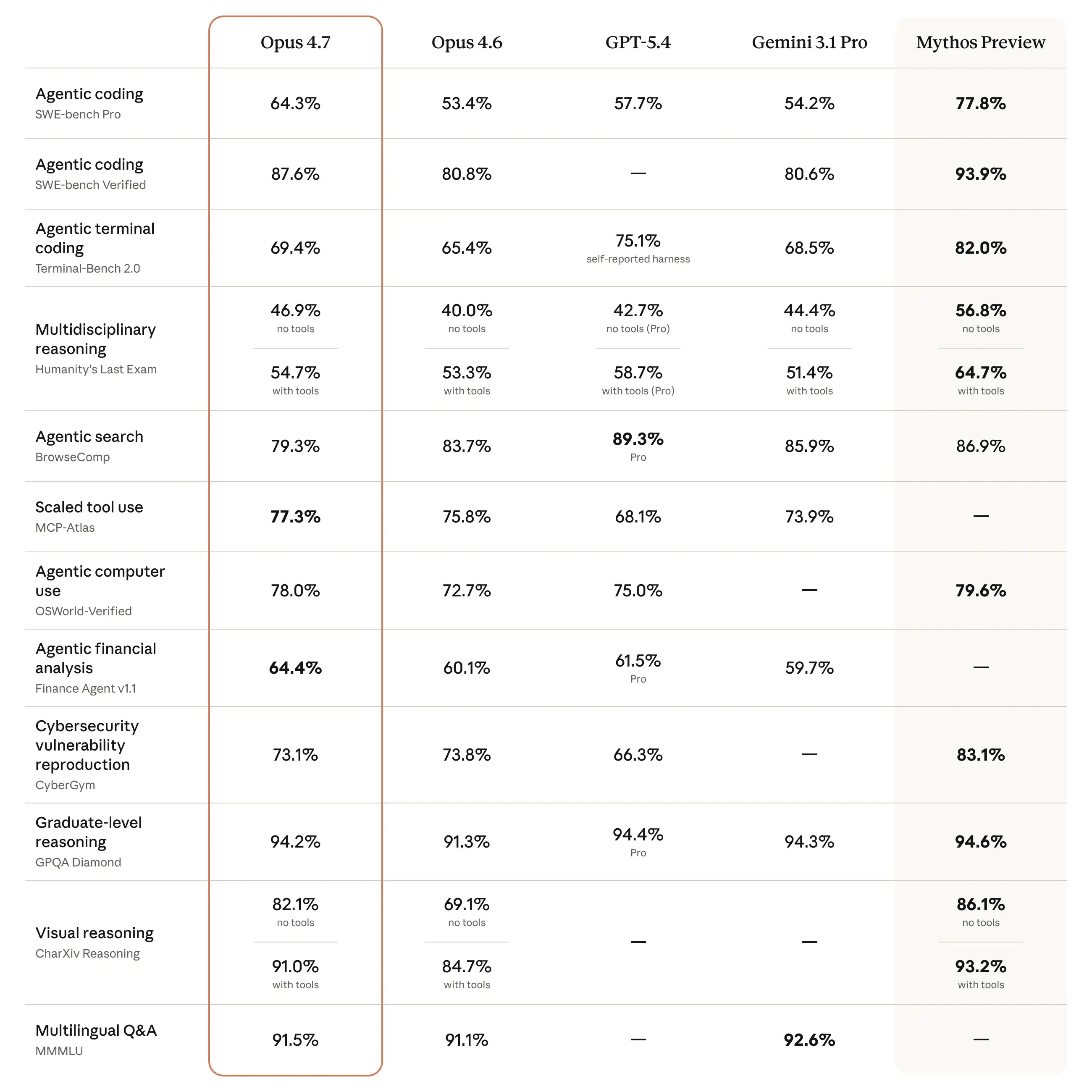
Ein direkter Vergleich zeigt, dass Opus 4.7 in spezifischen Disziplinen dicht zu Anthropics internem Top-Modell aufschließt. Besonders bei der visuellen Dokumentenanalyse und der Verarbeitung langer Kontexte sind die Unterschiede marginal. Im Test CharXiv erreicht die Neuentwicklung 91,0 Prozent und liegt damit nur knapp hinter den 93,2 Prozent von Claude Mythos Preview.
Auch beim GPQA Diamond Benchmark trennen die KI-Modelle mit 94,2 Prozent zu 94,6 Prozent lediglich Nuancen. Ähnlich eng fällt das Rennen bei agentischen Computer Use aus. Hier rückt Opus 4.7 mit 78,0 Prozent sehr nahe an die 79,6 Prozent der Preview-Version heran.
Quelle: Anthropic
Deutliche Abstände zeigen sich hingegen bei hochkomplexen Programmieraufgaben. Im anspruchsvollen SWE-bench Pro erzielt Mythos Preview starke 77,8 Prozent und verweist Opus 4.7 mit dessen 64,3 Prozent klar auf die hinteren Plätze. Auch beim standardisierten Code-Test SWE-bench Verified hält das Flaggschiff mit 93,9 Prozent zu 87,6 Prozent einen spürbaren Vorsprung.
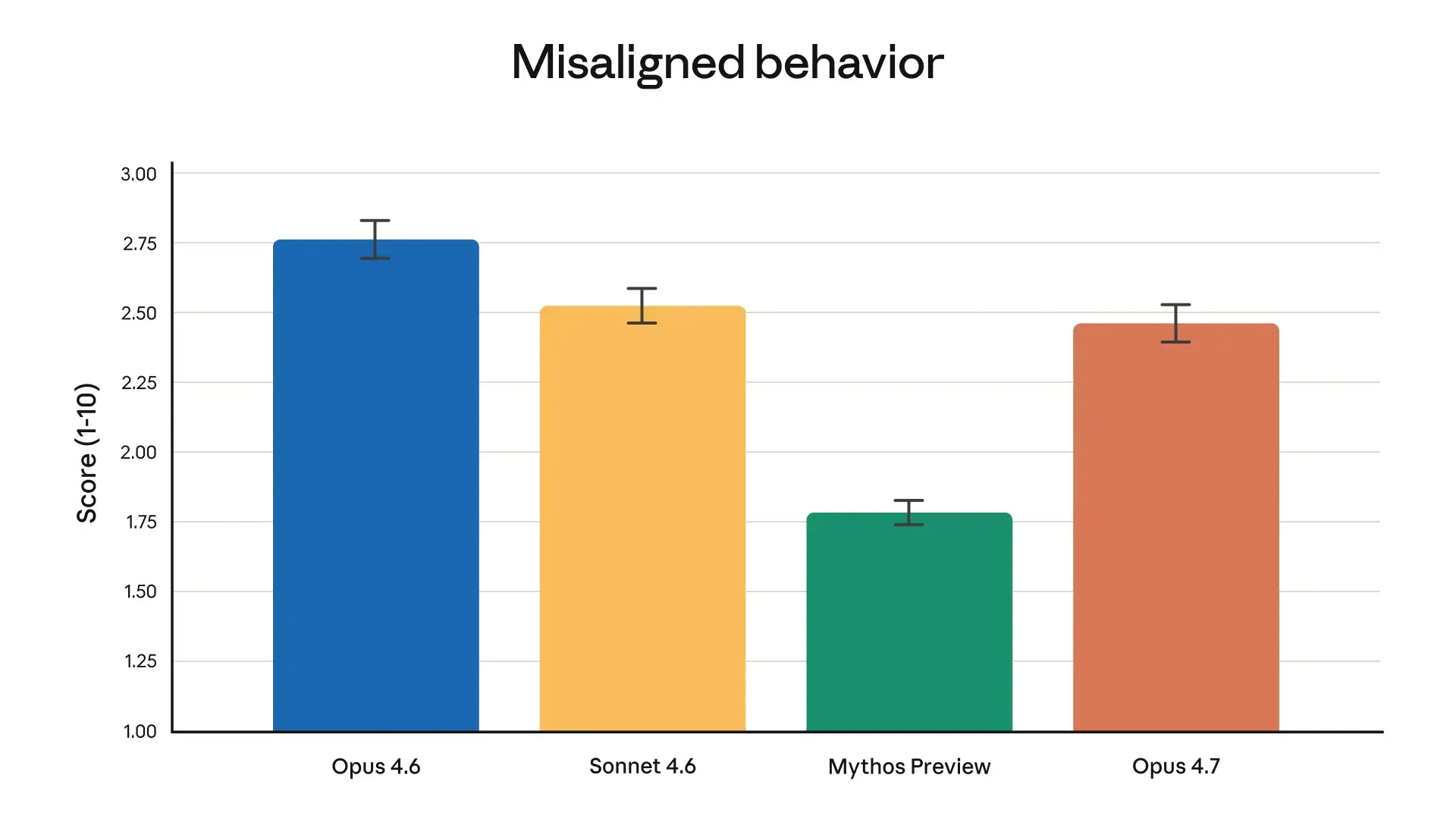
Ein vergleichbares Bild liefert der Cybersicherheits-Test CyberGym. Hier demonstriert das Top-Modell mit 83,1 Prozent seine Überlegenheit gegenüber den 73,1 Prozent der aktuellen Veröffentlichung. Bei der internen Sicherheitsbewertung für fehlerhaftes Verhalten führt das exklusive Modell ebenfalls mit einem niedrigeren Score von 1,77 im Vergleich zu den 2,44 des neuen Modells.
Diese Leistungsdifferenz setzt sich abschließend bei der allgemeinen Wissensarbeit fort. Der Benchmark Humanitys Last Exam bescheinigt Mythos Preview mit 64,7 Prozent eine wesentlich stärkere Performance als Opus 4.7, welches hier lediglich 54,7 Prozent erreicht.
Claude Mythos bleibt den Daten zufolge das leistungsstärkste und sicherste System im Portfolio. Opus 4.7 bildet parallel dazu die aktuelle Spitze der frei zugänglichen Modelle.