
Claude-Agenten besser und effektiver nutzen
Ein neuer technischer Leitfaden zeigt Entwicklern, wie sie Sprachmodelle optimal für die Navigation auf Benutzeroberflächen konfigurieren.
Anthropic hat einen detaillierten Leitfaden erstellt, der erklärt, wie man am besten mit KI-Agenten umgeht. Dieser ist speziell auf Computer- und Browser-Use ausgerichtet. Wir haben die wichtigsten Erkenntnisse daraus kompakt zusammengefasst.
Auflösung entscheidet über Klickgenauigkeit
Damit Sprachmodelle Schaltflächen fehlerfrei treffen, spielt die Bildauflösung die wichtigste Rolle. Überschreiten übermittelte Screenshots interne Limits, skaliert die Schnittstelle diese Bilder im Hintergrund blind herunter. Dadurch verschieben sich die Koordinaten. Klicks landen folglich im Leeren.
Entwickler erzielen die besten Ergebnisse mit einer Standardauflösung von 1280 mal 720 Pixeln. Dieses Format beansprucht etwa 80 Prozent des verfügbaren Budgets der 4.6-Modellfamilie, welche maximal 1,15 Megapixel verarbeitet. Für das leistungsstärkere Opus 4.7 empfehlen sich 1080p-Aufnahmen, da hier die Obergrenze bei 3,75 Megapixeln liegt.
Zusätzlich steigert eine simple Anpassung im Prompt die Zuverlässigkeit deutlich. Steht die Textanweisung direkt vor dem eingefügten Bild, weiß das Modell bereits beim Betrachten des Screenshots genau, wonach es sucht.
Das erklärt beispielsweise auch, warum man Screenshots von einem 4K-Monitor nicht einfach so in den Chatbot ziehen sollte. Oft werden diese Bilder ignoriert.
Anzeige
Modellauswahl und dynamischer Denkaufwand
Für die meisten Aufgaben bietet Sonnet 4.6 das beste Verhältnis aus Klickpräzision, Leistung und Kosten. Opus 4.7 schließt jedoch die Lücke bei der mechanischen Genauigkeit und spielt seine echten Stärken vor allem bei hochauflösenden Bildquellen aus. Haiku 4.5 bleibt die erste Wahl, wenn eine extrem niedrige Latenz erforderlich ist.
Moderne KI-Modelle passen ihren Denkaufwand dynamisch an. Ein sogenanntes Adaptive Thinking steuert, wie tiefgründig das System vor einer Aktion plant. Bei der 4.6-Familie erweist sich die mittlere Stufe als optimaler Kompromiss. Dieser Modus erreicht nahezu die Erfolgsquote der höchsten Stufe, benötigt dafür aber nur rund die Hälfte der Ausgabe-Token. Selbst ein niedriger Denkaufwand liefert überraschend starke Resultate und unterbietet den Token-Verbrauch eines komplett deaktivierten Denkprozesses, da das System insgesamt weniger Fehler begeht.
Das heißt konkret, dass man bei der Bildanalyse mit weniger Nachdenken die gleichen Ergebnisse erzielt, aber deutlich günstiger. Jedenfalls bei Claude Sonnet 4.6.
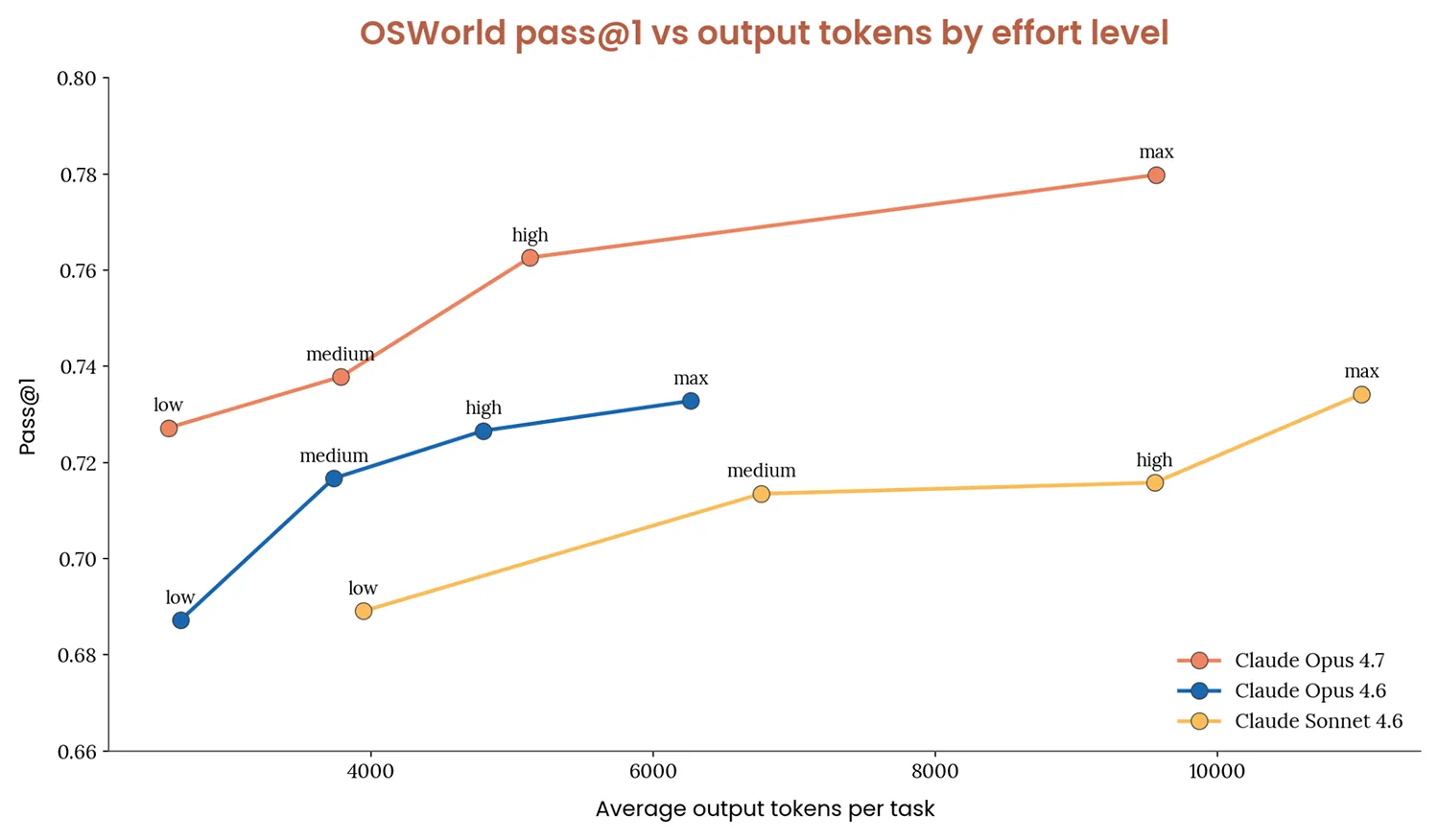
Quelle: Anthropic
Schutz vor manipulierten Inhalten
KI-Agenten interagieren zwangsläufig mit nicht vertrauenswürdigen Inhalten aus dem offenen Internet. Versteckte Texte oder trügerische Oberflächen bergen eine hohe Gefahr für eine Prompt Injection. Standardmäßige Klassifikatoren prüfen daher jeden eingehenden Screenshot automatisch auf manipulative Befehle.
Diese Schutzmechanismen arbeiten parallel zur eigentlichen Inferenz, verursachen keine zusätzliche Latenz und greifen kostenfrei. Dennoch bleiben ergänzende Sicherheitsvorkehrungen unerlässlich. Eine Freigabeschleife durch Menschen bei kritischen Aktionen sowie streng limitierte Berechtigungen für den Agenten minimieren mögliche Schäden effektiv.
Nur zur Einordnung: Wenn man KI-Agenten aktuell freie Hand lässt, darf man sich über »Probleme« nicht beschweren.
Strategisches Kontext-Management
Bildschirmaufnahmen füllen das Kontextfenster extrem schnell. Effektives Management der Historie entscheidet maßgeblich über Latenz und Betriebskosten. Caching-Strategien reduzieren den Aufwand enorm, sofern Entwickler die Haltepunkte klug setzen. Ein Breakpoint für den System-Prompt sowie bis zu drei weitere für die jüngsten Ergebnisse erhalten den Cache-Status über viele Schritte hinweg aufrecht.
Anstatt alte Bilder kontinuierlich einzeln zu löschen, lohnt sich das systematische Entfernen in größeren Blöcken. So bleibt der Verlauf für den Cache über mehrere Runden völlig identisch. Reicht dieses Vorgehen nicht aus, fasst eine LLM-gestützte Komprimierung die bisherige Konversation in einem kompakten Text zusammen. Dabei bleiben alle ursprünglichen Vorgaben und bisherigen Lösungswege strikt erhalten.
Anzeige
Arbeitsabläufe vormachen statt erklären
Oft scheitern reine Textanweisungen an komplexen Benutzeroberflächen. Ein alternativer Ansatz lässt Anwender den Prozess einfach vorab aufzeichnen. Das System speichert dabei Klicks, Tastenanschläge und begleitende Screenshots.
Bei späteren Ausführungen dient diese visuelle Aufzeichnung als direkter Leitfaden. Das Modell vergleicht die hinterlegten Bilder mit der aktuellen Benutzeroberfläche und passt sein Verhalten an geänderte Layouts dynamisch an. Eine derartige visuelle Führung steigert die Zuverlässigkeit bei fehleranfälligen Abläufen erheblich. Letztlich bilden diese Methoden ein robustes Fundament für die nächste Generation produktiver Agenten-Systeme.
Ausführlicher und mit konkreten Code-Beispielen geht es hier weiter: Anleitung von Anthropic





