
So simpel funktioniert Metas Tuna-2 ohne Encoder
Eine schlanke Architektur verarbeitet rohe Bildpunkte direkt und erreicht dadurch Spitzenwerte bei visuellen Aufgaben.

Forscher von Meta AI präsentieren mit Tuna-2 ein neues KI-Modell, das Bildinhalte komplett ohne klassische Vision-Encoder verarbeitet. Die Architektur liest rohe Pixel direkt ein und vereinfacht so die Kombination aus Bildverständnis und Bilderstellung merklich.
Einsatzgebiete und Relevanz
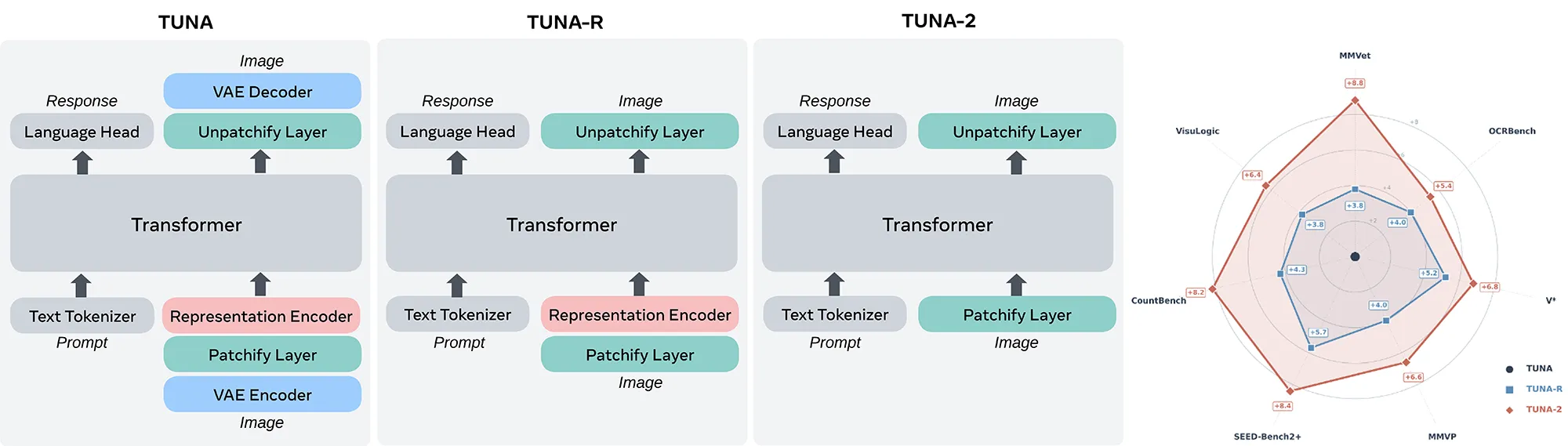
Grundsätzlich handelt es sich bei Tuna-2 um ein sogenanntes natives multimodales Modell. Solche KI-Modelle können sowohl visuelle Eingaben exakt verstehen als auch eigene Bilder basierend auf einem Prompt generieren. Bisher nutzen Entwickler dafür oft getrennte Bausteine, um Bilddaten zunächst in abstrakte Werte zu übersetzen.
Tuna-2 lässt diesen komplizierten Zwischenschritt komplett weg und arbeitet stattdessen direkt mit einfachen Patch-Embeddings der rohen Pixel. Das System verzichtet somit völlig auf etablierte Komponenten wie VAE-Module.
Durch diesen direkten Ansatz eignet sich das Modell vor allem für Aufgaben, die ein scharfes Auge für visuelle Details verlangen. Typische Einsatzbereiche umfassen die präzise Texterkennung auf Fotos oder die logische Analyse von komplexen Diagrammen in Dokumenten.
Quelle: Meta
So schlägt sich Tuna-2 in den Benchmarks
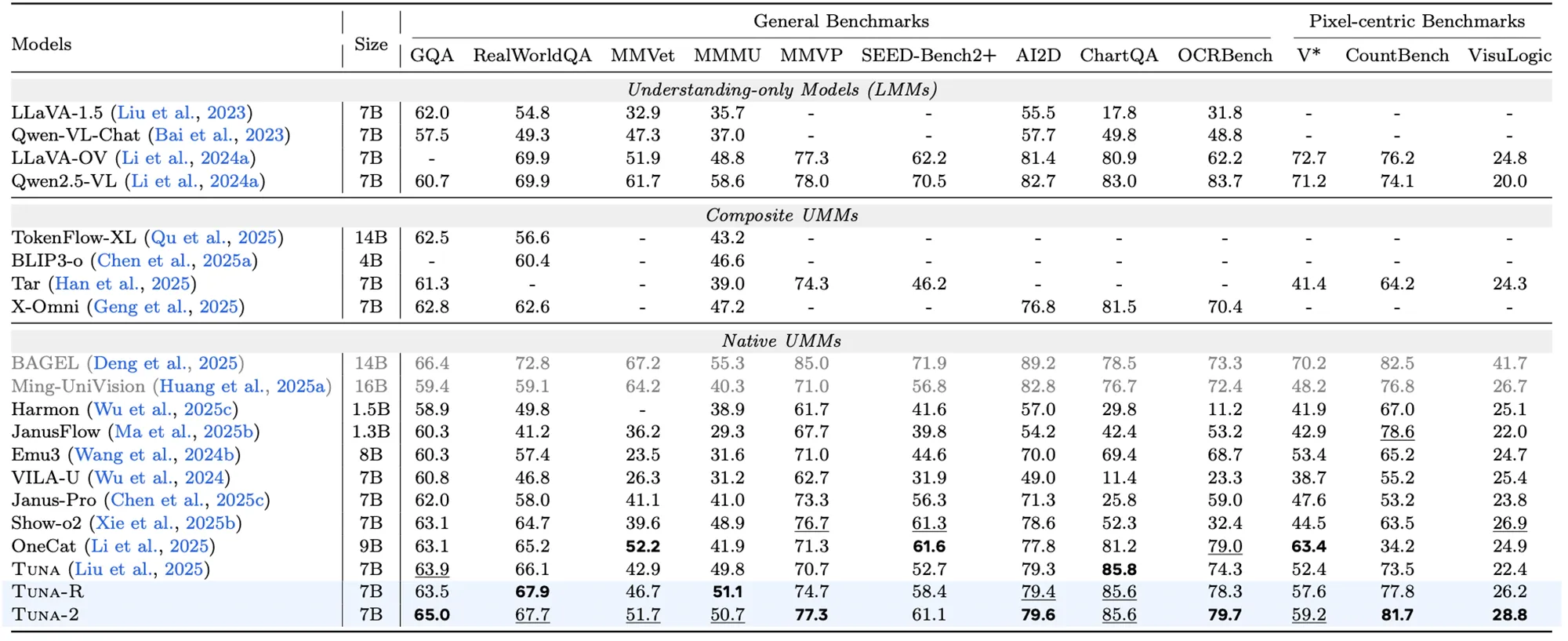
Bei Leistungstests vergleichen die Forscher ihre Entwicklung ganz bewusst nicht mit reinen Bildgeneratoren, sondern mit anderen multimodalen Allroundern. Das System tritt folglich gegen Modelle wie LLaVA, Qwen-VL oder Show-o2 an, die ebenfalls Text und Bild in einer gemeinsamen Architektur vereinen.
In diesen Vergleichen zeigt sich eine klare Stärke der direkten Pixelverarbeitung. Besonders bei feingranularen Tests wie dem OCRBench erzielt Tuna-2 bessere Werte als vergleichbare Varianten, die weiterhin auf klassische Bild-Encoder setzen.
Für die anschließende Bilderstellung greift das KI-Modell auf ein Verfahren namens Pixel-Space Flow Matching zurück. Damit erreicht die Software eine hohe visuelle Qualität, die mühelos mit bisherigen Systemen auf Basis komprimierter Daten mithalten kann.
Quelle: Meta
Weniger Komplexität für die Zukunft
Ein interessanter Aspekt des Systems liegt im robusten Trainingsprozess. Die Entwickler verdecken während der Lernphase zufällige Bildbereiche, weshalb das KI-Modell fehlende visuelle Informationen logisch herleiten muss.
Dieser Trick zwingt den einzelnen Transformer-Decoder dazu, tiefergehende Zusammenhänge eigenständig zu erkennen. Auch ohne zusätzliche Repräsentations-Encoder baut das System so ein detailliertes Verständnis für visuelle Strukturen auf.
Letztlich demonstriert Meta AI mit diesem Projekt eindrucksvoll, dass multimodale Modelle durch weniger Architektur-Ballast spürbar leistungsfähiger werden. Eine direkte Verarbeitung von Bildpunkten stellt einen äußerst vielversprechenden Weg für künftige Generationen von KI-Systemen dar.
