
ChatGPT Images 2.0 deklassiert Nano Banana
Das neue Bild-Modell punktet mit echtem Reasoning, fehlerfreiem Text-Rendering und nativen Auflösungen für professionelle Anwender.


Bildgenerierung mit integriertem Denkprozess
Das neue KI-Modell verfügt über sogenannte Thinking-Fähigkeiten, die den bisherigen Generierungsablauf grundlegend verändern. Nutzer der Pro- und Plus-Tarife erhalten Zugriff auf diesen erweiterten Prozess. Im Hintergrund greift das System auf eine Websuche zu, um Echtzeitinformationen abzurufen. Erst nach dieser Recherche plant die Architektur den strukturellen Bildaufbau, bevor die eigentliche visuelle Ausgabe startet.
Dieser agentische Ansatz erlaubt zudem eine völlig neue Arbeitsweise bei umfangreichen Projekten. Statt jedes Motiv einzeln abzufragen, erstellt das System bis zu acht zusammenhängende Bilder in einem einzigen Durchlauf. Anwender erhalten dadurch kohärente Serien. Die KI wahrt dabei eigenständig die visuelle Kontinuität von Charakteren und Objekten über verschiedene Motive hinweg. Das vereinfacht die Erstellung von Storyboards oder plattformübergreifenden Social-Media-Kampagnen enorm.
Zusätzlich greift die Software auf eine sehr aktuelle Datenbasis zurück. Mit einem Wissensstand bis Dezember 2025 ordnet das Modell moderne Benutzeroberflächen oder zeitgemäße Diagrammtypen korrekt ein. Komplexe Zusammenhänge verarbeitet die Architektur dadurch nahezu fehlerfrei zu verständlichen Infografiken.
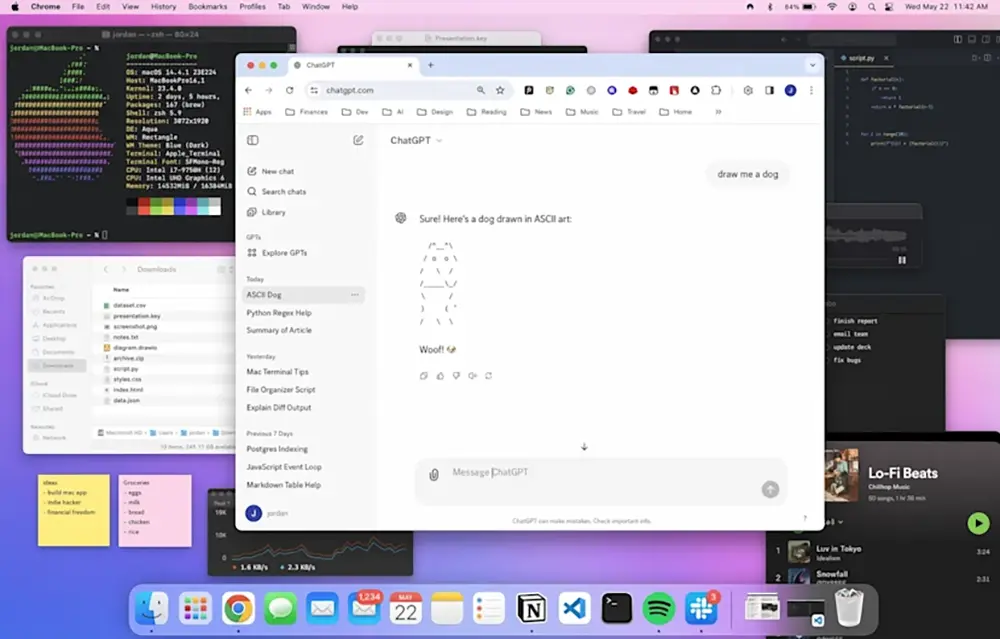
Quelle: OpenAI
a screenshot of chatgpt, in a browser, in macosx. the user types "draw me a dog" chatgpt draws an ascii dog the front window is chatgpt, but the desktop is quite messy with lots of random windows open (e.g. a terminal). they're all in the background
Native Formate beenden die Skalierungs-Probleme
Ein massiver Kritikpunkt an älteren Modellen war stets die starre Formatvorgabe. ChatGPT Images 2.0 löst dieses Problem durch eine weitreichende native Unterstützung für Seitenverhältnisse zwischen 3:1 und 1:3. Designer bekommen direkt die passenden Dimensionen für extrem breite Banner oder hochformatige Smartphone-Layouts geliefert.
Besonders im wichtigen 16:9-Format zeigt sich ein immenser technischer Fortschritt. Während andere KI-Modelle oft auf krumme Auflösungen wie 1920x1072 Pixel ausweichen müssen, generiert die neue OpenAI-Architektur exakte 1920x1080 Pixel. Nachträgliches Zuschneiden oder unsauberes Erweitern in externen Programmen entfällt somit vollständig. Die Bilder lassen sich ohne Zwischenschritte direkt in Präsentationen oder Videoprojekte einbinden.

Quelle: OpenAI
an editorial magazine page about wolves in north america and how they're more harmless than we think. make it look like a glossy, smooth, well laid out widely distributed science magazine.
Fokus auf komplexe Typografie und Fotorealismus
Da digitale Bilder zunehmend Text enthalten, scheiterten bisherige Bildgeneratoren häufig an der präzisen Darstellung von Buchstaben. Das aktualisierte Modell rendert Schriftzüge nun fehlerfrei und bettet sie logisch in das Design ein. Bemerkenswert ist dabei die Leistung abseits lateinischer Buchstaben. Die KI beherrscht komplexe Schriftsysteme wie Japanisch, Koreanisch, Chinesisch oder Hindi fließend und integriert diese sprachlich korrekt in Manga-Seiten oder Plakate.

Quelle: OpenAI
Make a sample page of a colorized Japanese shonen adventure manga. The page should vividly depict our main character found a magical quill. The name of the quill is called the Quill of GPT Image. Make it dramatic. The magical quill has strong power sealed inside it. Additional instructions: Aspect ratio: Portrait 1440x2560. The pen should have an OpenAI logo on it. The language throughout the manga should be Japanese. Think carefully first to make this a good story with good split of manga panels. The page should appear as a photo of a physical page, not a digital page.
Neben der Typografie fokussierten sich die Entwickler auf feine fotografische Nuancen. Anstatt einen bestimmten Look nur oberflächlich zu imitieren, reproduziert das System die exakten physikalischen Charakteristika historischer Kameras. Sichtbares Filmkorn bei analogen 35-Millimeter-Aufnahmen generiert die Architektur ebenso authentisch wie den extrem harten Blitzlicht-Look von Kompaktkameras aus den frühen 2000er Jahren. Kleine Unvollkommenheiten baut die KI bewusst ein, wodurch die Ergebnisse weniger nach klassischer Computergrafik und mehr nach echten dokumentarischen Schnappschüssen aussehen.

Quelle: OpenAI
A photorealistic candid travel scene of a person standing at a coastal roadside turnout on an overcast morning, shot on 35mm film. Natural imperfect framing, visible grain, ambient light, muted colors, wind in clothing and hair, cinematic realism, and the feeling of a lived-in documentary photograph.
Spitzenplatz im Benchmark
Die architektonischen Verbesserungen spiegeln sich überdeutlich in unabhängigen Tests wider. Im aktuellen Leaderboard der Text-to-Image Arena erreicht gpt-image-2 einen Score von 1512 Punkten. Damit deklassiert die Architektur die komplette Konkurrenz regelrecht. Zum Vergleich erzielt der Zweitplatzierte, das Modell Gemini 3.1 Flash, lediglich 1270 Punkte, was einen ungewöhnlich großen Leistungsabstand in dieser Branche markiert.
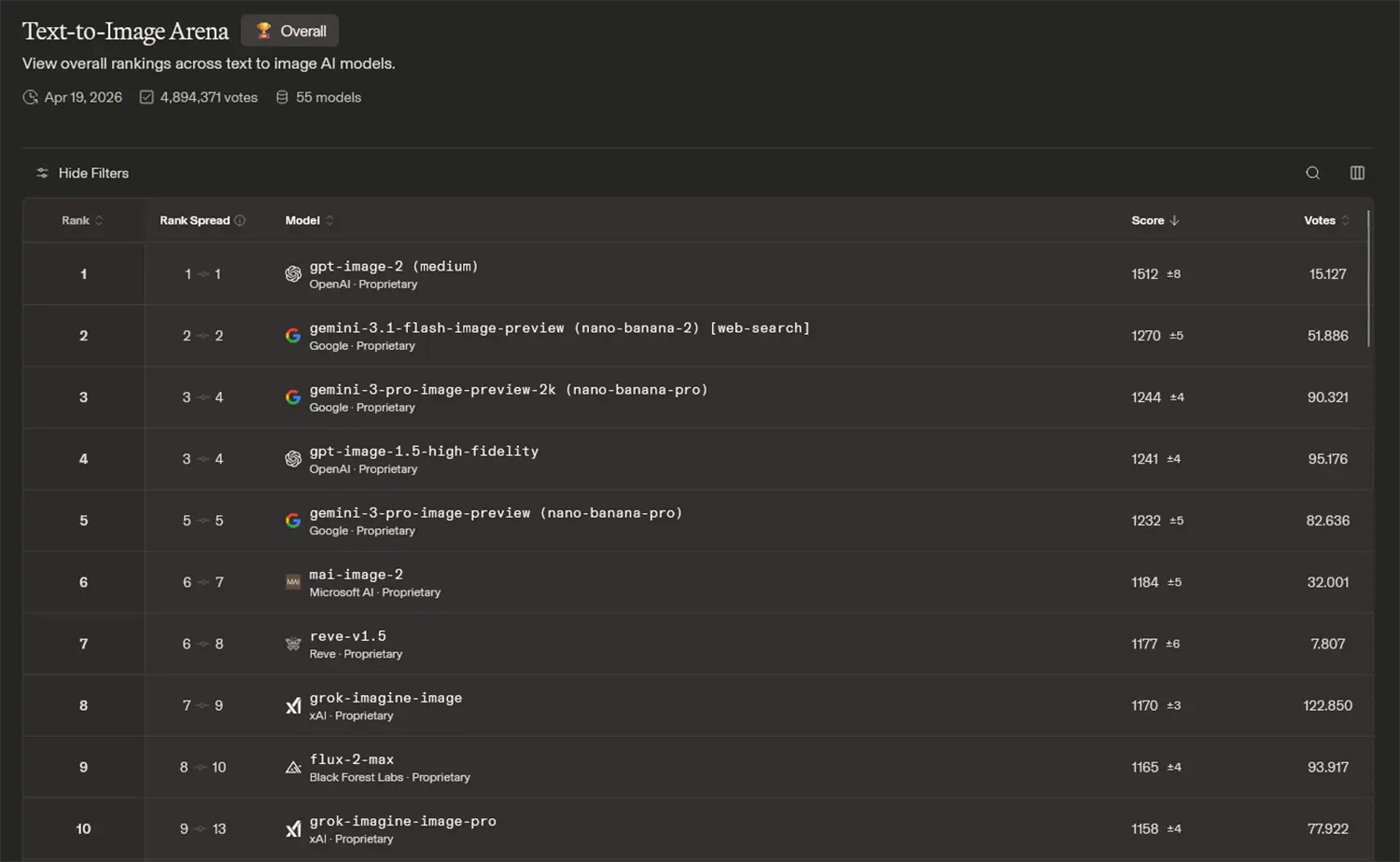
Quelle: OpenAI
Ein ähnliches Bild zeigt sich bei der isolierten Betrachtung der Bildbearbeitungs-Fähigkeiten. Auch in der Image Edit Arena setzt sich das System mit 1513 Punkten unangefochten an die Spitze. Vorherige Platzhirsche sowie aktuelle Konkurrenzmodelle verharren hier auf den Rängen dahinter mit Werten knapp unter der 1400er-Marke. Derart eindeutige Punkteabstände belegen den bemerkenswerten qualitativen Vorsprung der neuen Generation.
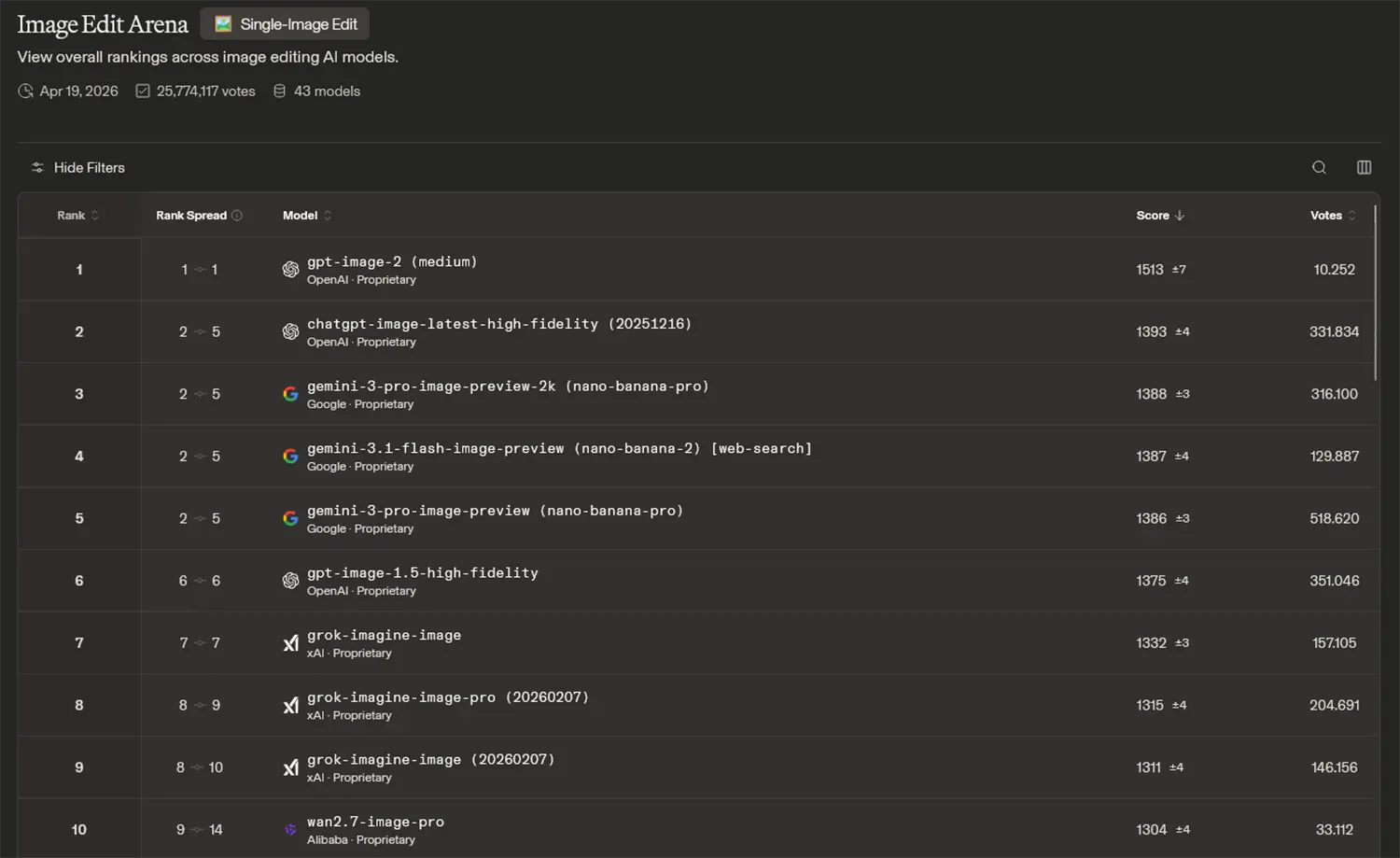
Quelle: OpenAI
Verfügbarkeit und Physikalische Grenzen
Trotz der bemerkenswerten Benchmark-Ergebnisse besitzt die Architektur weiterhin klare physikalische Limits. Das KI-Modell scheitert in der Praxis gelegentlich an komplexen räumlichen Logikrätseln. Einen verdrehten Zauberwürfel oder detaillierte Origami-Faltanleitungen stellt das System oft fehlerhaft dar. Verdeckte Oberflächen oder extrem dichte, repetitive Strukturen wie feine Sandkörner zwingen die Berechnung ebenfalls noch immer zu unpräzisen Kompromissen.
ChatGPT Images 2.0 ist ab sofort in allen OpenAI Produkten verfügbar und auch bei externen Anbietern schon aufgetaucht. Wir verwenden das Modelle gerade für 2 Tutorials über Higgsfield. Dort ist es schon voll integriert.
