
KI-Modell GLM-5.1 schlägt Konkurrenz im SWE-Bench Pro
Mit starken Ergebnissen in der Code-Generierung zeigt die Architektur ihre Fähigkeiten. Bei Terminal-Aufgaben bleibt GPT-5.4 jedoch ungeschlagen.

Das neue KI-Modell GLM-5.1 fokussiert sich auf autonome Softwareentwicklung durch KI-Agenten. Die Architektur löst komplexe Programmieraufgaben über lange Zeiträume und liefert in aktuellen Benchmarks starke, aber gemischte Ergebnisse.
Ausdauer für lange Code-Projekte
Bisherige KI-Modelle schöpfen ihr Potenzial bei schwierigen Aufgaben oft schnell aus. GLM-5.1 wählt hierbei einen anderen Ansatz. Das Modell meistert sogenannte »Long-Horizon Tasks« und arbeitet über Hunderte von Schritten produktiv. Es analysiert die eigenen Ergebnisse in Echtzeit und passt die Lösungsstrategie eigenständig an.
Diese Ausdauer zeigt sich in harten Benchmarks. Bei der Optimierung einer Vektordatenbank erreichte das KI-Modell nach 600 Durchläufen 21.500 QPS. Das entspricht ungefähr der sechsfachen Leistung bisheriger Bestwerte. Die Architektur identifiziert Flaschenhälse im Code völlig autark und strukturiert den Aufbau neu.
Ein weiterer Test demonstriert die Fähigkeiten bei unstrukturierten Aufgaben. Das KI-Modell baute innerhalb von acht Stunden eine komplette Linux-Desktop-Umgebung als Webanwendung auf. Dabei integrierte die KI komplexe Elemente wie einen Dateibrowser und ein Terminal fließend in die Benutzeroberfläche.
Anzeige
Differenziertes Bild in den Benchmarks
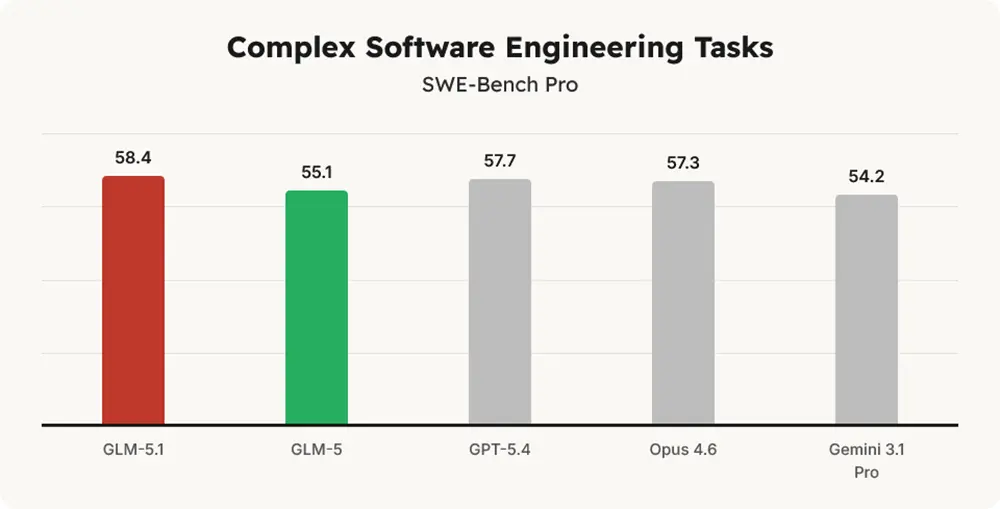
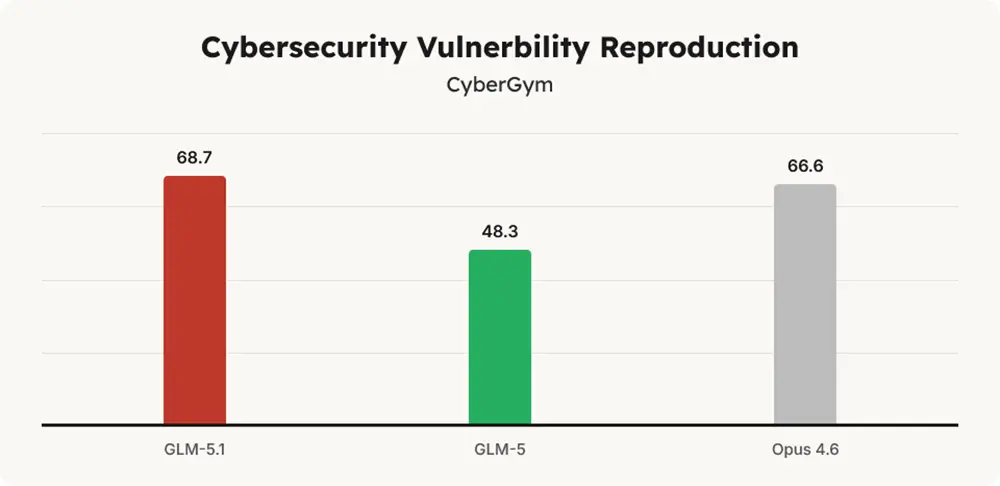
GLM-5.1 übertrifft bei der reinen Code-Generierung und in Sicherheitstests viele etablierte Konkurrenten. Im SWE-Bench Pro erreicht das KI-Modell einen Wert von 58,4 und verweist GPT-5.4 knapp auf den zweiten Platz. Bei der Reproduktion von Sicherheitslücken im CyberGym-Benchmark erzielt das Modell beachtliche 68,7 Punkte und schlägt damit Opus 4.6.
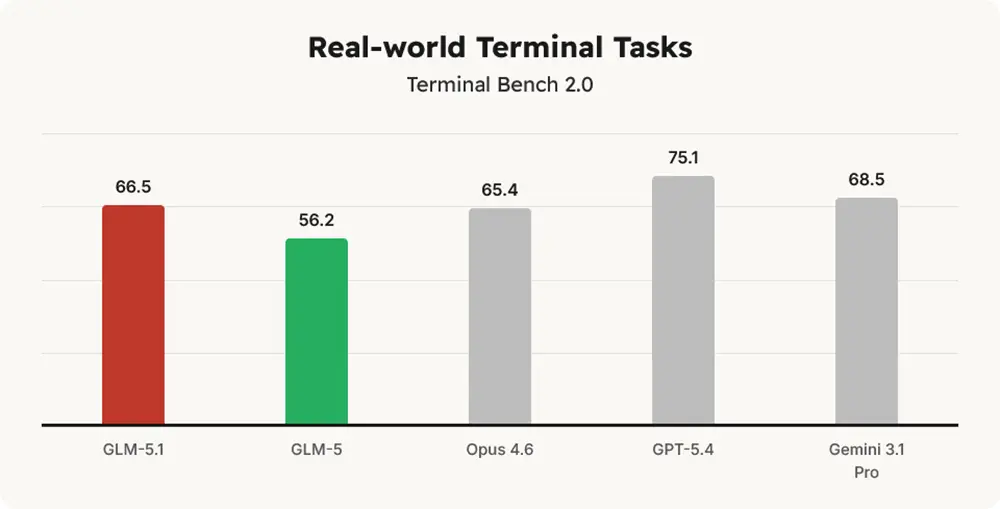
Andere Auswertungen zeigen jedoch deutliche Leistungsgrenzen. Im Terminal-Bench 2.0 verbessert sich GLM-5.1 zwar im Vergleich zum Vorgänger auf 66,5 Punkte, bleibt damit aber hinter GPT-5.4 mit 75,1 Punkten und Gemini 3.1 Pro zurück.
Quelle: Zhipu AI
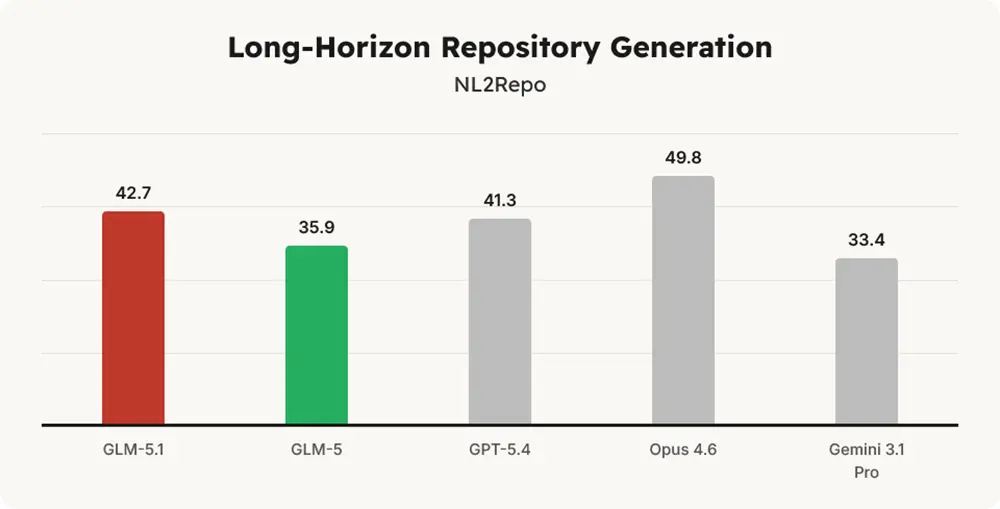
Ein ähnliches Bild zeichnet der NL2Repo-Benchmark für die Generierung ganzer Repositories. Das KI-Modell kommt hier auf 42,7 Punkte und muss sich Opus 4.6 geschlagen geben, das mit 49,8 Punkten die Rangliste deutlich anführt.
Quelle: Zhipu AI
Offener Zugang für Entwickler
Softwareentwickler binden das KI-Modell direkt in ihre bestehenden Arbeitsabläufe ein. GLM-5.1 ist nativ mit gängigen Assistenten wie Claude Code oder Roo Code kompatibel.
Die Gewichte des Modells stehen als Open Source unter der flexiblen MIT-Lizenz bereit. Plattformen wie HuggingFace bieten die Dateien kostenlos für den Download an. Für die lokale Ausführung unterstützen performante Frameworks wie vLLM und SGLang die Architektur direkt.
Wer keine eigene Infrastruktur aufbauen möchte, greift auf offizielle Programmierschnittstellen zurück. Das neue KI-Modell steht über die Plattformen des Anbieters zur Verfügung.