
Die große Heuchelei der KI-Industrie
Jeder stiehlt von jedem und am Ende droht ein Monopol. Die Technologiebranche verstrickt sich in eklatanter Doppelmoral.

Die KI-Industrie verstrickt sich aktuell in ein absurdes Schauspiel der Doppelmoral, bei dem am Ende jeder auf jeden zeigt. Künstler verklagen die großen KI-Unternehmen wegen millionenfachen Datendiebstahls. Exakt diese Unternehmen beschuldigen nun aber günstigere, meist asiatische Konkurrenten, ihre Technologie systematisch abzuschöpfen. Gleichzeitig ärgern sich diese Open-Source-Anbieter über findige Entwickler, die offene KI-Modelle ungefragt für ihr eigenes Fine-Tuning ausschlachten. Kippt durch diesen Streit am Ende das rechtliche Fundament für das Training, droht als paradoxer Höhepunkt ein gigantisches Monopol der reichsten Tech-Konzerne.
Kreative wehren sich gegen den Datenhunger
Millionen von Bildern, Texten und Artikeln wandern kontinuierlich in die neuronalen Netze der Tech-Branche. Illustratoren, Autoren und Übersetzer beobachten zunehmend, wie ihre hart erarbeiteten Stile als automatische Generierung auf Knopfdruck auftauchen. Die berufliche Existenz vieler Medienschaffender steht spürbar auf dem Spiel.
Die Angst vor dem wirtschaftlichen Ruin treibt viele Betroffene vor die Gerichte. Sammelklagen richten sich gegen die Betreiber von Bildgeneratoren und die Entwickler großer Text-KIs. Sie fordern eine finanzielle Entschädigung und das sofortige Löschen ihrer Werke aus den Trainingsdaten.
Prominente Medienhäuser wie die New York Times ziehen ebenfalls ins Feld. Die Zeitung verklagt OpenAI und Microsoft auf Milliardensummen. Der Vorwurf lautet, die Unternehmen lesen geschützte Archive ohne Erlaubnis ein und bauen damit direkte Konkurrenzprodukte auf.
Twitter Beitrag - Cookies links unten aktivieren.
We build AI to empower people, including journalists.
— OpenAI (@OpenAI) January 8, 2024
Our position on the @nytimes lawsuit:
• Training is fair use, but we provide an opt-out
• "Regurgitation" is a rare bug we're driving to zero
• The New York Times is not telling the full storyhttps://t.co/S6fSaDsfKb
Das Prinzip der fairen Nutzung wackelt
Die Entwickler der KI-Modelle verteidigen ihr Vorgehen vehement und stützen sich auf juristische Ausnahmeregelungen. Sie berufen sich in den USA auf das Konzept des Fair Use. Das zentrale Argument der Tech-Giganten lautet stets, dass die Maschine die Daten nicht einfach kopiert.
Laut den Konzernen lernen die Modelle lediglich Muster und Zusammenhänge, was eine transformative Nutzung darstellt. Die Firmen betrachten das Scannen des offenen Internets als gesellschaftlichen Nutzen und als Motor für zukünftige Innovationen.
Juristen und Gerichte bewerten diese Argumentation aktuell extrem unterschiedlich. Erste Urteile fallen völlig widersprüchlich aus. Manche Richter werten das Training als legale Transformation, andere sehen darin eine klare Urheberrechtsverletzung.
Diese rechtliche Grauzone hält die gesamte Industrie in der Schwebe.
Anzeige
KI-Unternehmen fürchten plötzlich ihre eigene Medizin
Eine hochgradig ironische Wendung nimmt der Streit bei den Entwicklern der KI-Modelle selbst. Unternehmen wie Anthropic und OpenAI betrachten das offene Internet als freien Datenspeicher, reagieren aber extrem empfindlich auf günstigere Konkurrenz. Asiatische Startups wie DeepSeek veröffentlichen enorm fähige Modelle zu einem Bruchteil der bisher üblichen Entwicklungskosten.
Das setzt die westlichen Pioniere massiv unter Druck. Anthropic ging kürzlich an die Öffentlichkeit und warf mehreren chinesischen Konkurrenten vor, die Fähigkeiten der eigenen Systeme schlicht kopiert zu haben.
Twitter Beitrag - Cookies links unten aktivieren.
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
— Anthropic (@AnthropicAI) February 23, 2026
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
Die Entwickler sollen zehntausende gefälschte Accounts angelegt haben, um Millionen von Interaktionen mit dem Modell Claude zu erzeugen. Die asiatischen Firmen nutzen diese hochwertigen Antworten, um ihre eigenen, billigeren Systeme zu trainieren.
Diese Praxis nennt die Fachwelt Distillation. Die etablierten westlichen Unternehmen betrachten diesen Vorgang als unfairen Ideenklau und als Gefahr für das eigene Geschäftsmodell.
Genau hier offenbart sich jedoch der eklatante Widerspruch der Industrie. Die großen Konzerne werten das ungefragte Kopieren des gesamten Internets als legitimes Training, verurteilen das Nutzen ihrer eigenen KI-generierten Ausgaben jedoch streng als Diebstahl.
Anzeige
Die Nahrungskette reicht noch weiter
Der Ärger wandert in der Nahrungskette ungebremst weiter nach unten. Selbst Anbieter von günstigen oder offenen KI-Modellen klagen über den rücksichtslosen Umgang der Konkurrenz.
Ein aktuelles Beispiel liefert das japanische Unternehmen Rakuten. Die Entwickler veröffentlichten kürzlich eigene Modelle, stehen aber nun unter dem dringenden Verdacht, sich bei der Architektur schlicht bei DeepSeek bedient zu haben. Jeder kopiert in diesem Markt scheinbar jeden.
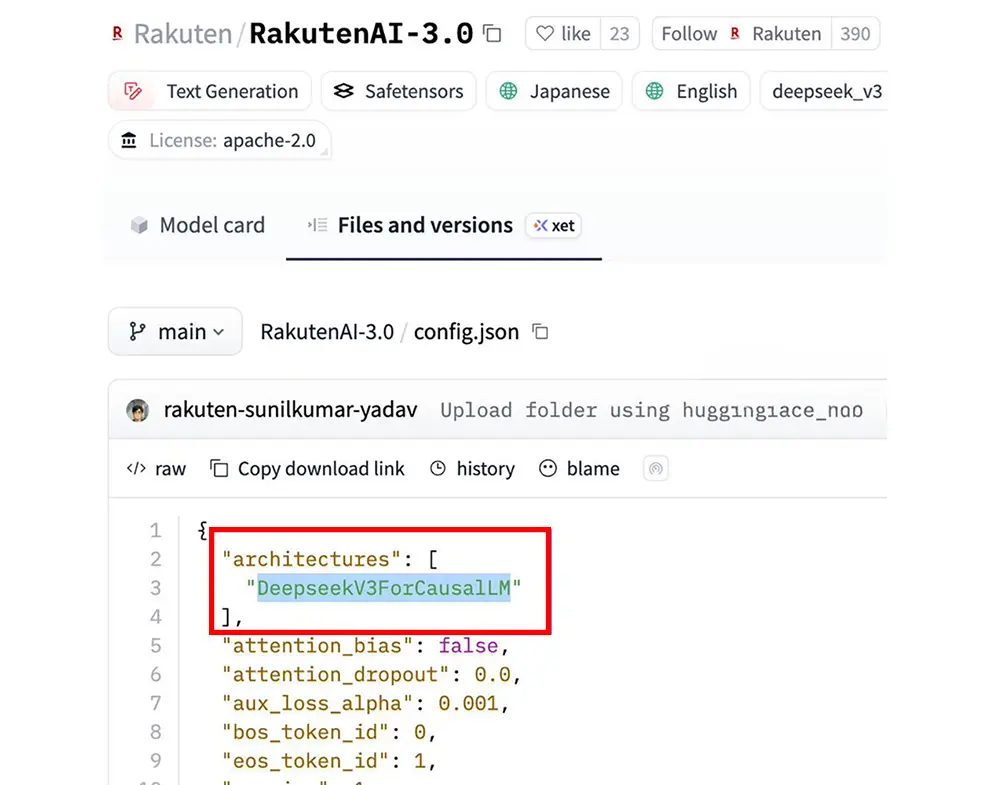
Quelle: Huggingface
Auch auf der Ebene der reinen Software-Anwendungen verschwinden die Hemmungen. Anbieter von modernen Programmier-Editoren wie Cursor greifen für ihre kommerziellen Produkte dankbar auf fremde Vorarbeit zurück. Jüngste Analysen belegen erwiesenermaßen, dass Cursor für seine Funktionen heimlich das Modell Kimi 2.5 des Startups Moonshot AI über ein gezieltes Fine-Tuning anzapfte.
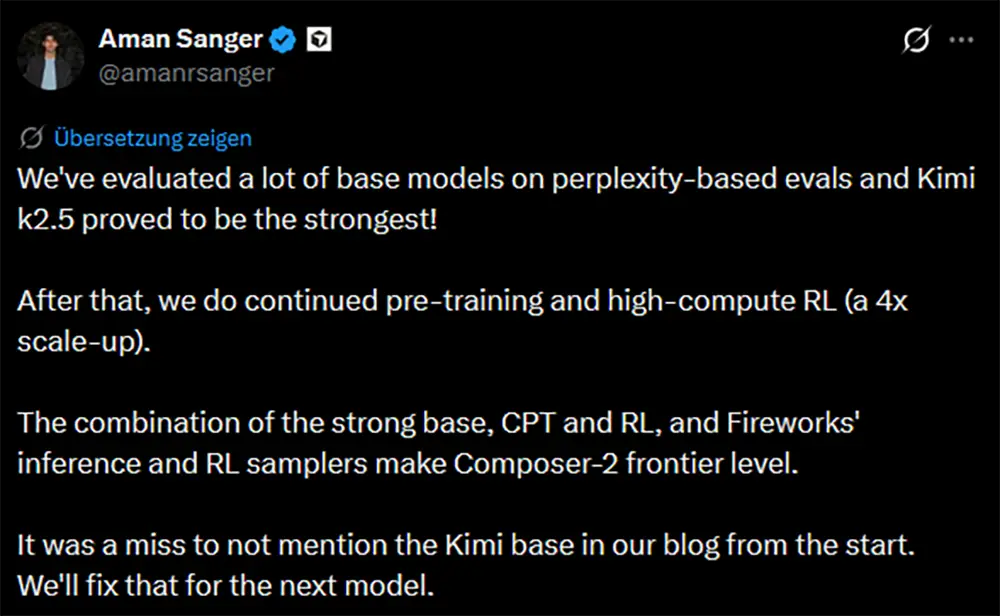
Quelle: amanrsanger @X
Diese "Nachnutzer" investieren selbst kaum Geld in die extrem teure Grundlagenforschung. Sie bauen stattdessen lukrative Dienste auf dem Rücken der ursprünglichen Schöpfer. Auf den Plattformen häufen sich daher die Beschwerden, da sich in diesem Ökosystem am Ende jeder Teilnehmer von der nächsten Ebene ausgenutzt fühlt.
Die Gefahr des perfekten Monopols
Hinter all diesen juristischen und moralischen Streitigkeiten lauert ein enormes strategisches Risiko für den gesamten Markt. Setzen sich die Urheber durch und die Gerichte verbieten das freie Training endgültig, ändert sich die Machtverteilung drastisch.
Die Entwickler benötigen in einem solchen Szenario zwingend extrem teure Lizenzen für saubere, rechtssichere Trainingsdaten. Individuelle Verträge mit Verlagen, Bildagenturen und Plattformen werden zur absoluten Pflicht für den Bau neuer KI-Modelle.
Solche enormen Summen können nur noch wenige Tech-Giganten aufbringen. Konzerne wie Google, Meta oder Microsoft verfügen über die tiefen Taschen und die bestehenden Daten-Ökosysteme, um sich die exklusiven Rechte zu sichern.
Kleine Startups, ambitionierte Forscher und die gesamte Open-Source-Community bleiben bei dieser Entwicklung auf der Strecke. Der Versuch, das Urheberrecht strenger durchzusetzen und die Kreativen zu schützen, zementiert paradoxerweise die absolute Vormachtstellung der größten Akteure auf dem Technologiemarkt.
Cheers!