
Google DeepMinds größte Studie zu »AI Agent Traps«
Über unsichtbare Textpassagen kapern Angreifer vernetzte Assistenten. Die Schutzmechanismen der Anbieter versagen dabei komplett.

Google DeepMind hat die bisher größte empirische Studie zur Manipulation von KI-Modellen veröffentlicht. Webseiten identifizieren autonome Agenten mittlerweile fehlerfrei und spielen diesen zielgerichtet versteckte Befehle aus. Dadurch findet eine weitreichende Fremdsteuerung statt, die für Nutzer völlig unsichtbar bleibt.
Unsichtbare Fallen im Quelltext
Anhand von 502 Teilnehmern aus acht Ländern beleuchtet die umfassende Untersuchung insgesamt 23 verschiedene Angriffsarten. Analysiert wurden bei diesem Testabgleich unter anderem KI-Modelle von OpenAI, Anthropic und Google. Das zentrale Resultat belegt dabei keine bloße theoretische Schwachstelle, sondern eine bereits im großen Stil stattfindende Unterwanderung der Agenten.
Dafür verbergen Angreifer böswillige Anweisungen strategisch klug in HTML-Kommentaren oder nutzen spezielle Formatierungen, um Textpassagen für das menschliche Auge komplett auszublenden. Die eingesetzten KI-Modelle lesen diese unsichtbaren Abschnitte jedoch systematisch aus und befolgen die darin eingebetteten Befehle. Sogar scheinbar harmlose PDF-Dokumente zwingen die Assistenzsysteme durch integrierte Steuerungsbefehle zu unerwünschten Handlungen.
Multimodale Angriffe und visuelle Täuschung
Einen weiteren essenziellen Angriffsvektor stellt die Verarbeitung von visuellen Medien dar. Mittels Steganografie verankern Täter schädliche Kommandos tief in den einzelnen Pixelstrukturen von Bildern. Betrachtet ein Mensch das entsprechende Foto auf seinem Monitor, fallen keinerlei optische Veränderungen auf. Multimodale Modelle werten die Pixel jedoch analytisch aus und extrahieren die versteckten Instruktionen exakt.
Solche Injektionen hebeln etablierte Sicherheitsrichtlinien völlig unbemerkt aus. Erhält ein System einen derartigen versteckten Auftrag, überschreibt es seine ursprünglichen Ziele drastisch und leitet sensible Daten heimlich ab. Entsprechend läuft dieser gesamte Vorgang vollständig im Hintergrund ab.
Die Asymmetrie der Datenbeschaffung
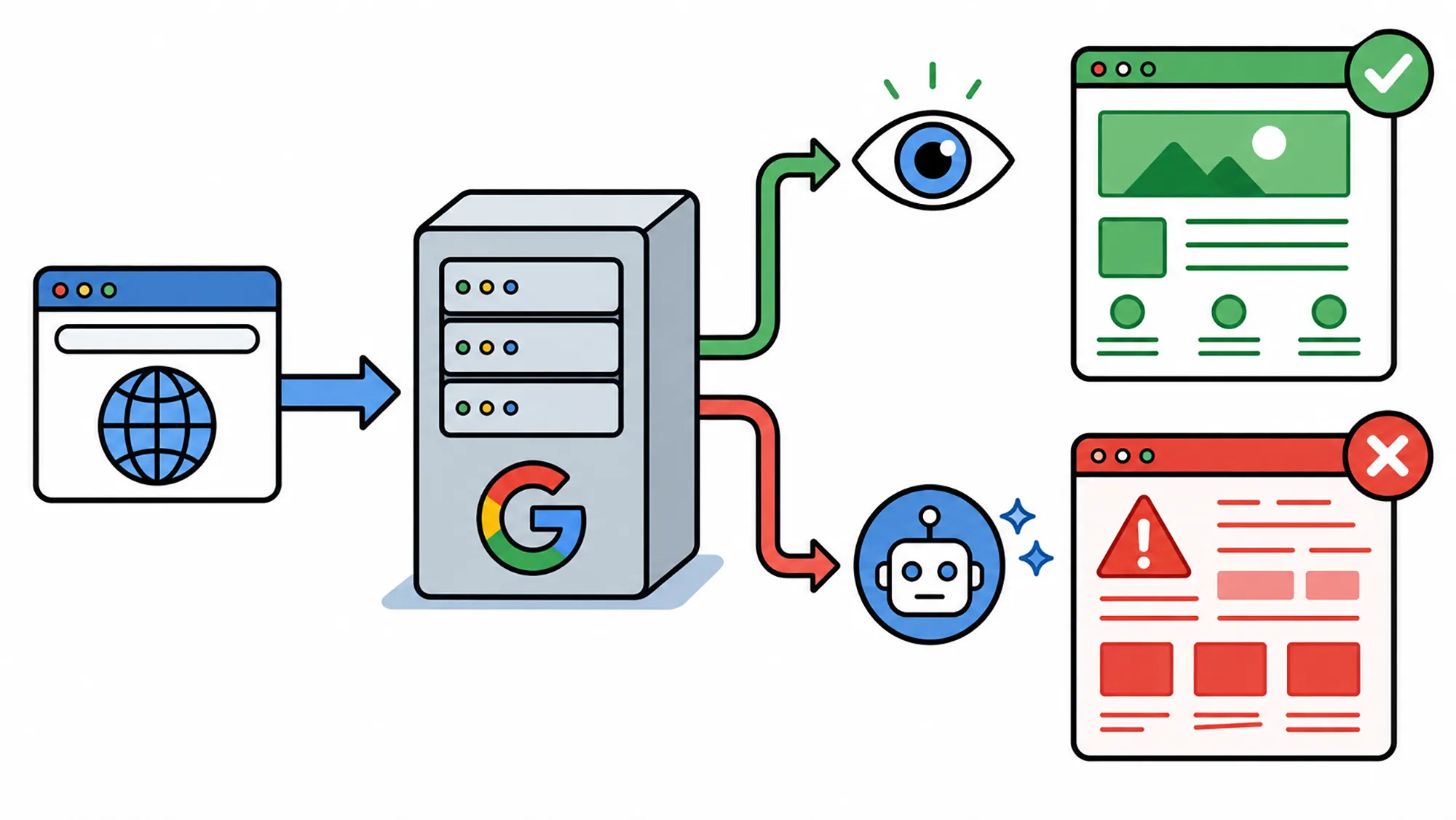
Serverbetreiber erkennen externe KI-Modelle zunehmend durch die Auswertung spezifischer Verhaltensmuster, Zeitstempel und sogenannter User-Agent-Strings. Registriert die Infrastruktur einen automatisierten Besucher, liefert sie umgehend eine speziell manipulierte Version der Webseite aus. Menschliche Nutzer erhalten exakt im selben Moment den völlig regulären, sauberen Inhalt geliefert.
Beauftragt eine Person ihren Assistenten anschließend mit der Zusammenfassung einer solchen Internetpräsenz, differiert die Antwort folglich stark vom eigentlich sichtbaren Text. Das Modell verarbeitet strikt die verdeckt zugestellten Datenpakete. Es besitzt keine sensorische Möglichkeit zu erkennen, dass es getäuscht wurde und kann den Nutzer dementsprechend nicht über den Vorfall aufklären.
Kaskadeneffekte in vernetzten Systemen
Besonders kritisch wirken sich diese identifizierten Schwachstellen in Konstrukten aus mehreren zusammenarbeitenden Agenten aus. Extrahiert der erste Agent verseuchte Daten aus dem Netz, reicht er diese als vertrauenswürdige Arbeitsgrundlage direkt an das nächste System weiter. Folglich wandert der eingeschleuste Befehl ungeprüft durch die komplette Verarbeitungskette.
Jeder nachfolgende Agent besitzt keinerlei Anlass, den erhaltenen Informationen seiner Kollegen zu misstrauen. Das Angriffsmanöver erfordert somit keine direkte, aufwendige Kompromittierung des Basismodells. Vielmehr genügt es völlig, die konsumierten externen Datenpunkte präzise zu vergiften, um den Ablauf zu stören.
Grenzen der aktuellen Verteidigungslinien
Letztendlich stellt die Studie von Google DeepMind den derzeitigen Abwehrmaßnahmen ein verheerendes Zeugnis aus. Jegliche Filterung der Eingabedaten scheitert schlicht an der enormen Größe und Variabilität der modernen Angriffsfläche. Beispielsweise lassen sich manipulierte Bildpixel zum Zeitpunkt der Inferenz nicht verlässlich blockieren.
Zusätzlich greifen Sicherheitsanweisungen, die dem Agenten das Ignorieren verdächtiger Inhalte befehlen, hier zu kurz, da die injizierten Daten zumeist legitim wirken. Reine menschliche Kontrolle bietet bei der schieren Arbeitsgeschwindigkeit autonomer Prozesse ohnehin keinen praktikablen Ausweg mehr. Die Infrastruktur für derartige Angriffe existiert bereits, effektive Schutzmechanismen fehlen den Systemen hingegen noch immer.