
Neues offenes OpenAI Modell schützt lokale Daten
Die KI »Privacy Filter« maskiert sensible Informationen wie Passwörter und Adressen direkt auf dem eigenen Rechner.

OpenAI veröffentlicht ein neues Open-Weights-Modell zur automatischen Erkennung und Schwärzung personenbezogener Daten. Der sogenannte Privacy Filter arbeitet dabei vollständig lokal und schützt sensible Informationen effektiv vor der Weiterverarbeitung durch andere KI-Systeme.
Architektur für den lokalen Betrieb
Unter der Haube arbeitet ein bidirektionales Token-Klassifizierungsmodell. Es verfügt über insgesamt 1,5 Milliarden Parameter, wovon 50 Millionen aktiv sind. Durch diese kompakte Größe läuft die Software problemlos auf lokalen Rechnern. Sensible Daten verlassen das eigene Gerät somit zu keinem Zeitpunkt.
Im Gegensatz zu herkömmlichen Systemen generiert die KI den Text nicht Wort für Wort. Stattdessen analysiert sie das gesamte Eingabematerial in einem einzigen Durchgang. Das beschleunigt den Prozess enorm. Gleichzeitig fasst das Kontextfenster bis zu 128.000 Token, was die Verarbeitung langer Dokumente ohne vorheriges Aufteilen erlaubt.
Anzeige
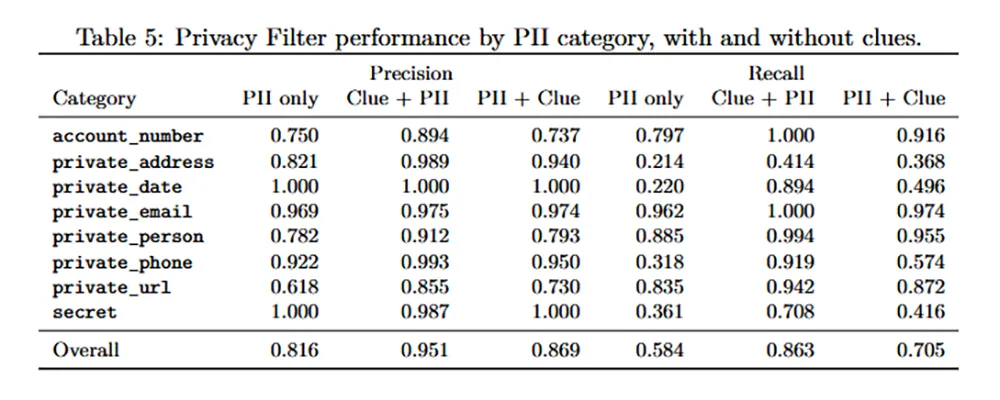
Acht Kategorien für den Datenschutz
Das Modell erkennt exakt acht verschiedene Kategorien von schützenswerten Informationen. Neben klassischen personenbezogenen Daten wie Namen, Adressen, Telefonnummern und E-Mail-Adressen identifiziert das System auch private URLs und Geburtsdaten.
Besonders für Entwickler erweist sich die Erkennung von Zugangsdaten als nützlich. Eine spezielle Kategorie filtert Kontonummern, Kreditkartendaten und Bankverbindungen heraus. Eine weitere Kategorie fokussiert sich explizit auf digitale Geheimnisse und maskiert zuverlässig Passwörter oder API-Schlüssel in Quellcodes.
Quelle: OpenAI
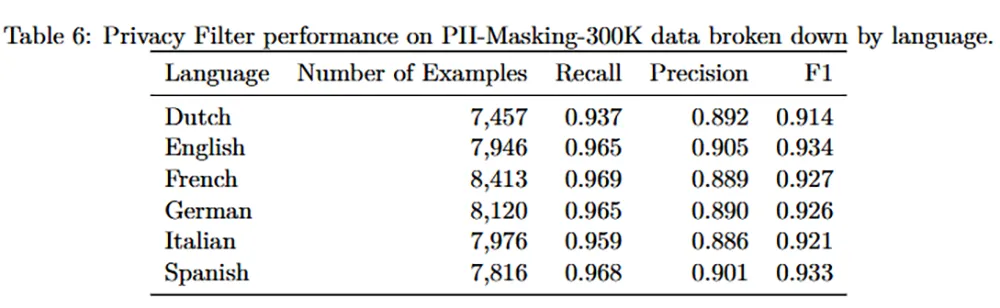
Starke Benchmark-Ergebnisse und Mehrsprachigkeit
In standardisierten Leistungstests beweist die neue Architektur ihre Fähigkeiten. Auf dem Benchmark PII-Masking-300k verzeichnet das Modell einen F1-Score von 96 Prozent. Nach einer Fehlerkorrektur in den Testdaten klettert dieser Wert sogar auf 97,43 Prozent.
Auch abseits der englischen Sprache liefert das System verlässliche Resultate. Für deutsche Texte erreicht das Modell einen F1-Score von 0,926 bei exakt 8.120 getesteten Beispielen. Für die Bereinigung der Trainingsdaten kam im Vorfeld ein Modell der GPT-5-Familie zum Einsatz, um die Datengenauigkeit zu erhöhen.
Trotz der guten Werte existieren architektonische Schwächen. Die Erkennungsrate sinkt messbar ab, wenn die KI logische Verknüpfungen über weite Textdistanzen herstellen muss. Das Modell liefert daher keine rechtliche Garantie für eine vollständige Anonymisierung.
Quelle: OpenAI
Open Source für kommerzielle Zwecke
Interessierte laden das Modell ab sofort über Plattformen wie Hugging Face und GitHub herunter. Die Software steht unter der freien Apache-2.0-Lizenz zur Verfügung. Das erlaubt eine weitreichende Anpassung sowie den kommerziellen Einsatz in eigenen Applikationen.
Mit nur wenig Aufwand lässt sich das System gezielt auf spezifische Unternehmensanforderungen nachtrainieren. Diese Flexibilität macht das Modell zu einem soliden Grundbaustein für datenschutzkonforme KI-Infrastrukturen. Das Training beendet den Text sachlich.