
TikTok fordert mit Seed 2.0 ChatGPT und Gemini heraus.
Mit den Varianten Pro, Lite und Mini deckt ByteDance unterschiedliche Anwendungsfälle von Softwareentwicklung bis Echtzeit-Übersetzung ab.

ByteDance hat mit Seed 2.0 eine neue Generation seiner großen Sprachmodelle veröffentlicht. Die Architektur erscheint in drei Varianten und verspricht Leistungsdaten auf dem Niveau aktueller Spitzenmodelle bei gleichzeitig drastisch gesunkenen Inferenzkosten.
Anzeige
Warum Seed 2.0 und Doubao 2.0 identisch sind
Hinter den Bezeichnungen Seed 2.0 und Doubao 2.0 verbirgt sich exakt dieselbe technische Basis. Während ByteDance den Namen Doubao vorrangig für den chinesischen Heimatmarkt und die eigenen Endkunden-Anwendungen nutzt, richtet sich die Marke Seed an die internationale Entwickler-Community. Das Unternehmen reagiert mit der neuen Generation auf den Trend zu agentenbasierter KI, bei der Modelle komplexe, mehrstufige Arbeitsabläufe autonom abarbeiten. KI-Agenten sollen künftig selbstständig Recherchen im Internet durchführen, externe Daten auslesen oder Dokumente in strukturierte Tabellen überführen.
Die Modellfamilie gliedert sich in die drei Abstufungen Pro, Lite und Mini. Diese Segmentierung ist branchenüblich und erlaubt es Entwicklern, je nach Anwendungsfall zwischen maximaler Leistung und minimaler Latenz zu wählen. Die Pro-Version zielt auf tiefgreifende Logik, die Lite-Version bildet den Allrounder für den Alltag, und die Mini-Version ist für hochfrequente Anfragen mit extrem kurzer Reaktionszeit konzipiert.
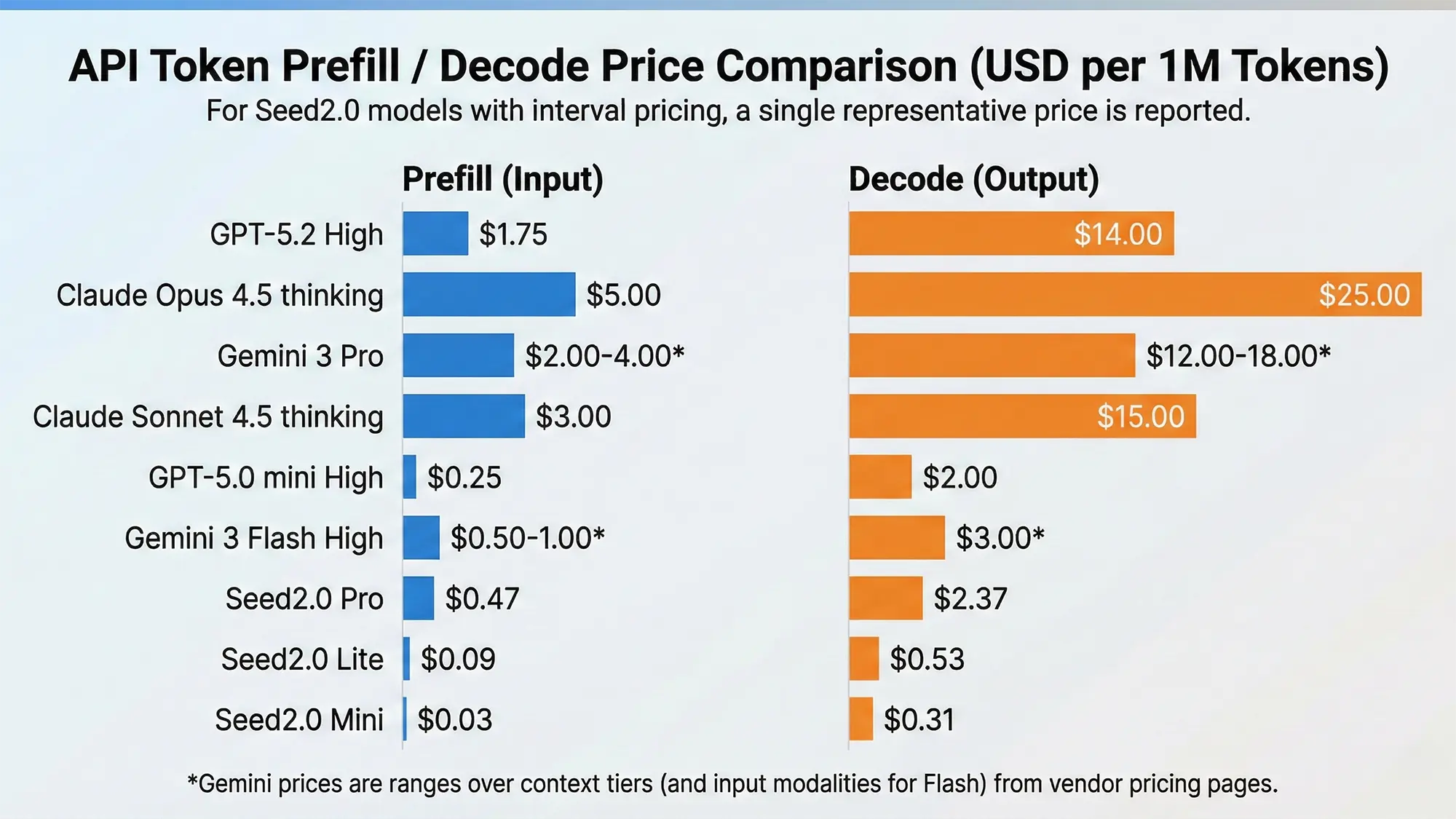
Im direkten Vergleich zu Konkurrenten wie OpenAI, Google oder Anthropic positioniert sich ByteDance über eine sehr aggressive Preisgestaltung. Das Ziel ist es, den Markt für API-Schnittstellen durch geringe Hardwarekosten bei gleichzeitig hoher Rechenleistung zu dominieren.
Quelle: all-ai.de
Seed 2.0 Pro: Architektur und Besonderheiten
Das Spitzenmodell Seed 2.0 Pro ist für tiefe logische Schlussfolgerungen und die Ausführung langer Aufgabenketten konzipiert. Die Architektur ist laut dem veröffentlichten Bericht darauf ausgelegt, multimodale Eingaben effizienter zu verarbeiten als die Vorgängergeneration. Ein zentrales Merkmal ist die Fähigkeit zur Test-Time-Compute-Skalierung, bei der das Modell dynamisch mehr Rechenzeit aufwendet und mehrere Lösungswege intern bewertet, bevor es ein Ergebnis ausgibt.
Ein Anwendungsbeispiel des Herstellers zeigt die multimodalen Fähigkeiten in Echtzeit. In einem Demonstrationsvideo wertet das Modell den Live-Feed einer Smartphone-Kamera aus, die eine Person beim Krafttraining im Fitnessstudio filmt. Die Software analysiert die Bewegungsabläufe, erkennt Fehlhaltungen und gibt über eine synthetische Sprachausgabe direkte Korrekturanweisungen, ähnlich einem menschlichen Trainer. In der Praxis muss sich zeigen, wie fehlerfrei diese Bildauswertung bei schlechten Lichtverhältnissen oder komplexen Übungen funktioniert.
Quelle: ByteDance
Ein weiteres Beispiel demonstriert die automatisierte Webentwicklung durch das Modell. Auf Basis einer groben Textbeschreibung generiert die KI-Schnittstelle nicht nur den zugrundeliegenden HTML- und CSS-Code, sondern erstellt ein vollständiges, visuell ansprechendes Seitenlayout. Der Algorithmus platziert dabei selbstständig Platzhalter für Bilder, strukturiert Navigationsmenüs und passt das Design an mobile Endgeräte an. Entwickler lagern damit zeitintensive Routineaufgaben aus, müssen den generierten Code jedoch zwingend auf Sicherheitslücken und Effizienz prüfen.
Aus einem einfachen Prompt mit 3 Sätzen ist folgende Webseite voll funktionsfähig enstanden:
Quelle: bytedance
Seed 2.0 Pro im Benchmark-Vergleich
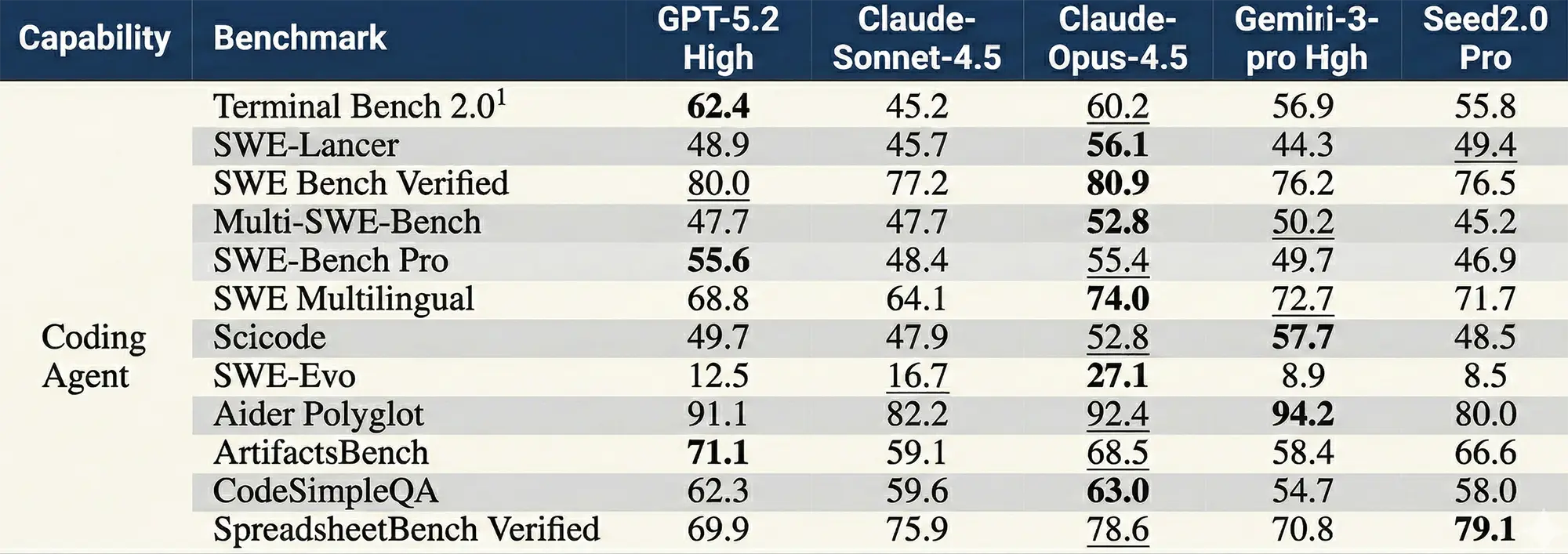
In den Disziplinen Programmierung und autonome Agenten ordnet sich Seed 2.0 Pro knapp hinter den absoluten Spitzenreitern ein. Beim SWE-Bench (Verified), der die Lösung echter Softwareprobleme misst, erreicht das Modell 76,5 Prozent und schlägt damit Googles Gemini 3 Pro (76,2 Prozent) hauchdünn, bleibt aber hinter GPT-5.2 (80,0 Prozent) zurück. Bei der Ausführung von Befehlsketten in Kommandozeilen-Umgebungen, abgebildet durch den Terminal-Benchmark, zeigt sich ein ähnliches Bild. Hier erzielt die ByteDance-KI solide 55,8 Prozent, muss sich jedoch sowohl Gemini 3 Pro (56,9 Prozent) als auch dem Spitzenreiter GPT-5.2 (62,4 Prozent) geschlagen geben.
Quelle: bytedance
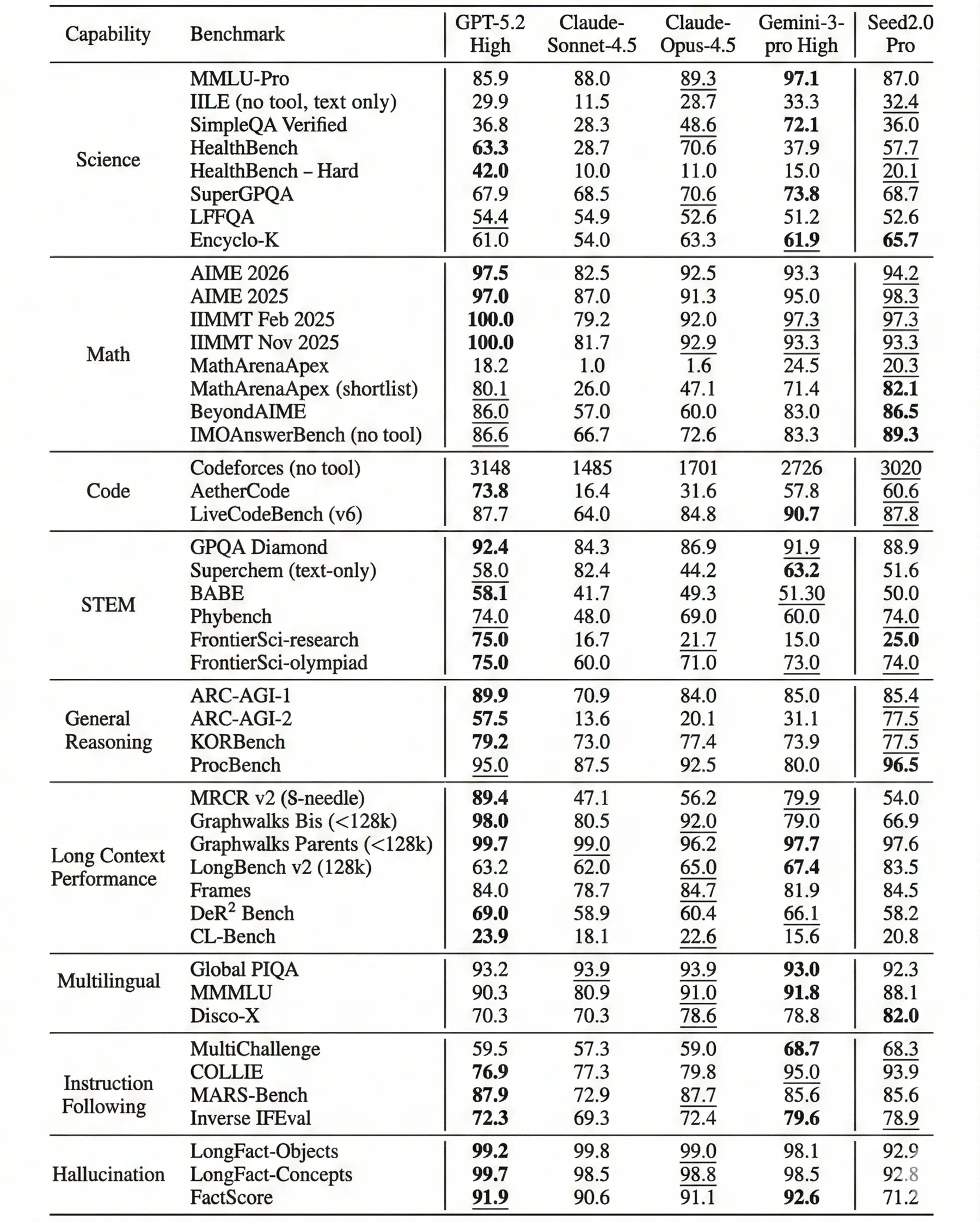
Bei allgemeinen Leistungstests für Naturwissenschaften und Mathematik liefert das Modell ein gemischtes, aber durchweg hohes Niveau. In der Disziplin Science (MMLU-Pro) erreicht Seed 2.0 Pro 87,0 Prozent und übertrifft damit GPT-5.2 (85,9 Prozent), wird jedoch von Gemini 3 Pro mit herausragenden 97,1 Prozent deutlich distanziert. Ein anderes Kräfteverhältnis zeigt sich bei anspruchsvollen Mathematik-Prüfungen wie dem AIME 2026. Dort positioniert sich das ByteDance-System mit 94,2 Prozent knapp vor Gemini 3 Pro (93,3 Prozent), während OpenAI mit 97,5 Prozent den Referenzwert in diesem Testfeld vorgibt.
Auch sonst können die Benchmarks größtenteils überzeugen:
Quelle: bytedance
Seed 2.0 Lite: Der Kompromiss aus Leistung und Kosten
Die Lite-Variante fungiert als Standardmodell für die meisten kommerziellen Anwendungen. Sie bietet einen Mittelweg aus Verarbeitungsgeschwindigkeit und logischer Tiefe. ByteDance gibt an, dass Seed 2.0 Lite die Gesamtleistung des bisherigen Hauptmodells Doubao 1.8 übersteigt, dabei aber deutlich weniger Rechenressourcen für die Inferenz benötigt.
Anzeige
In den veröffentlichten Benchmarks zeigt das Lite-Modell ein differenziertes Leistungsbild, besonders bei visuell gestützten Aufgaben. Beim Test MathVista, der das Verständnis von Diagrammen und mathematischen Grafiken prüft, erreicht Seed 2.0 Lite starke 89,0 Prozent. Damit liegt die kleinere Architektur fast exakt auf dem Niveau der hauseigenen Pro-Version (89,8 Prozent) sowie von Googles Gemini 3 Pro (89,8 Prozent) und übertrifft das Konkurrenzmodell GPT-5.2 (83,1 Prozent) messbar. Diese Zahlen signalisieren, dass das Modell bei klar strukturierten mathematischen Mustern kaum an Präzision einbüßt.
Bei komplexeren visuellen Logikrätseln, wie sie der Benchmark ARC-AGI-2-Image abfragt, sinkt die Genauigkeit erwartungsgemäß. Hier erzielt das Lite-Modell 28,3 Prozent und ordnet sich mit deutlichem Abstand hinter Seed 2.0 Pro (43,3 Prozent) und dem Spitzenreiter GPT-5.2 (54,4 Prozent) ein. Bemerkenswert ist in den Datensätzen jedoch, dass die ByteDance-KI in diesem spezifischen Testfeld das etablierte Gemini 3 Pro (21,5 Prozent) hinter sich lässt. Die Ergebnisse verdeutlichen, dass die Lite-Version für alltägliche Aufgaben ausreichend dimensioniert ist, bei tiefgreifender, mehrstufiger Bildlogik jedoch an ihre Systemgrenzen stößt.
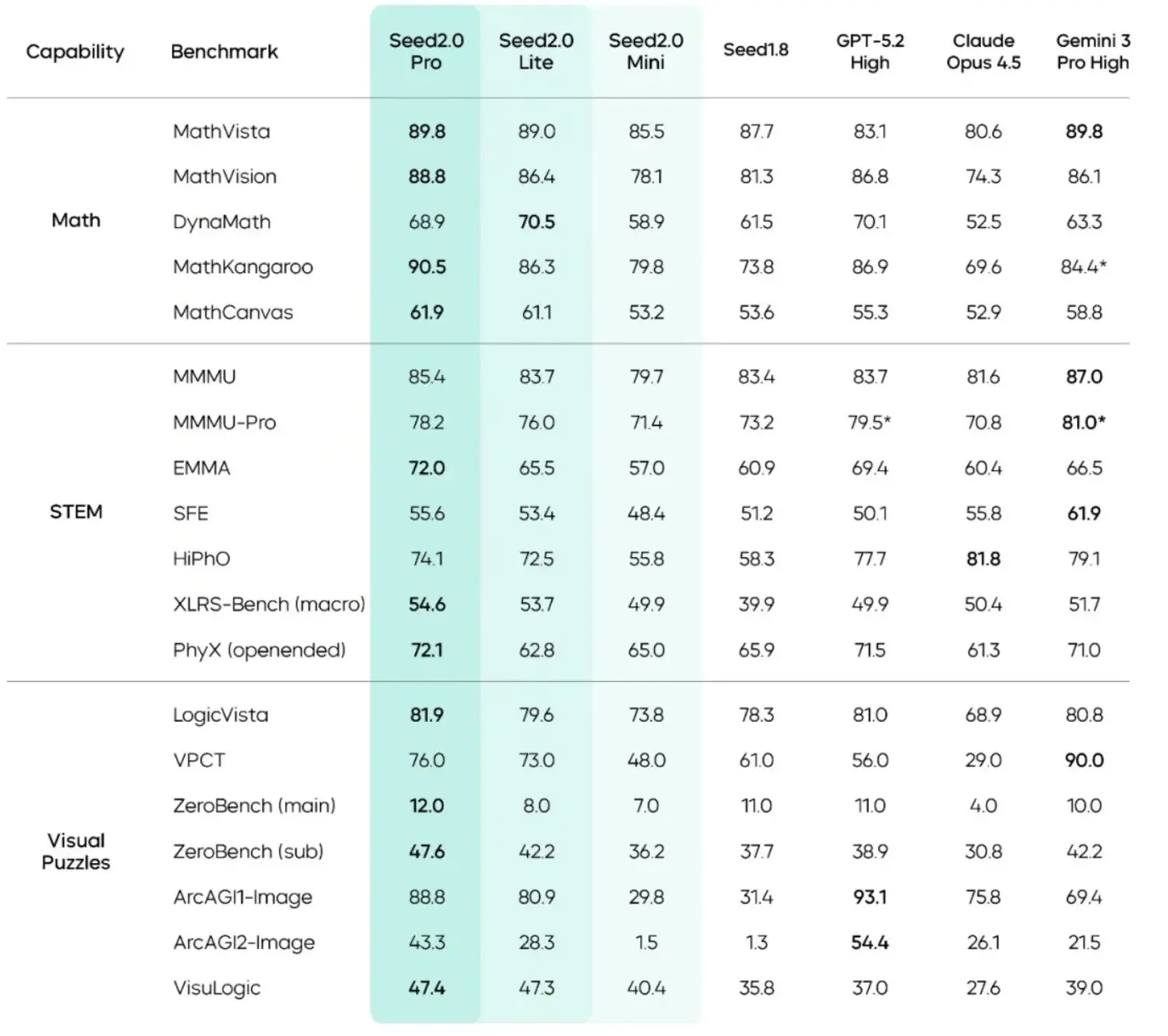
Quelle: bytedance
Seed 2.0 Mini und seine Benchmark-Ergebnisse
Für Szenarien, in denen Millisekunden entscheiden, hat ByteDance das Seed 2.0 Mini entwickelt. Dieses Modell ist strikt auf geringe Latenz und hohe Parallelität getrimmt. Die Architektur zielt auf Echtzeit-Übersetzungen, einfache Klassifizierungsaufgaben und die blitzschnelle Autovervollständigung von Code oder Texten ab.
Ein Blick auf die konkreten Leistungsdaten offenbart ein gemischtes Bild: Bei anspruchsvollen mathematischen Problemen, gemessen im AIME 2026 Benchmark, erzielt das Seed 2.0 Mini einen soliden Wert von 86,7 Punkten. Damit liegt es zwar in Schlagdistanz zu seinem größeren Bruder, dem Seed 2.0 Lite (88,3), muss sich aber den direkten Konkurrenten GPT-5-mini High (92,5) und Gemini-3-Flash High (93,3) geschlagen geben.
Anzeige
Überraschend stark zeigt sich das Mini-Modell hingegen beim Programmieren. Im LiveCodeBench (v6) übertrifft das Seed 2.0 Mini mit 64,1 Punkten sogar das GPT-5-mini High (62,6). Auch wenn Gemini-3-Flash High (84,7) und das etwas größere Seed 2.0 Lite (81,7) hier noch einmal in einer ganz anderen Liga spielen, ist das für ein derart auf Latenz getrimmtes Modell ein beachtlicher Wert.
Trotz der sehr hohen Kosteneffizienz – ByteDance beziffert den Preis für eine Million generierte Token auf lediglich 0,31$ – müssen Serverbetreiber Kompromisse bei der Zuverlässigkeit eingehen. Dass die Fehleranfälligkeit bei dieser reduzierten Architektur signifikant ansteigt, belegt der FactScore-Benchmark, der die Neigung zu Halluzinationen und Faktenfehlern misst. Hier bricht das Seed 2.0 Mini mit lediglich 50,4 Punkten massiv ein.
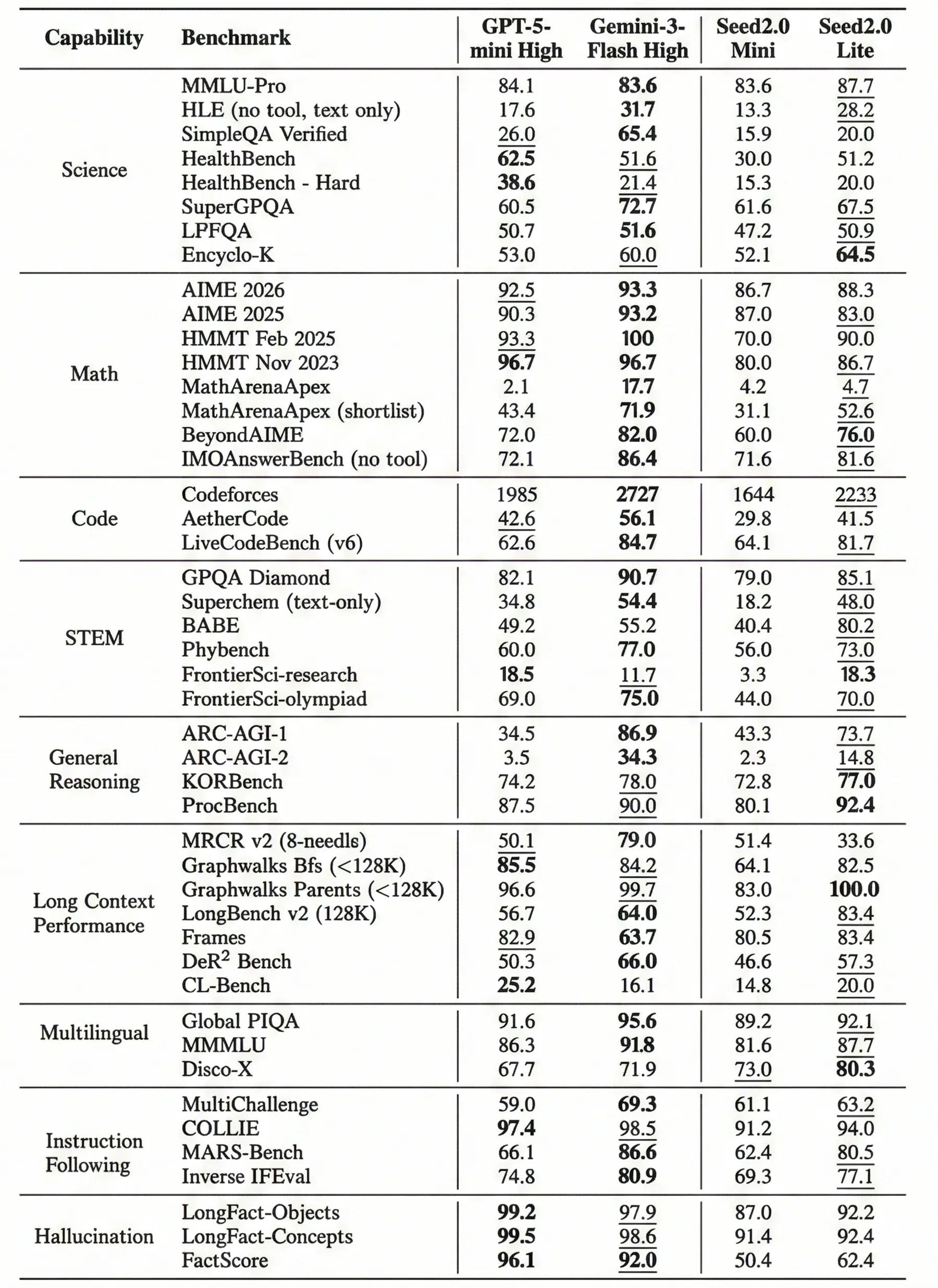
Quelle: bytedance
Spezialisierte Modelle und das Ökosystem
Neben den Allzweckmodellen listet die Modellübersicht der Seed-Familie auch spezialisierte Varianten wie "Doubao-Seed-Code" auf. Das offizielle Datenblatt bestätigt die strategische Entwicklung dedizierter "Seed-Coder"-Modelle, die gezielt auf die Verarbeitung von Quellcode nachtrainiert wurden. Moderne Softwareentwicklung stützt sich zunehmend auf solche Assistenten, um Abhängigkeiten in großen Projekten zu analysieren und Syntaxfehler frühzeitig zu erkennen.
Darüber hinaus deutet die veröffentlichte Dokumentation auf eine tiefere Verzahnung im Bereich der generativen Medien hin. Sprachmodelle wie Seed 2.0 dienen zunehmend als logische Steuerungszentrale, um multimodale Eingaben zu verarbeiten und komplexe Systeme für Bild- oder Videogenerierung zu koordinieren.
Damit erscheint nach den aktuellen Versionen von GLM-5 und MiniMax 2.5 innerhalb weniger Tage das dritte sehr starke und günstige chinesische Modell auf dem Markt.
