
GPT-5.5 ist stärker und teurer als Claude Opus
OpenAI verspricht effizientere Arbeitsabläufe, weniger Tokenverbrauch, zieht dafür aber die Preise enorm an.

OpenAI startet GPT-5.5 und rückt damit ein Modell ins Zentrum, das spürbar mehr Arbeit auf dem Computer selbstständig übernehmen soll. Neu ist vor allem die Kombination aus höherer Leistung, ähnlicher Latenz wie GPT-5.4 und deutlich stärkerem Fokus auf agentische Aufgaben.
Unabhängige Benchmarks
Auch jenseits der von OpenAI veröffentlichten Einzeltests fällt GPT-5.5 in externen Auswertungen stark auf. Im Artificial Analysis Intelligence Index liegt das Modell mit 60 Punkten vor Claude Opus 4.7 und Gemini 3 Pro Preview, die beide auf 57 Punkte kommen.
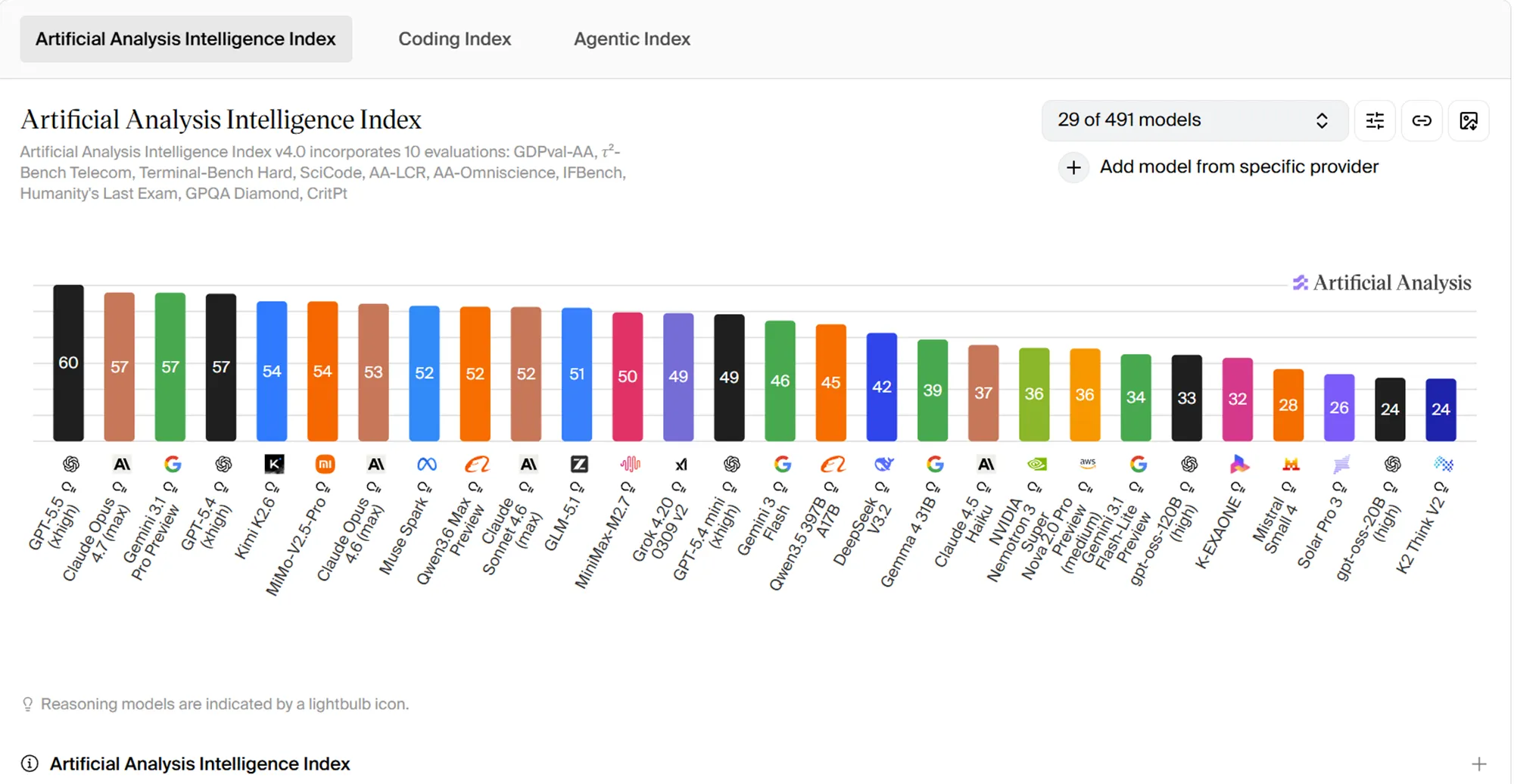
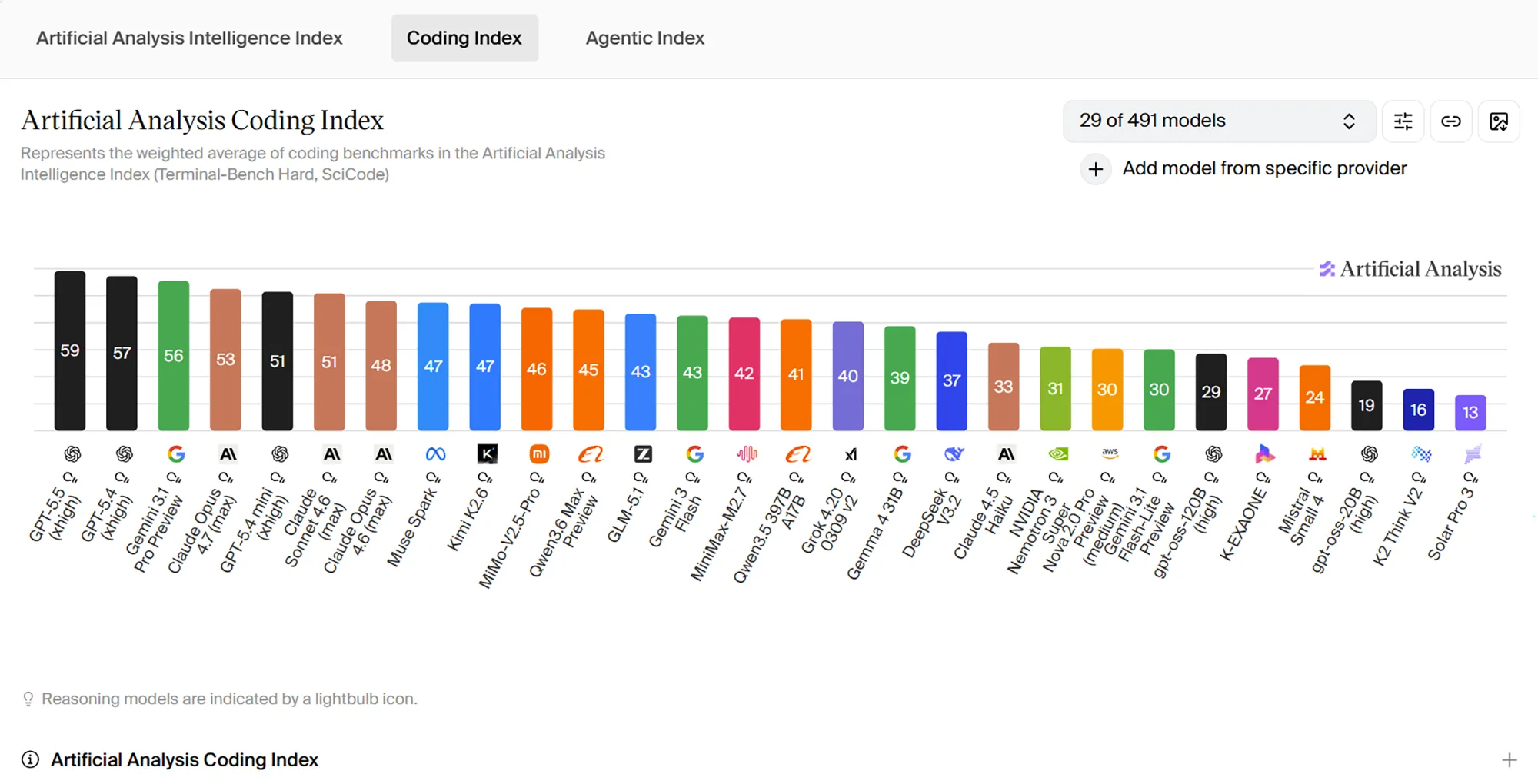
Im Coding Index zeigt sich ein ähnlich klares Bild. Dort erreicht GPT-5.5 59 Punkte und setzt sich damit knapp vor GPT-5.4 mit 57 Punkten sowie vor Gemini 3.1 Pro Preview mit 56 Punkten. Für OpenAI ist das besonders relevant, weil genau dieser Bereich zu den wichtigsten Einsatzfeldern von GPT-5.5 gehört und der Vorsprung hier nicht nur in internen, sondern auch in unabhängigen Benchmarks sichtbar wird.
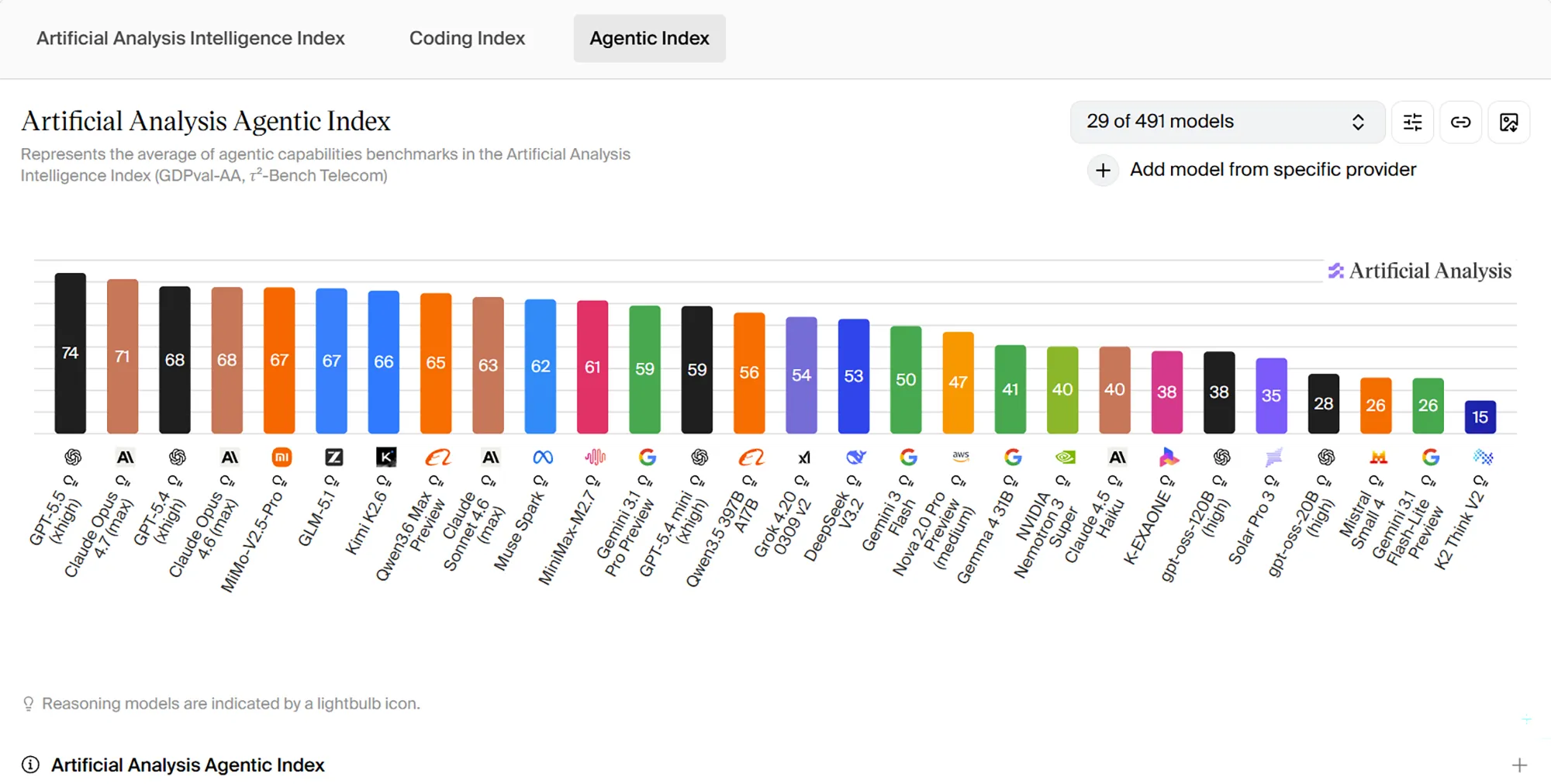
Noch interessanter ist der Agentic Index, der stärker auf mehrstufige, ausführungsnahe Aufgaben zielt. GPT-5.5 kommt hier auf 74 Punkte und liegt damit vor Claude Opus 4.7 mit 71 sowie deutlich vor GPT-5.4 mit 68 Punkten. Gerade diese Grafik stützt OpenAIs Kernthese, dass GPT-5.5 nicht nur einzelne Antworten verbessert, sondern komplexe Arbeitsabläufe mit Tools, Planung und Ausführung konsistenter bewältigt.
Was GPT-5.5 von GPT-5.4 absetzt
OpenAI beschreibt GPT-5.5 als bislang smartestes und intuitivstes Modell des Hauses. Gemeint ist damit nicht nur bessere Textqualität, sondern vor allem mehr Ausdauer bei komplexen Aufgaben über mehrere Schritte hinweg: recherchieren, Tools nutzen, Ergebnisse prüfen, Dokumente erstellen, Software bedienen und einen Auftrag bis zum Ende ausführen.
Genau dort setzt auch die Positionierung an. GPT-5.5 soll unklare, mehrteilige Prompts besser verstehen und weniger eng geführt werden müssen. Statt jeden Schritt vorzugeben, reicht laut OpenAI häufiger ein grober Arbeitsauftrag.
Die Tabellen stützen diesen Anspruch in vielen praktischen Disziplinen. Besonders deutlich fällt der Sprung bei ARC-AGI-2 aus, wo GPT-5.5 auf 85,0 Prozent kommt, nach 73,3 Prozent für GPT-5.4. Auf ARC-AGI-1 steigt das Modell von 93,7 auf 95,0 Prozent.

Anzeige
Stärker bei Coding, aber nicht überall vorn
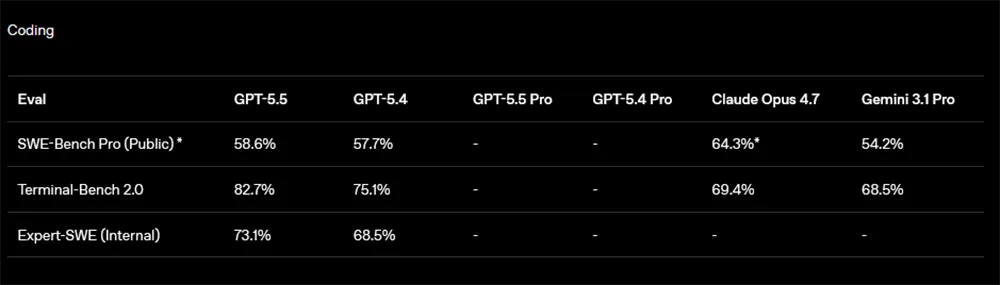
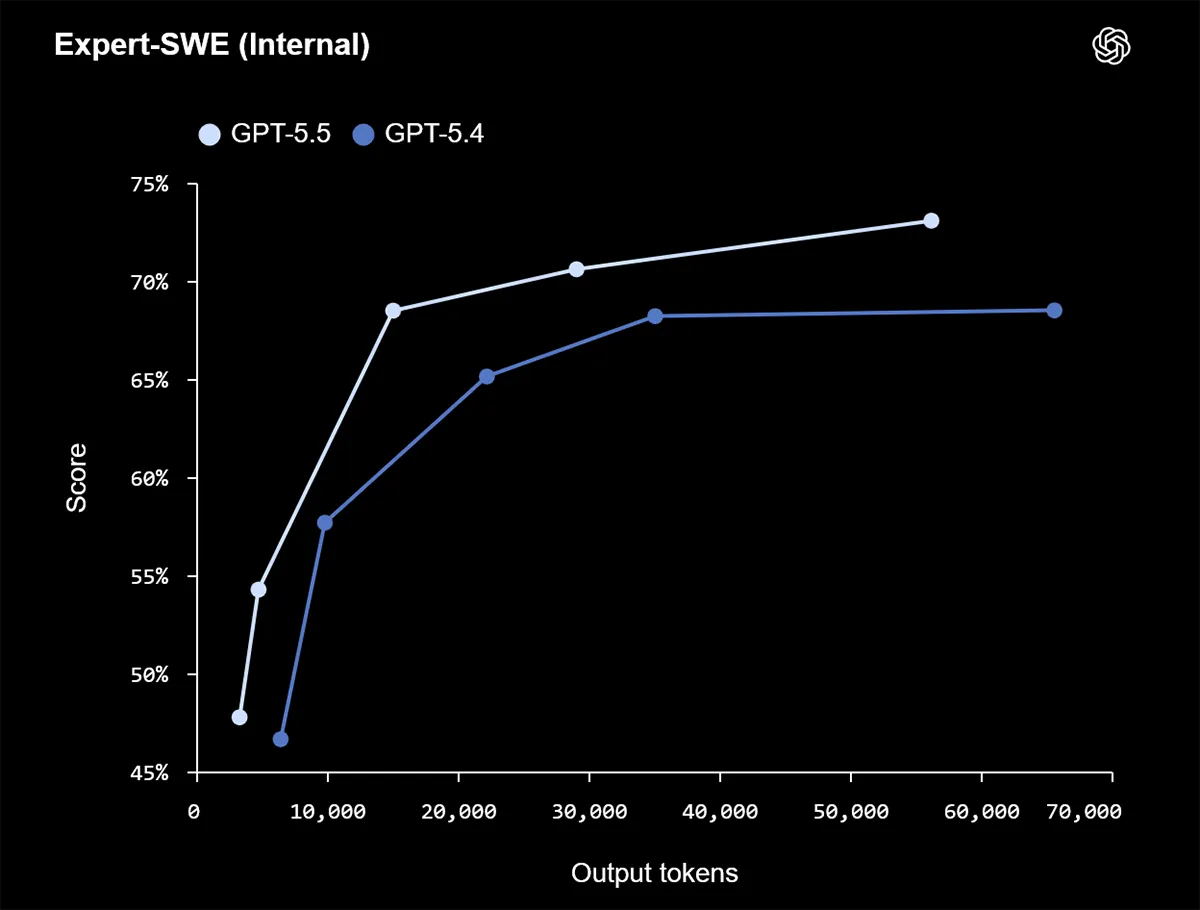
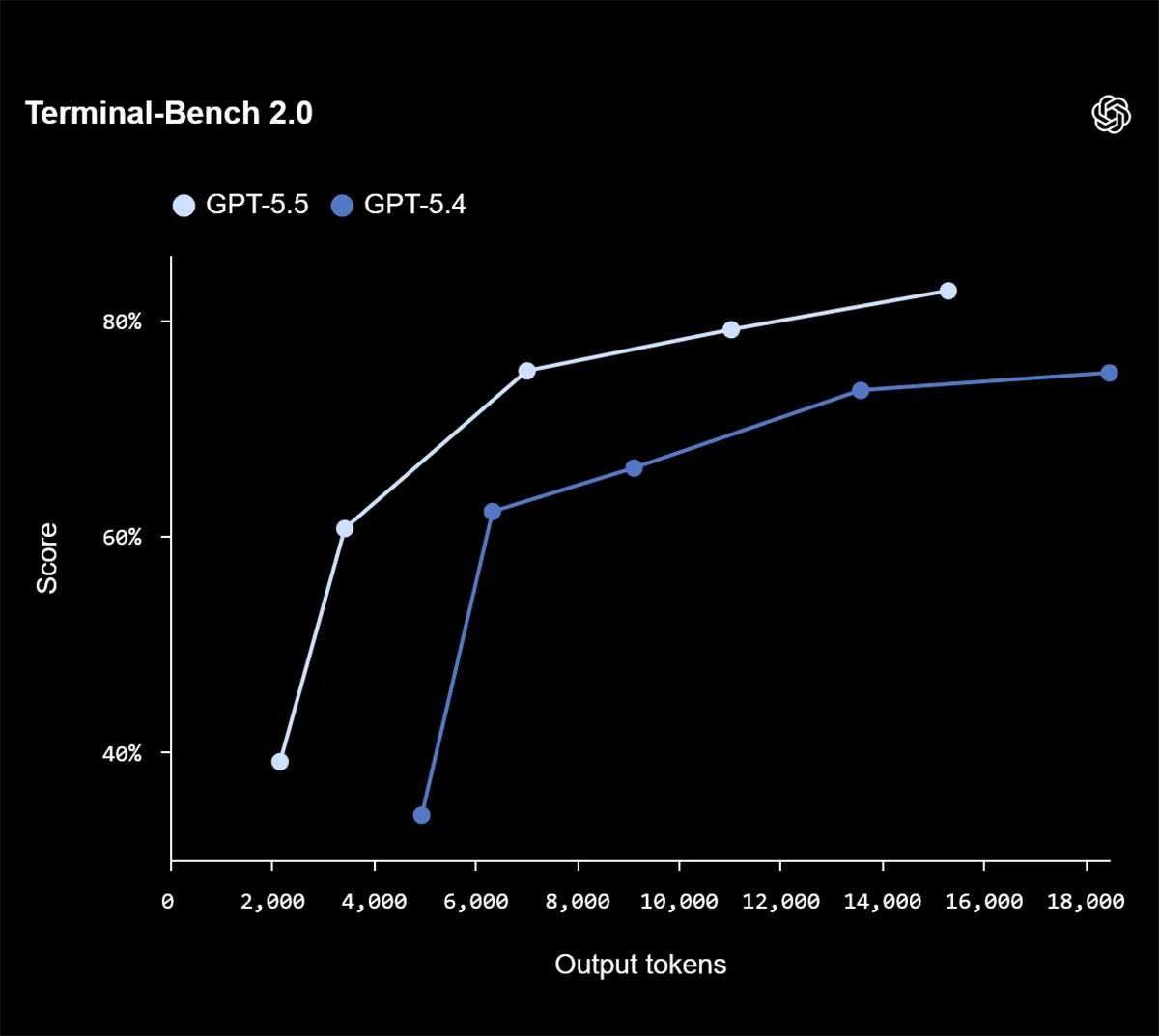
Im Coding legt GPT-5.5 sichtbar zu. Auf Terminal-Bench 2.0 erreicht das Modell 82,7 Prozent und verbessert sich damit um 7,6 Punkte gegenüber GPT-5.4. Auf dem internen Expert-SWE steigt der Wert von 68,5 auf 73,1 Prozent. Auch auf SWE-Bench Pro gewinnt GPT-5.5 leicht auf 58,6 Prozent.
Trotzdem ist das Feld nicht komplett abgeräumt. Auf SWE-Bench Pro liegt Claude Opus 4.7 mit 64,3 Prozent vor GPT-5.5. OpenAI verweist zwar auf Hinweise zu möglicher Memorization bei einem Teil dieser Aufgaben, doch am reinen Tabellenwert ändert das zunächst nichts.
Auffällig ist außerdem die Effizienz. Mehrere Diagramme zeigen, dass GPT-5.5 seine besseren Resultate häufig mit weniger Output-Tokens erreicht als GPT-5.4. OpenAI verbindet genau damit den Anspruch, dass das Modell nicht nur stärker, sondern im Alltag auch wirtschaftlicher arbeitet. Aber zu den Preisen am Ende mehr.
Knowledge Work, Tools und Computer Use
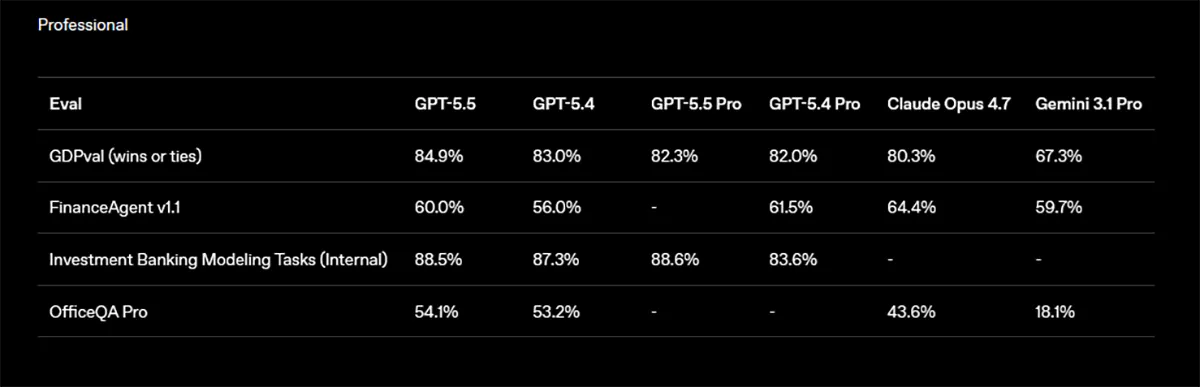
Jenseits von Coding zielt GPT-5.5 klar auf klassische Wissensarbeit. Auf GDPval, einem Benchmark für gut spezifizierte Aufgaben über 44 Berufe, kommt das Modell auf 84,9 Prozent. GPT-5.4 liegt bei 83,0 Prozent, Claude Opus 4.7 bei 80,3 Prozent und Gemini 3.1 Pro bei 67,3 Prozent.
Auch bei echter Computerbedienung zeigt sich ein kleiner, aber wichtiger Fortschritt. Auf OSWorld-Verified erreicht GPT-5.5 78,7 Prozent, GPT-5.4 kommt auf 75,0 Prozent. Bei MMMU Pro bleibt der Abstand kleiner: ohne Tools liegen GPT-5.5 und GPT-5.4 beide bei 81,2 Prozent, mit Tools steigt GPT-5.5 auf 83,2 Prozent.

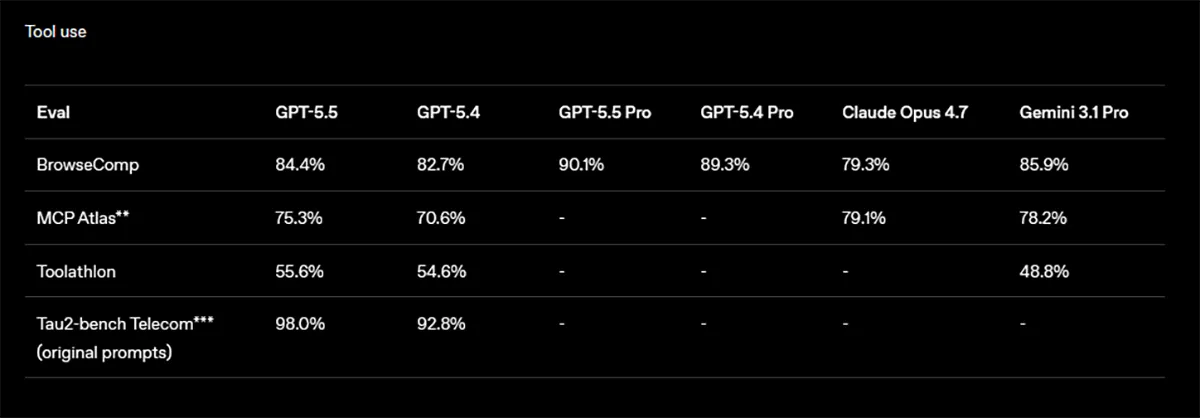
Interessant ist zudem der Bereich Tool Use. Auf BrowseComp erzielt GPT-5.5 84,4 Prozent, GPT-5.5 Pro 90,1 Prozent. Bei Tau2-bench Telecom springt GPT-5.5 auf 98,0 Prozent, während GPT-5.4 bei 92,8 Prozent bleibt. Genau diese Werte passen zu OpenAIs Kernthese: Das Modell versteht Absicht besser und kommt mit weniger Umwegen zum Ziel.
Wissenschaftliche Analyse und Cybersecurity
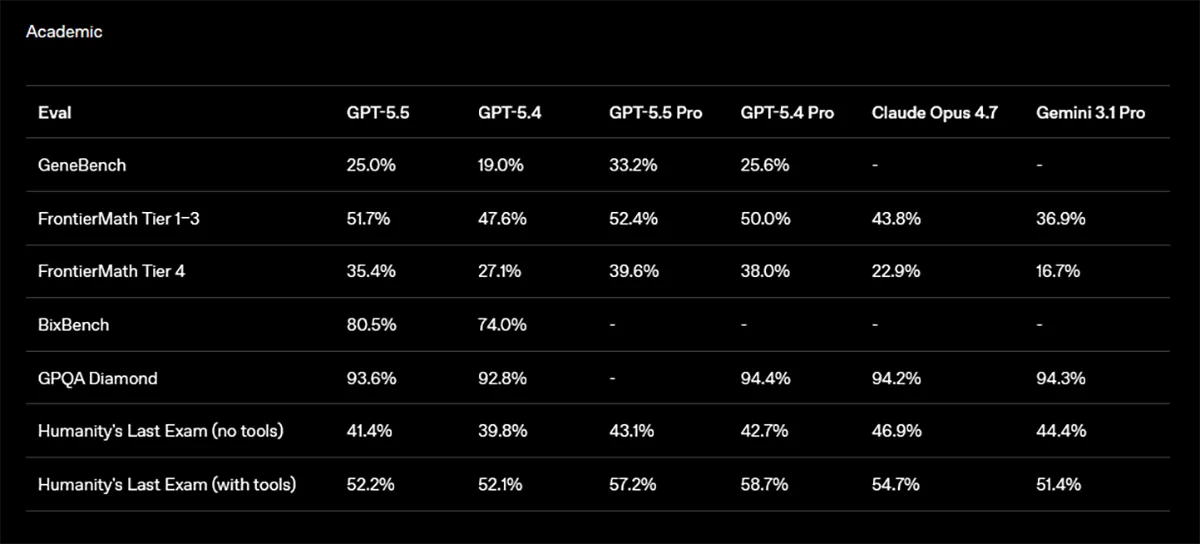
Bei wissenschaftlichen Workflows wirkt GPT-5.5 ebenfalls stärker. Auf GeneBench steigt das Basismodell von 19,0 auf 25,0 Prozent, GPT-5.5 Pro erreicht 33,2 Prozent. Auf BixBench wächst der Wert von 74,0 auf 80,5 Prozent. FrontierMath Tier 4 verbessert sich von 27,1 auf 35,4 Prozent.
Ganz vorne liegt GPT-5.5 jedoch auch hier nicht durchgehend. Auf GPQA Diamond erreicht es 93,6 Prozent, während GPT-5.4 Pro mit 94,4 Prozent knapp davor liegt. Bei Humanity’s Last Exam bleibt Claude Opus 4.7 ohne Tools mit 46,9 Prozent vor GPT-5.5 mit 41,4 Prozent.
Im Bereich Cybersecurity meldet OpenAI ebenfalls Fortschritte. Auf CyberGym steigt GPT-5.5 von 79,0 auf 81,8 Prozent. Bei den internen Capture-the-Flags-Challenges wächst der Wert von 83,7 auf 88,1 Prozent. Gleichzeitig stuft OpenAI die Bio- und Cyberfähigkeiten von GPT-5.5 im Preparedness Framework als High ein und verschärft die Schutzmaßnahmen.

Preise, Verfügbarkeit und der Haken
GPT-5.5 wird laut OpenAI jetzt in ChatGPT und Codex für Plus, Pro, Business und Enterprise ausgerollt. GPT-5.5 Pro bleibt zunächst Pro-, Business- und Enterprise-Kunden vorbehalten. Für die API kündigt OpenAI einen baldigen Start an.
Preislich wird es deutlich teurer. GPT-5.5 soll in der API 5 Dollar pro 1 Million Input-Tokens und 30 Dollar pro 1 Million Output-Tokens kosten. Für GPT-5.5 Pro nennt OpenAI 30 Dollar pro 1 Million Input-Tokens und 180 Dollar pro 1 Million Output-Tokens.
Damit liegt vor allem die Pro-Variante in einer Liga, die nur für anspruchsvolle Einsätze plausibel wirkt. OpenAI hält dagegen, dass GPT-5.5 weniger Tokens verbraucht und dadurch mehr Arbeit pro Dollar erledigen soll. Genau diese Abwägung entscheidet am Ende darüber, ob GPT-5.5 nur ein stärkeres Modell ist oder tatsächlich der produktivere Nachfolger von GPT-5.4.