Cohere Transcribe: Neues KI-Modell schlägt OpenAI Whisper
Das neue Open-Weights-Modell verarbeitet Audio deutlich schneller als die Konkurrenz. Es unterstützt 14 Sprachen bei geringer Fehlerrate.

Cohere veröffentlicht mit Cohere Transcribe ein neues KI-Modell für die hochpräzise Spracherkennung. Das Open-Weights-Modell mit zwei Milliarden Parametern schlägt Konkurrenten wie OpenAI Whisper Large v3 bei Geschwindigkeit sowie Genauigkeit.
Technische Basis und Vielsprachigkeit
Das Modell nutzt eine Conformer-basierte Encoder-Decoder-Architektur. Dabei extrahiert ein großer Conformer-Encoder die akustischen Repräsentationen. Ein kompakter Transformer-Decoder übernimmt im Anschluss die Generierung der Token. Entwickler erhalten über die Apache 2.0 Lizenz freien Zugriff auf die Gewichte.
Das Training erfolgte komplett von Grund auf neu. Das System unterstützt insgesamt 14 Sprachen aus verschiedenen Sprachfamilien. Neben europäischen Vertretern wie Deutsch, Englisch, Spanisch und Polnisch deckt das KI-Modell auch Mandarin, Japanisch, Koreanisch, Vietnamesisch und Arabisch ab.
Anzeige
Maximale Geschwindigkeit bei geringer Fehlerrate
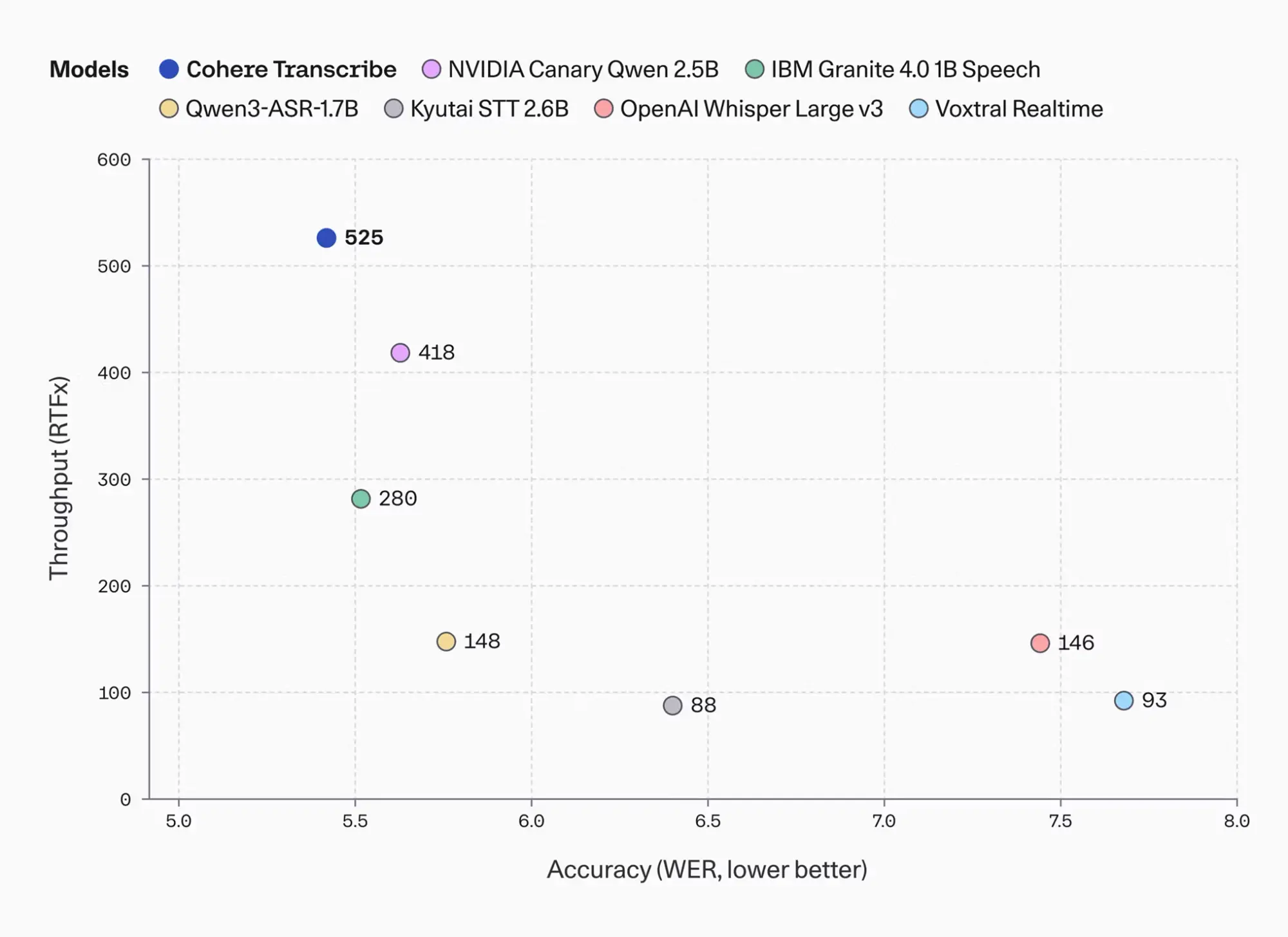
Die Testergebnisse zeigen einen extrem hohen Durchsatz von 525 RTFx. Cohere Transcribe deklassiert damit direkte Mitbewerber deutlich. Das NVIDIA Canary Qwen 2.5B erreicht 418 RTFx, während OpenAI Whisper Large v3 bei lediglich 146 RTFx landet.
Quelle: Cohere
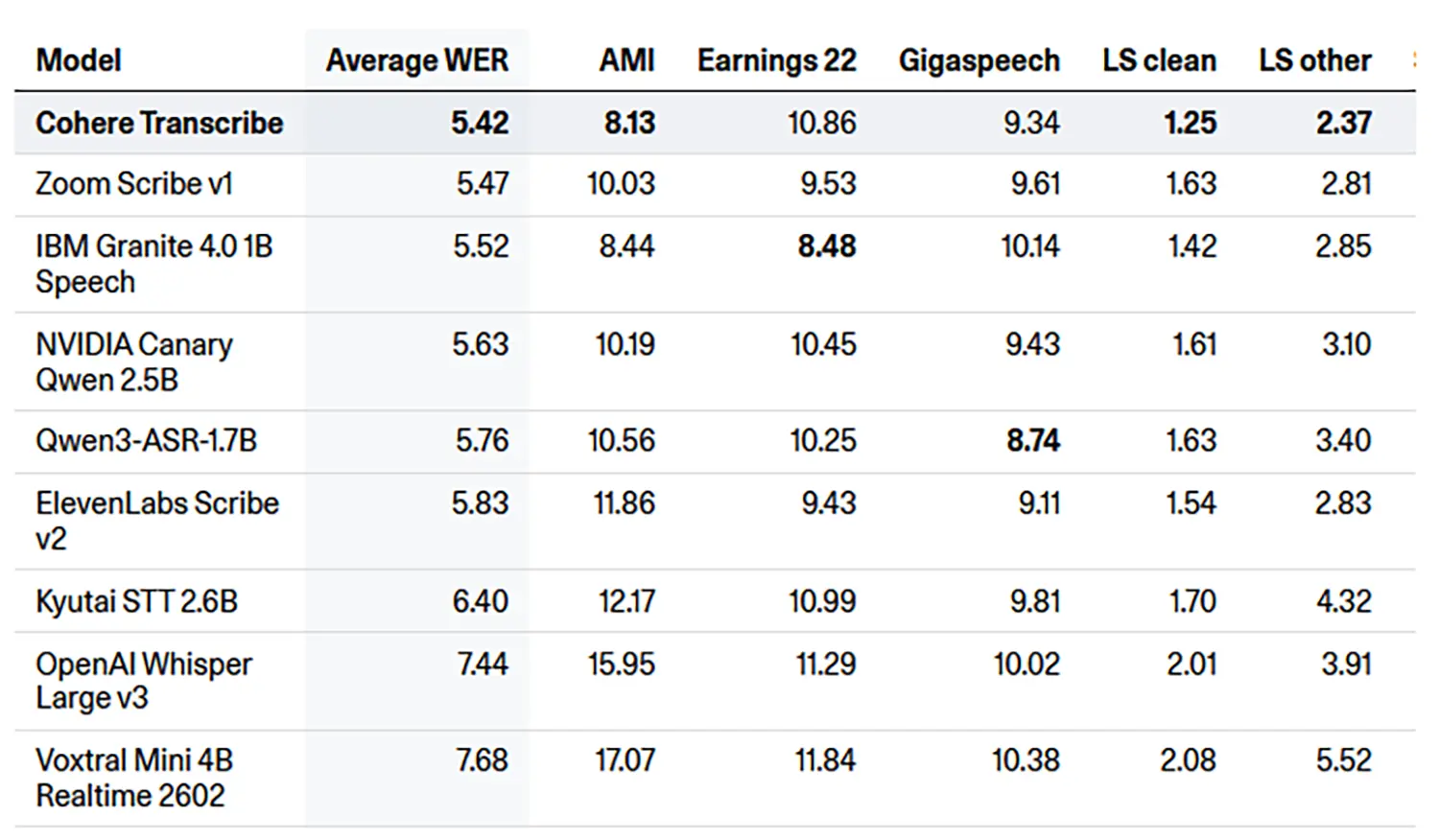
Gleichzeitig liefert das Modell die höchste Genauigkeit im Testfeld. Die durchschnittliche Wortfehlerrate (WER) liegt bei einem Bestwert von 5.42. Auf den Plätzen folgen Zoom Scribe v1 mit 5.47 und IBM Granite 4.0 1B Speech mit 5.52. OpenAI Whisper Large v3 fällt mit einer WER von 7.44 stark ab.
Bei spezifischen Datensätzen zeigt das Modell konstante Leistungen. Im Bereich "LS clean" erreicht es eine sehr niedrige WER von 1.25. Bei komplexeren "Earnings 22" Audiodaten erzielt es einen Wert von 10.86.
Quelle: Cohere
Direkte Duelle und internationale Leistung
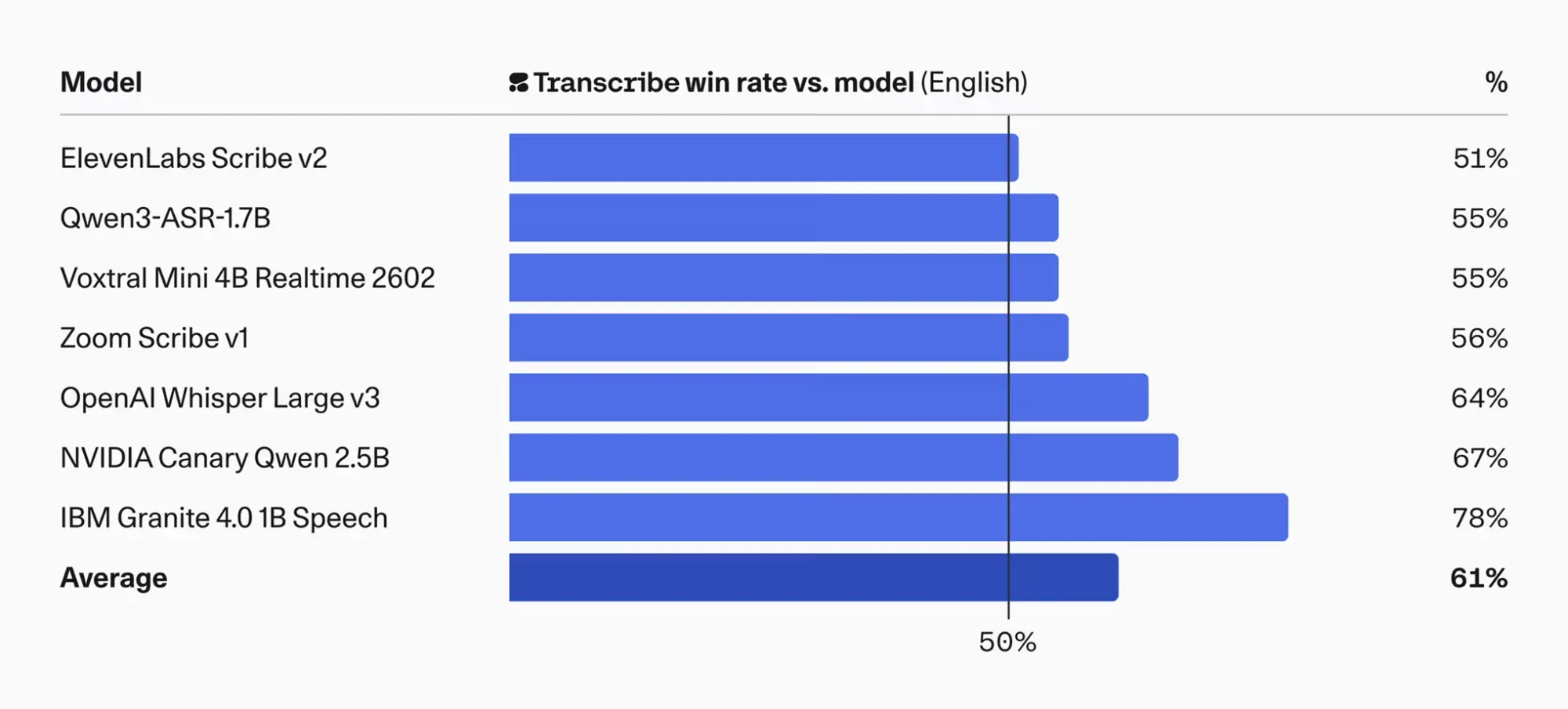
Im direkten Vergleich der englischen Transkription gewinnt Cohere Transcribe durchschnittlich 61 Prozent der Tests gegen andere Modelle. Gegen das IBM Granite Modell liegt die Siegrate sogar bei 78 Prozent. Im direkten Duell mit OpenAI Whisper Large v3 verzeichnet das System einen guten Wert von 64 Prozent.
Quelle: Cohere
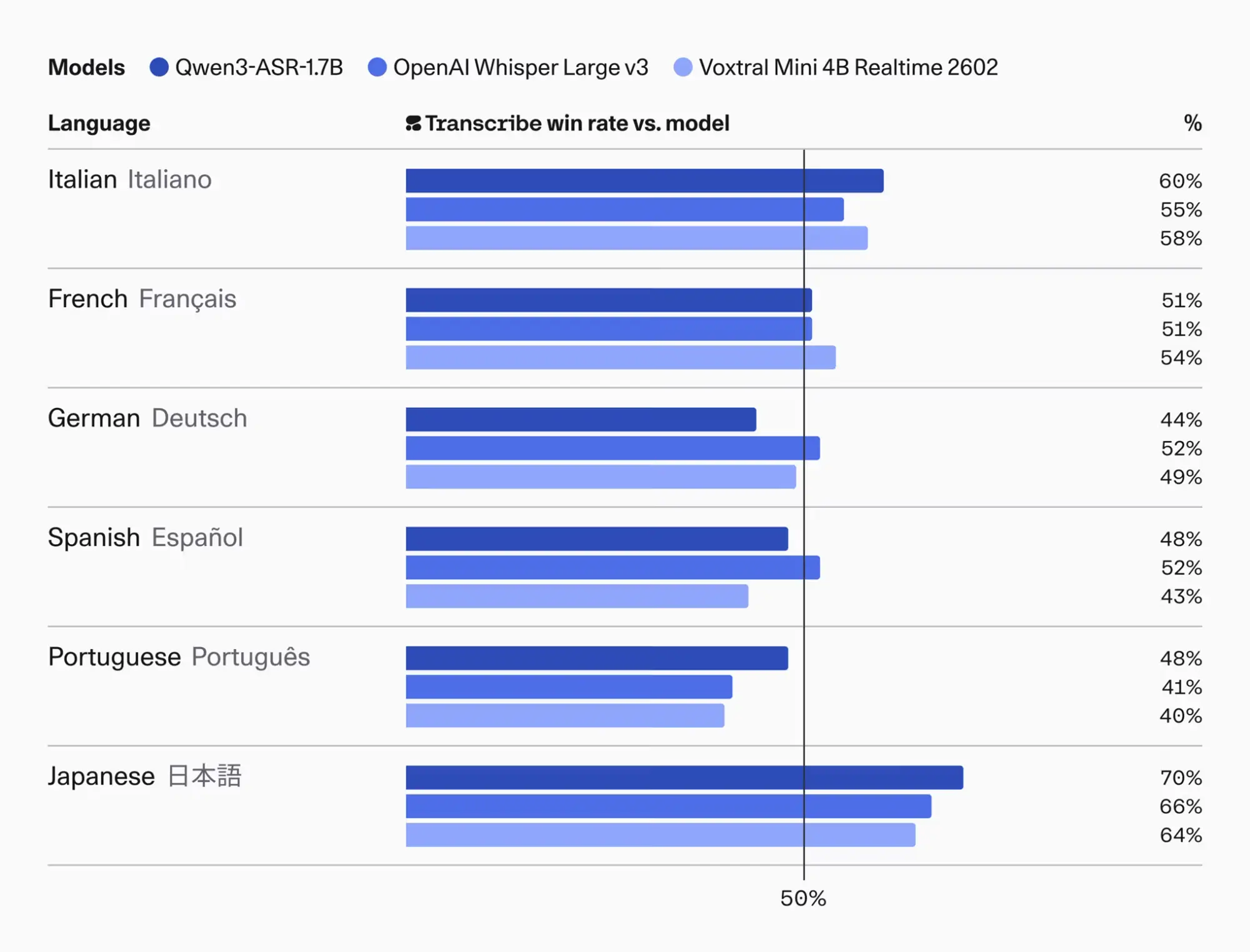
Auch bei anderen Sprachen zeigt das KI-Modell starke Resultate. Besonders bei der japanischen Spracherkennung dominiert es die Konkurrenz mit Siegraten zwischen 64 und 70 Prozent.
Bei europäischen Sprachen fallen die Ergebnisse leicht gemischter aus. Im Deutschen liegt die Erfolgsquote im direkten Vergleich bei rund 44 bis 52 Prozent. Bei italienischen und französischen Audiodaten pendeln sich die Werte meist knapp über der 50-Prozent-Marke ein. Das neue Modell positioniert sich damit als schnelle und präzise Lösung für Transkriptionen.