Wer ist der beste autonome KI-Agent?
Ein neues Ranking auf Arena.ai zeigt die besten autonomen Agenten. Dabei setzt die Plattform vollständig auf echte Nutzerdaten.

Die Bewertungsplattform Arena.ai veröffentlicht mit der »Agent Arena« einen neuen Benchmark für autonome Sprachmodelle. Die Rangliste misst anhand von realen Verhaltenssignalen der Nutzer, wie gut KI-Systeme komplexe Aufgaben selbstständig lösen. Reine Labortests mit künstlichen Eingaben weichen von der praktischen Leistungsfähigkeit ab.
Praxisdaten statt Laborbedingungen
Bisherige Auswertungen evaluierten die Modelle vorwiegend in einfachen Chat-Interaktionen. Die Agent Arena misst hingegen die Leistung bei der Orchestrierung von echten, mehrstufigen Aufgaben. Dabei prüfen die Betreiber, wie gut die Modelle verschiedene Hilfsmittel für einen reibungslosen Arbeitsablauf koordinieren.
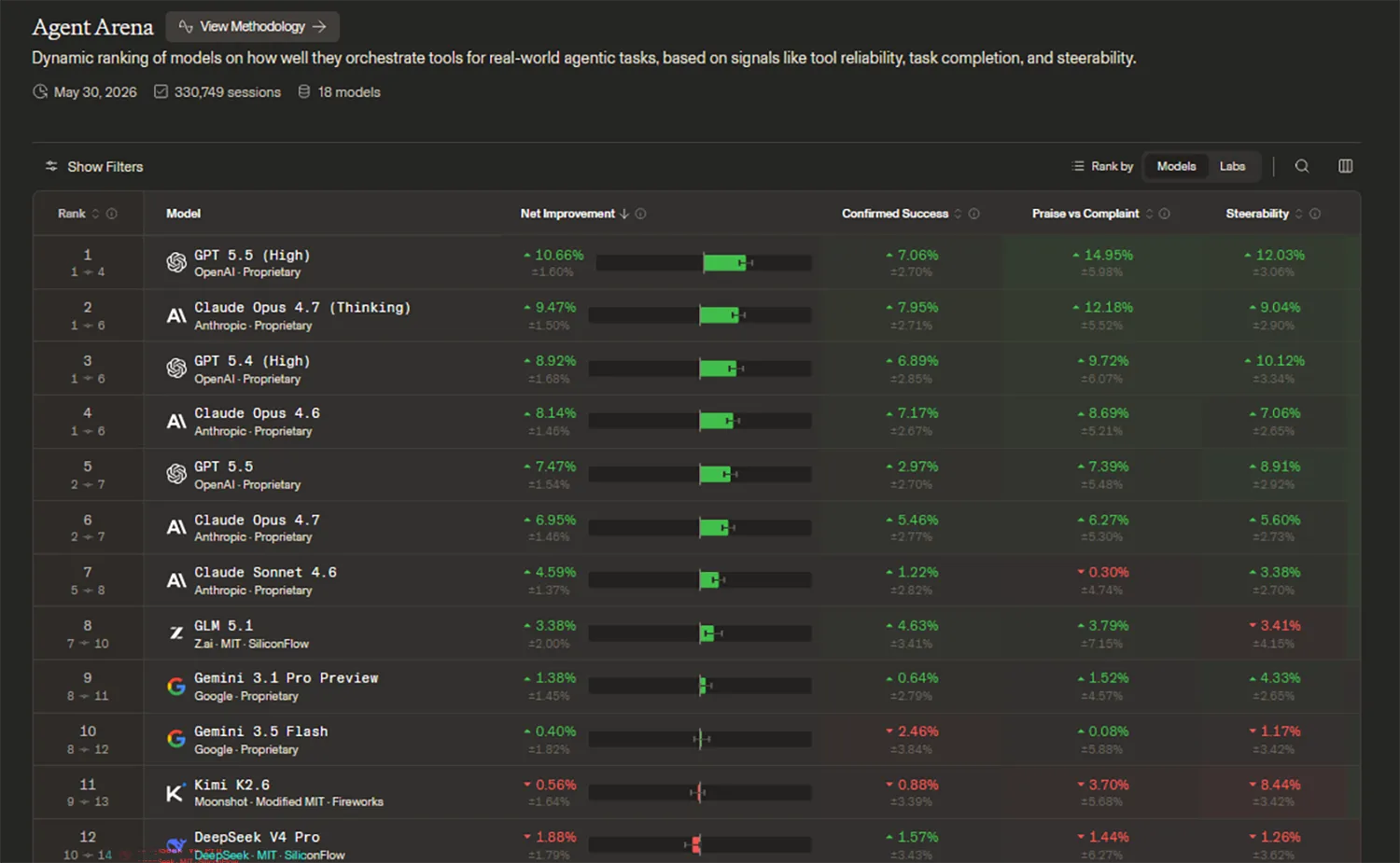
Die Methodik verzichtet bewusst auf vorgefertigte Eingaben oder bezahlte Evaluatoren. Stattdessen nutzt die Plattform direkte Rückmeldungen und Verhaltenssignale aus dem Arbeitsalltag der Anwender. Zu diesen Messwerten zählen die erfolgreiche Aufgabenerledigung, die Steuerbarkeit der Systeme sowie Downloads von erstellten Dateien. Bis zum 30. Mai 2026 erfasste das Leaderboard bereits 330.749 einzelne Sitzungen für diese dynamische Rangliste.
Anzeige
Programmieraufgaben dominieren den Testbetrieb
Ein Blick auf die Aufgabenverteilung offenbart die aktuellen Präferenzen der Nutzer. KI-Agenten werden besonders intensiv für die Softwareentwicklung eingesetzt.
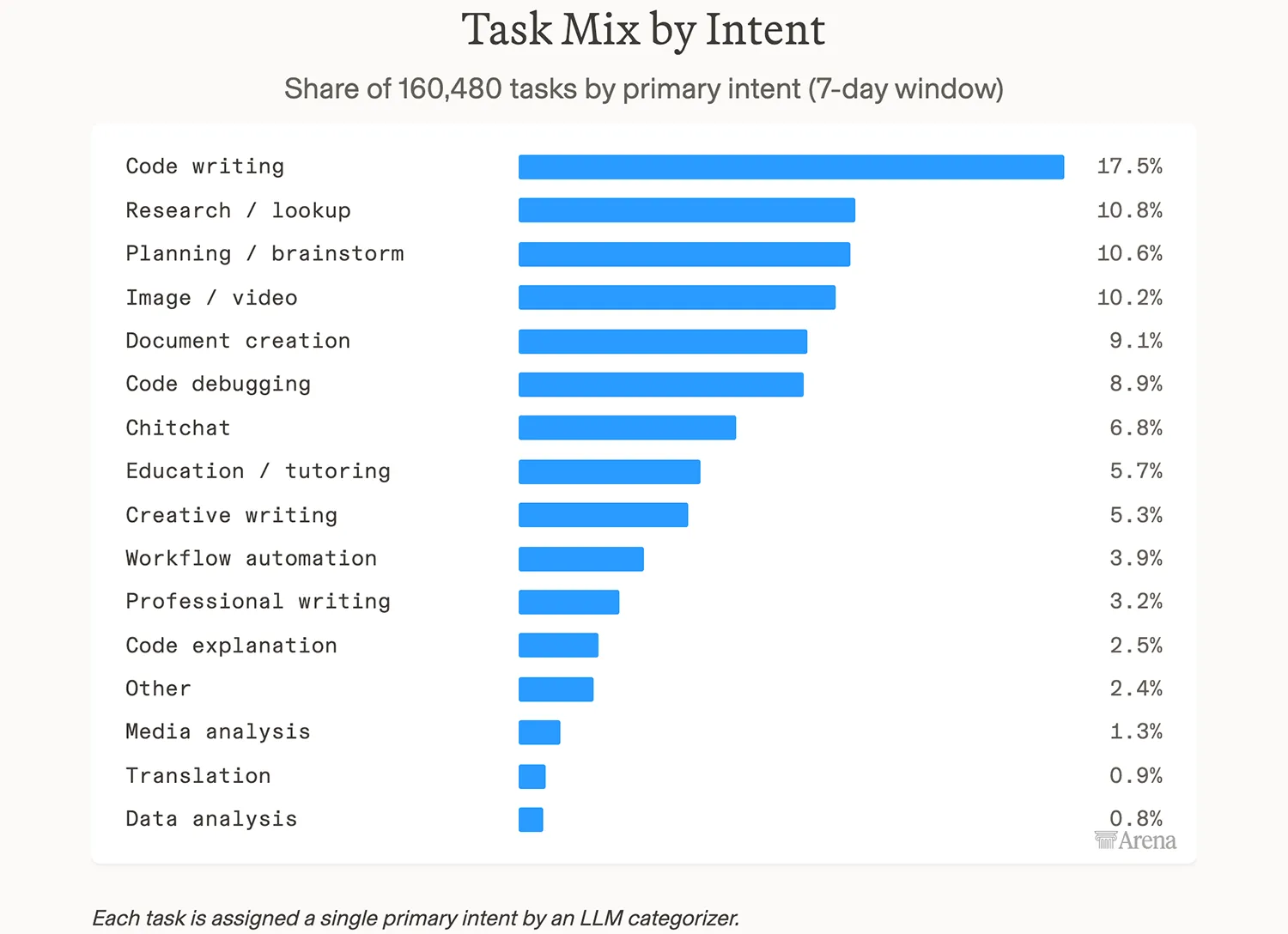
Die Auswertung von gut 160.000 erfassten Aufgaben zeigt klare Tendenzen. Das reine Schreiben von Code führt die Liste mit einem Anteil von 17,5 Prozent an. Das Beheben von Programmfehlern ergänzt diesen Bereich mit zusätzlichen 8,9 Prozent.
Allgemeine Recherchen und die Planung von Projekten landen mit 10,8 sowie 10,6 Prozent auf den nachfolgenden Plätzen. Kreatives Schreiben und die Automatisierung von Workflows spielen mit rund fünf beziehungsweise knapp vier Prozent aktuell nur eine untergeordnete Rolle.
Quelle: arena.ai
OpenAI und Anthropic führen das Feld an
Das Leaderboard listet derzeit 18 verschiedene Sprachmodelle und zeigt deutliche Leistungsunterschiede. OpenAI sichert sich mit GPT 5.5 in der High-Konfiguration den ersten Platz. Auf dem zweiten Rang folgt Anthropic mit Claude Opus 4.7 im speziellen Thinking-Modus.
Die direkten Verfolgerplätze belegen vornehmlich andere Varianten dieser beiden Unternehmen. Google erreicht mit seinem Modell Gemini 3.1 Pro Preview aktuell nur den neunten Platz in der Rangliste.
Knapp dahinter positioniert sich Gemini 3.5 Flash auf dem zehnten Rang. Die offene Konkurrenz um das Modell DeepSeek V4 Pro schließt sich auf dem zwölften Platz an. Mit der Agent Arena etabliert sich somit ein wichtiges Instrument zur Bewertung der tatsächlichen Zuverlässigkeit von Künstlicher Intelligenz im Arbeitsalltag.