
Google MedGemma 1.5 Update: Besser als der Arzt?
Das neue Modell analysiert erstmals komplexe 3D-Scans und könnte die Diagnostik im Krankenhausalltag grundlegend beschleunigen.

Google aktualisiert sein medizinisches KI-Modell MedGemma auf Version 1.5 und stellt mit MedASR zeitgleich eine spezialisierte Spracherkennung vor. Die neuen Open-Source-Modelle verarbeiten erstmals komplexe 3D-Scans wie MRTs und laufen dank effizienter Architektur vollständig offline.
Multimodale Analyse von 3D-Volumendaten
Die wichtigste Neuerung von MedGemma 1.5 liegt in der erweiterten Bildverarbeitung. Während die Vorgängerversion primär zweidimensionale Aufnahmen wie Röntgenbilder interpretierte, bewältigt das Update nun hochdimensionale Daten. Dazu zählen Computertomographien (CT), Magnetresonanztomographien (MRT) und histopathologische Schnittbilder.
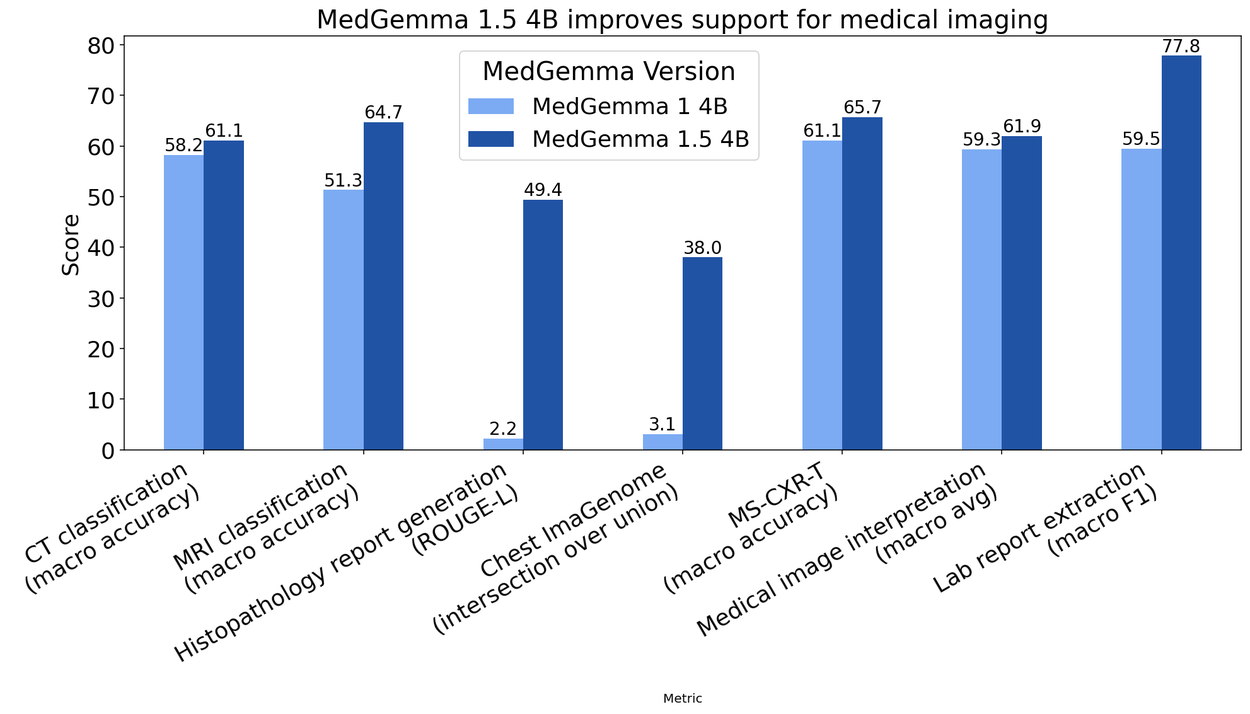
Entwickler können dem Modell ganze Volumendatensätze – also mehrere Schichten eines Scans – als Input geben. Das System analysiert diese Sequenzen im Kontext eines Text-Prompts. Laut Google stieg die Genauigkeit bei der Klassifizierung krankheitsbedingter Befunde im Vergleich zur Version 1 deutlich an: Bei CT-Scans verzeichnet das Modell eine Verbesserung von 3 Prozent, bei MRT-Daten sind es 14 Prozent. Auch die anatomische Lokalisierung auf Röntgenbildern wurde präzisiert.
Zusätzlich unterstützt das Modell nun longitudinale Analysen. Es vergleicht zeitliche Abfolgen von Röntgenaufnahmen des Brustkorbs, um Veränderungen im Krankheitsverlauf zu erkennen.
Quelle: Google
Effizienz und Textverständnis
Google veröffentlicht MedGemma 1.5 zunächst als 4-Milliarden-Parameter-Modell (4B). Diese Größe wurde bewusst gewählt, um eine lokale Ausführung ohne Cloud-Zwang zu ermöglichen. Dies ist im medizinischen Sektor aufgrund sensibler Patientendaten ein entscheidender Faktor. Für komplexere reine Textaufgaben verweist Google weiterhin auf das existierende 27B-Modell der ersten Generation.
Trotz der geringeren Größe übertrifft die neue Version den Vorgänger auch bei reinen Textaufgaben. Auf dem MedQA-Benchmark (medizinische Fragen und Antworten) stieg die Leistung um 5 Prozent, bei der Auswertung elektronischer Gesundheitsakten (EHRQA) sogar um 22 Prozent. Das Modell extrahiert strukturierte Daten aus unstrukturierten Laborberichten nun zuverlässiger.
Quelle: Google
MedASR fordert Whisper heraus
Neben dem Bild-Text-Modell führt Google Research mit MedASR ein dediziertes Speech-to-Text-System ein. Das Modell wurde spezifisch für medizinische Diktate und Fachvokabular trainiert. In internen Tests vergleicht Google die Leistung mit dem weit verbreiteten "Whisper large-v3" Modell von OpenAI.
Die Ergebnisse zeigen eine signifikant niedrigere Wortfehlerrate (WER) bei MedASR. Bei der Transkription von Röntgen-Befunden traten 58 Prozent weniger Fehler auf als bei Whisper. Bei allgemeinen medizinischen Diktaten verschiedener Fachrichtungen lag die Fehlerquote sogar 82 Prozent niedriger. MedASR dient dabei als Brücke, um gesprochene Befunde direkt in Prompts für MedGemma umzuwandeln.
Anzeige
Verfügbarkeit und Wettbewerb
Sowohl MedGemma 1.5 als auch MedASR stehen unter einer offenen Lizenz für Forschung und kommerzielle Nutzung bereit. Die Modelle sind über Hugging Face sowie die Google Cloud-Plattform Vertex AI abrufbar. Um die Entwicklung neuer Anwendungen zu fördern, startet Google parallel auf der Plattform Kaggle die "MedGemma Impact Challenge", einen Hackathon mit Preisgeldern in Höhe von 100.000 US-Dollar.
Google betont, dass es sich bei den Modellen um Werkzeuge für Entwickler handelt. Sie sind nicht für den direkten klinischen Einsatz ohne vorherige Validierung und Anpassung zugelassen.