
Dieser kleine Fehler bremst bisherige KI-Modelle aus
Fast alle modernen Sprachmodelle nutzen eine Architektur mit einem strukturellen Schwachpunkt. Eine neue Lösung behebt den Informationsverlust.
Das KI-Unternehmen Moonshot AI hat das neue Konzept der Attention Residuals vorgestellt. Diese architektonische Methode ersetzt die klassischen, starren Residualverbindungen in modernen Transformer-Modellen durch eine wesentlich flexiblere, tiefenbasierte Aufmerksamkeitsmechanik.
Schwächen der Standard-Architektur
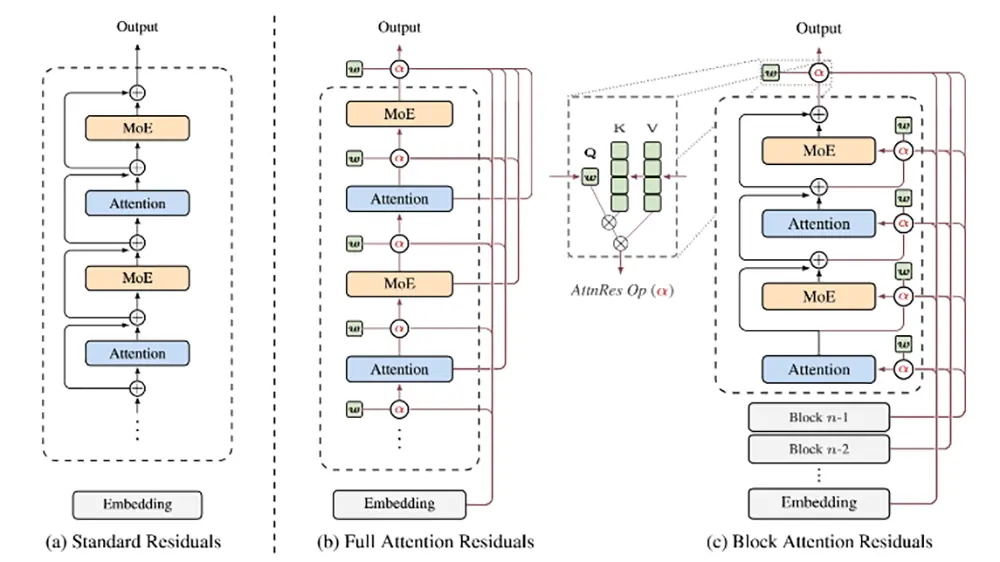
Moderne KI-Modelle basieren fast immer auf der bewährten Transformer-Architektur. Dabei nutzen sie bisher standardmäßig feste Residualverbindungen. Jede einzelne Schicht im Netzwerk addiert ihr Rechenergebnis stumpf zu einem fortlaufenden, zentralen Datenstrom.
Die Forscher von Moonshot AI identifizieren genau hier ein strukturelles Problem. Das neuronale Netz sammelt alle früheren Ergebnisse mit festen Werten an. Die Größe dieser internen Zustände wächst dadurch mit zunehmender Tiefe stark an.
Gleichzeitig schwindet der Einfluss einer einzelnen Schicht auf das Gesamtergebnis immer weiter. Das führt zu einem spürbaren Informationsverlust. Wenn das System die Daten einmal zu einem einzigen Stream vermischt, greifen spätere Schichten nicht mehr gezielt auf spezifische, ältere Informationen zu. Vor allem bei komplexen Aufgaben fehlt dann oft der Kontext.
Dynamische Auswahl statt starrer Datenströme
Attention Residuals beheben diese Schwäche durch einen dynamischen Ansatz. Das System zwingt die Ebenen nicht länger, einen einheitlichen Datenmix zu konsumieren. Stattdessen nutzt die Architektur einen Mechanismus namens Depth-Wise Attention.
Jede Schicht im Modell entscheidet nun selbstständig, welche früheren Darstellungen sie benötigt. Sie gewichtet die Ausgaben der vergangenen Ebenen individuell. So zieht sie sich exakt die Informationen aus dem Speicher, die für den aktuellen Rechenschritt wichtig sind.
Ein starrer Ablauf weicht einer flexiblen Analyse.
Den Erfolg der Attention-Mechanik bei der Verarbeitung von langen Text-Sequenzen überträgt Moonshot AI damit direkt auf die architektonische Tiefe des Netzwerks.
Anzeige
Effizienteres Training für große Modelle
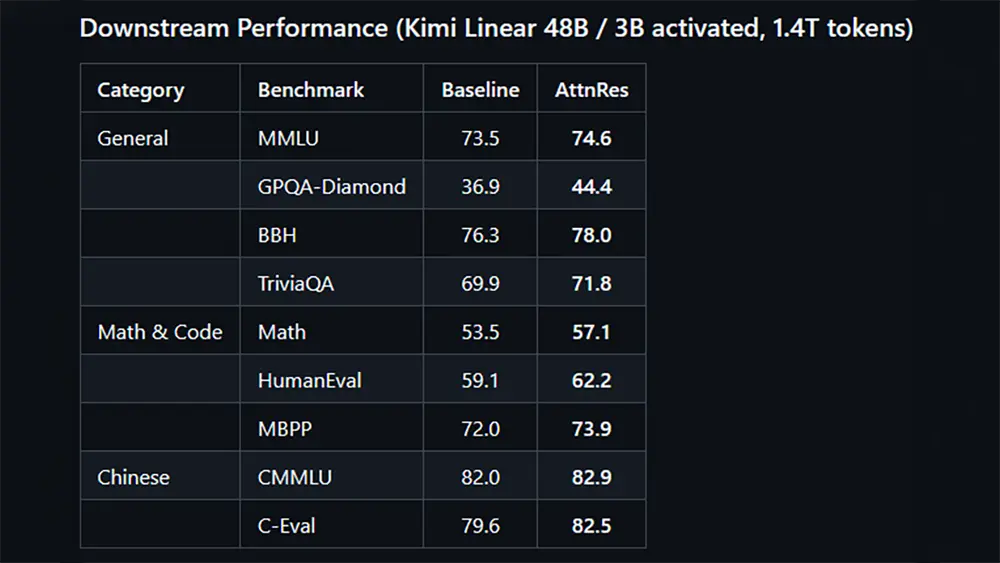
Der Verzicht auf feste Verbindungen bringt klare Vorteile beim Aufbau neuer Modelle. Unterschiedliche Schichten erhalten maßgeschneiderte Informationen, was die Genauigkeit beim Reasoning erhöht.
Gleichzeitig stoppt die neue Architektur das unkontrollierte Wachstum der Datenmengen in tiefen Schichten. Das stabilisiert das Training von extrem großen Modellen spürbar und verhindert Rechenfehler.
Entwickler integrieren die Attention Residuals als direkten Ersatz in bereits bestehende Systeme. Moonshot AI bietet den entsprechenden Code ab sofort als Open Source an. Die Methode liefert der Entwickler-Community eine praktische Lösung für die technische Skalierung kommender KI-Generationen.