Anthropic stellt neuen »BioMysteryBench« vor
Ein neuer Bioinformatik-Test offenbart verblüffende analytische Fähigkeiten. Die neuesten Modelle lösen Aufgaben, an denen Fachleute scheitern.

Aktuelle KI-Modelle dringen tief in die komplexe Welt der Bioinformatik vor. Mit dem neuen BioMysteryBench existiert ein Testverfahren, das diese Fähigkeiten an echten Forschungsdaten misst. Dabei lösen die fortschrittlichsten Versionen sogar Aufgaben, an denen menschliche Experten scheitern.
Reale Daten statt simulierter Labore
Bisherige Tests prüften bei den Modellen oft primär das theoretische Wissen ab. BioMysteryBench wählt ganz bewusst einen deutlich praxisnäheren Ansatz. Dieser Benchmark konfrontiert die KI-Modelle mit 99 echten, unaufbereiteten Datensätzen direkt aus der Forschung. Dazu zählen unter anderem rohe DNA-Sequenzierungen oder völlig unstrukturierte klinische Proben.
Von diesen Aufgaben gelten 76 als durch Menschen lösbar. Die restlichen 23 Probleme stellten Fachleute jedoch vor unüberwindbare Hürden. Gewertet wird am Ende ausschließlich das biologisch korrekte Ergebnis. Der analytische Weg dorthin bleibt den Modellen völlig freigestellt, was verschiedenste Lösungsstrategien im Umgang mit den Daten zulässt.
Anzeige
Beeindruckende Werte bei komplexen Datensätzen
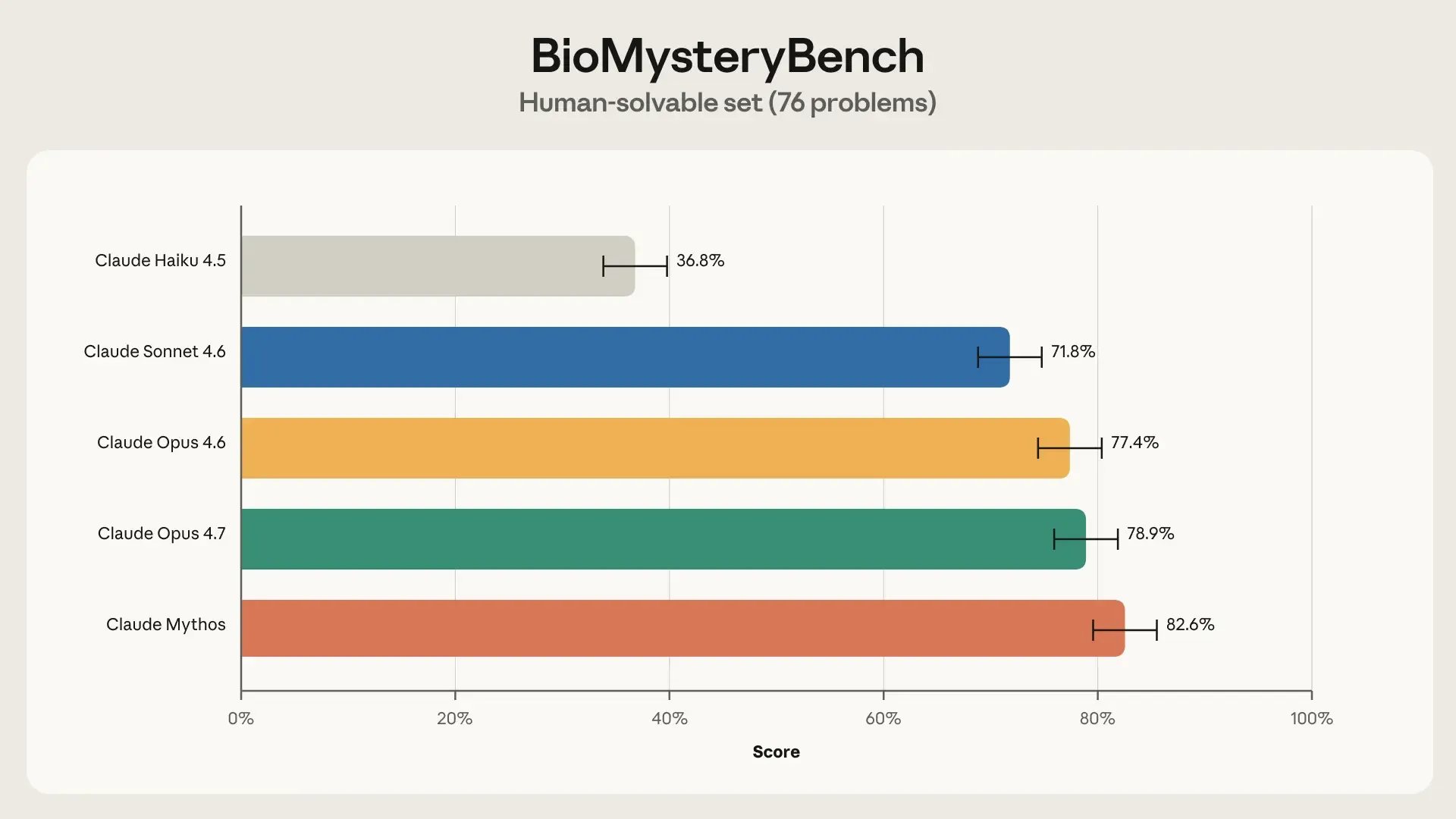
Die ausgewerteten Ergebnisse zeigen markante Leistungssprünge zwischen den einzelnen Modell-Generationen. Bei den lösbaren Aufgaben erreicht das Modell Claude Haiku 4.5 zunächst eine Basis von 36,8 Prozent. Wesentlich stärker präsentiert sich bereits Claude Sonnet 4.6 mit 71,8 Prozent. Die absolute Spitzenposition übernimmt das aktuelle Modell Claude Mythos mit einer starken Erfolgsquote von 82,6 Prozent.
Quelle: Anthropic
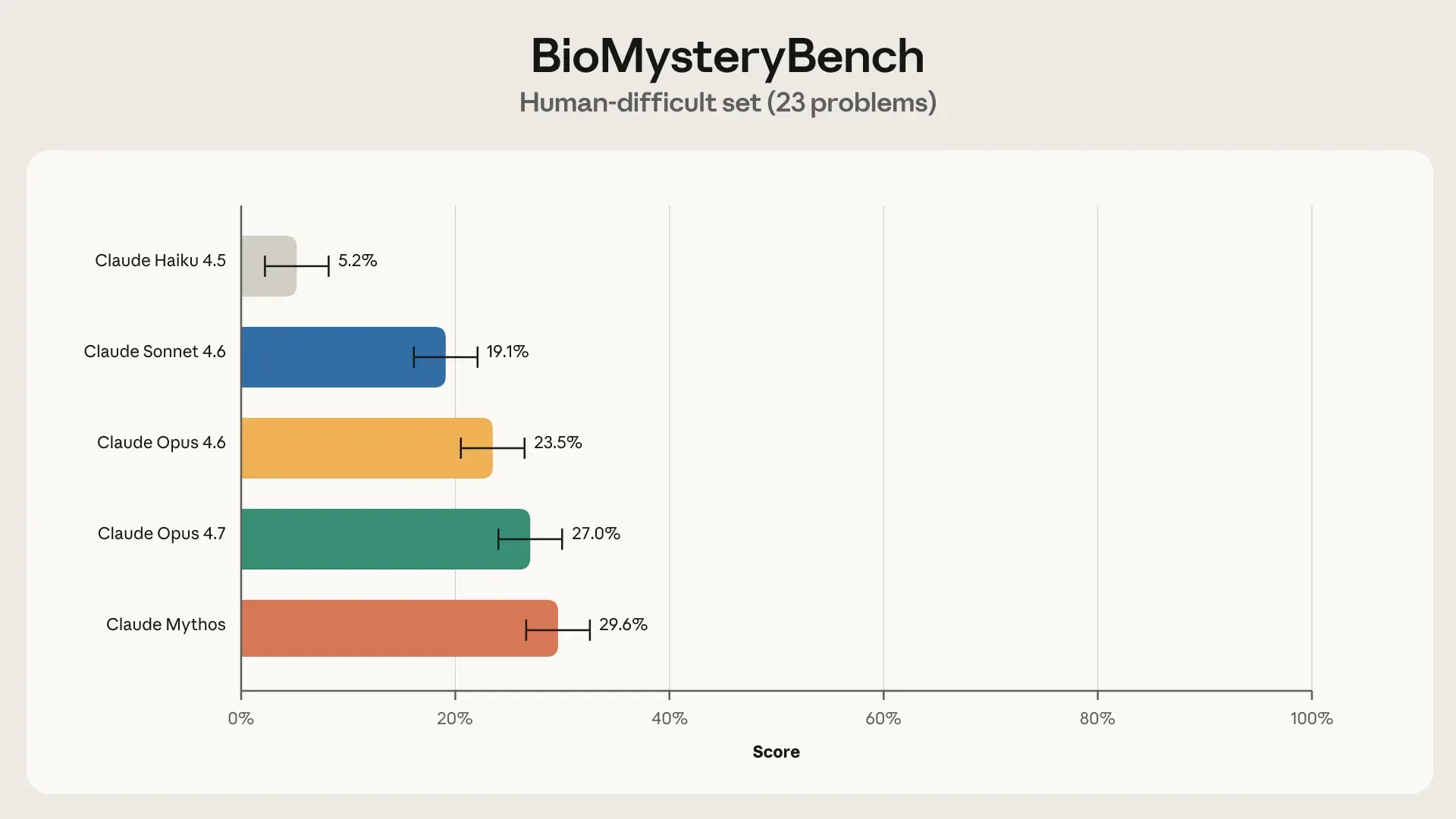
Besonders aufschlussreich fallen die Tests bei dem extrem schweren Set aus. Hier knackt Claude Mythos 29,6 Prozent jener Aufgaben, für die das menschliche Experten-Panel schlicht keine Lösung fand. Dicht dahinter positioniert sich Claude Opus 4.7 mit 27,0 Prozent. Solche Quoten belegen eindrucksvoll die rasant wachsenden analytischen Fähigkeiten der neuesten Ausbaustufen.
Quelle: Anthropic
Die Lücke zwischen Wissen und Zufall
Ein tieferer Blick auf die Zuverlässigkeit der Antworten offenbart allerdings noch methodische Schwächen. Bei bekannten Problemen rufen die Modelle ihr Wissen extrem konstant ab. Lösen sie eine Aufgabe der einfachen Kategorie erfolgreich, gelingt dieser Durchlauf fast immer in vier oder fünf von fünf Versuchen.
Innerhalb der schweren Kategorie wandelt sich dieses Bild drastisch. Nahezu die Hälfte der korrekten Antworten entsteht hier durch Pfade, die ein Modell nur in ein bis zwei Versuchen findet. Dabei verknüpfen die Systeme zwar intelligent riesige Datenmengen aus verschiedenen Disziplinen, profitieren bei diesen seltenen Treffern aber oft von kaum reproduzierbaren Gedankengängen. Dennoch etablieren sich diese aktuellen Architektur-Generationen zunehmend als ernstzunehmende Instanz in der wissenschaftlichen Analyse.