
KI im Physik-Test: NotebookLM schlägt ChatGPT
Forscher von Google haben sechs große KI-Modelle auf ihre Fähigkeiten in der Quantenphysik getestet. Die Ergebnisse überraschen.
Google hat aktuelle Benchmark-Ergebnisse veröffentlicht, die zeigen, wie gut KI-Modelle Physiker im Forschungsalltag unterstützen. Forscher prüften sechs Systeme auf ihre Fähigkeit, anspruchsvolle Fragen zur Hochtemperatursupraleitung fachgerecht zu beantworten.
NotebookLM dominiert bei den Fakten
Google testete über eine API bekannte Modelle wie ChatGPT, Claude, Gemini, Perplexity sowie NotebookLM und ein speziell angepasstes Custom-Modell. Die Forscher entwickelten für diesen Test einen neuen Benchmark, der gezielt das Reasoning der KIs in der Quantenphysik auf die Probe stellt. Die Ergebnisse offenbaren große Unterschiede in der Antwortqualität.
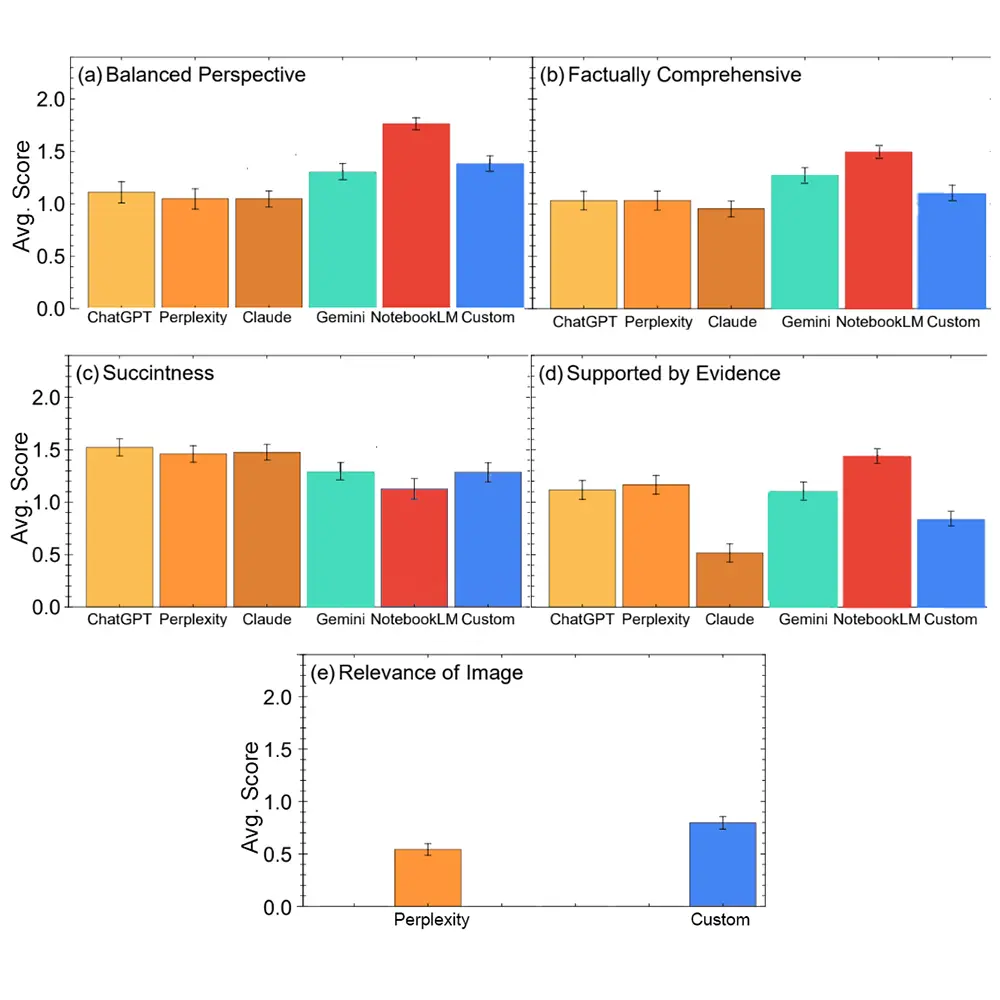
NotebookLM erzielt die höchsten Werte bei der Faktendichte und der ausgewogenen Perspektive. Das System verarbeitet den komplexen Prompt der Physiker fehlerfrei und liefert sehr detaillierte Antworten.
Besonders bei der wissenschaftlichen Evidenz lässt das Google-Tool die Konkurrenz weit hinter sich. Die Tester bewerteten streng, wie gut die Modelle ihre Aussagen mit handfesten Belegen und Quellen stützen. Das Modell Claude schneidet in dieser speziellen Kategorie überraschend schwach ab und bildet das klare Schlusslicht in der Messung.
Quelle: Google
Prägnanz versus wissenschaftliche Tiefe
Ein völlig anderes Bild zeigt sich bei der Kürze und Verständlichkeit der Antworten. ChatGPT und Perplexity fassen komplexe Informationen am schnellsten zusammen. Beide Systeme erhalten hohe Punktzahlen für ihre sehr prägnante Textausgabe.
Sie liefern Forschern zügige Überblicke, dringen aber weniger tief in die akademische Fachliteratur ein. Solche Modelle helfen hervorragend bei der ersten Orientierung, ersetzen jedoch keine tiefgehende Literaturrecherche.
Ein angepasstes Custom-Modell trat zudem im spezifischen Bereich der Bildrelevanz gegen Perplexity an. KIs haben oft große Schwierigkeiten, korrekte wissenschaftliche Diagramme auszugeben. Das Custom-Modell wählt laut den vorliegenden Daten deutlich passendere visuelle Darstellungen für die physikalischen Themen aus als der Konkurrent Perplexity.
Die neue Studie ordnet die Fähigkeiten aktueller KI-Modelle im akademischen Umfeld exakt ein. Forscher müssen je nach Anforderung das passende System wählen. Viele KIs scheitern noch immer an extrem spezifischen Detailfragen, da ihre Trainingsdaten eher breites Allgemeinwissen abdecken. Wer schnelle Zusammenfassungen für ein Projekt benötigt, nutzt andere KIs als ein Wissenschaftler, der tief in die komplexe Materie eintaucht und exakte Belege fordert.