
Neue Plattform SciArena testet KI-Modelle mit echter Wissenschaft
OpenAI vorn, aber Open-Source holt auf: Wie SciArena mit echten Forschungsszenarien das KI-Ranking aufmischt – und was es jetzt zu beachten gilt?

gpt-image-1 | All-AI.de
EINLEITUNG
Mit SciArena bringen Forscher von Yale, NYU und Ai2 eine neue Bewertungsplattform an den Start, die große Sprachmodelle anhand echter Forschungsfragen beurteilt. Statt automatischer Scores entscheiden hier Wissenschaftler selbst. Die Ergebnisse zeichnen ein deutliches Bild – doch was bedeutet das für den Einsatz von KI in der Forschung?
NEWS
Fachurteil statt Zahlenspiel
Die Idee hinter SciArena ist simpel, aber wirkungsvoll: Statt synthetischer Benchmarks werden Modelle mit echten wissenschaftlichen Fragen konfrontiert. Zwei Sprachmodelle liefern jeweils eine Langantwort mit Quellenangabe, anschließend entscheidet ein Mensch, welche besser passt. Genutzt wird dabei die ScholarQA-Pipeline von Ai2, die wissenschaftliche Datenbanken nach relevanter Literatur durchforstet. So entsteht ein realistisches Szenario, das näher an der tatsächlichen Forschungspraxis ist als jede Multiple-Choice-Aufgabe.
Dass echte Forscher bewerten, macht einen großen Unterschied. Sie achten nicht nur auf Fakten, sondern auch auf Argumentationsstruktur, Zitierlogik und Stringenz. Das Ergebnis: eine Bewertung, die sich weniger um die Show, sondern mehr um die Substanz dreht. Damit setzt SciArena ein neues Niveau – eines, das der realen Anwendung im Forschungsalltag deutlich näherkommt als herkömmliche Tests.
Proprietär führt – aber nicht mehr uneinholbar
Im ersten Durchlauf dominiert OpenAIs neues Modell o3 das Ranking. Dicht dahinter liegen Claude‑4‑Opus und Gemini 2.5‑Pro – alle drei proprietär, mächtig, aber geschlossen. Spannend ist allerdings, wie gut sich Open-Source-Modelle schlagen. DeepSeek‑R1‑0528 landet in den Top 5 und lässt teils etablierte Namen hinter sich. Das Modell punktet vor allem in Technik- und Naturwissenschaften mit fundierten, gut belegten Antworten.
Diese Entwicklung zeigt: Die Lücke zwischen offenen und kommerziellen Modellen wird kleiner. Während o3 derzeit noch das Niveau vorgibt, holen Projekte wie DeepSeek spürbar auf – und das ohne Zugriff auf exklusive Trainingsdaten oder Milliardenbudgets. Für die wissenschaftliche Community ist das ein Hoffnungsschimmer, denn offene Modelle lassen sich leichter nachvollziehen, anpassen und weiterentwickeln.
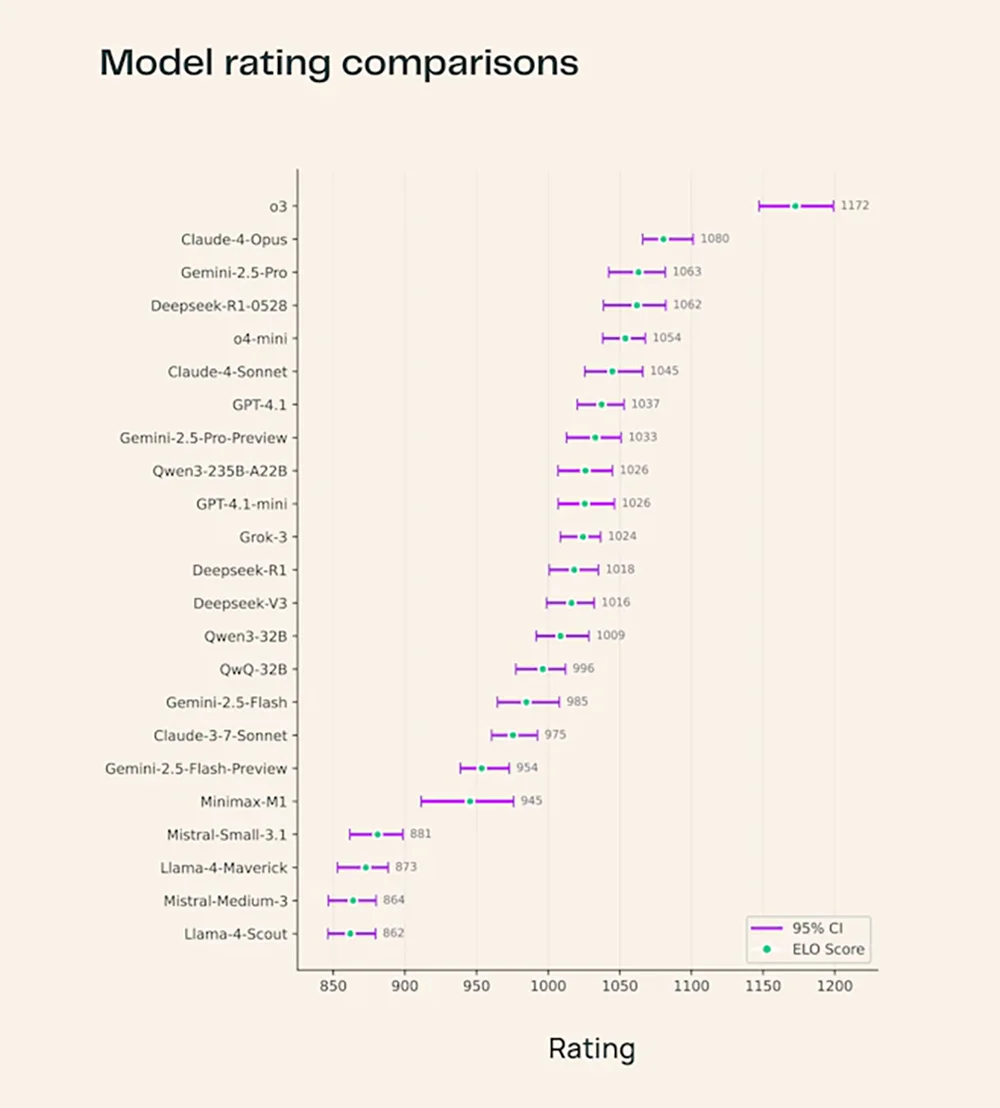
Quelle: Ai2
Mensch gegen Maschine – wer bewertet besser?
Mit SciArena‑Eval liefert die Plattform einen zweiten Benchmark: Modelle sollen selbst beurteilen, welche von zwei Antworten besser ist – so, wie es ein Mensch tun würde. Doch bisher kommt das beste System nur auf 65 Prozent Übereinstimmung mit menschlichen Juroren. Das zeigt ziemlich deutlich: Auch wenn Modelle immer besser schreiben, können sie menschliche Urteilsfähigkeit noch nicht zuverlässig imitieren.
Das wird auch daran deutlich, wie unterschiedlich Modelle gewichten. Während viele auf Länge, formale Eleganz oder hohe Zitatzahlen setzen, achten Menschen eher auf Relevanz, Kontextbezug und argumentative Klarheit. Genau darin liegt die Stärke von SciArena: Das System zwingt Modelle dazu, sich an echten Erwartungen zu messen – nicht an künstlich generierten Punktesystemen.
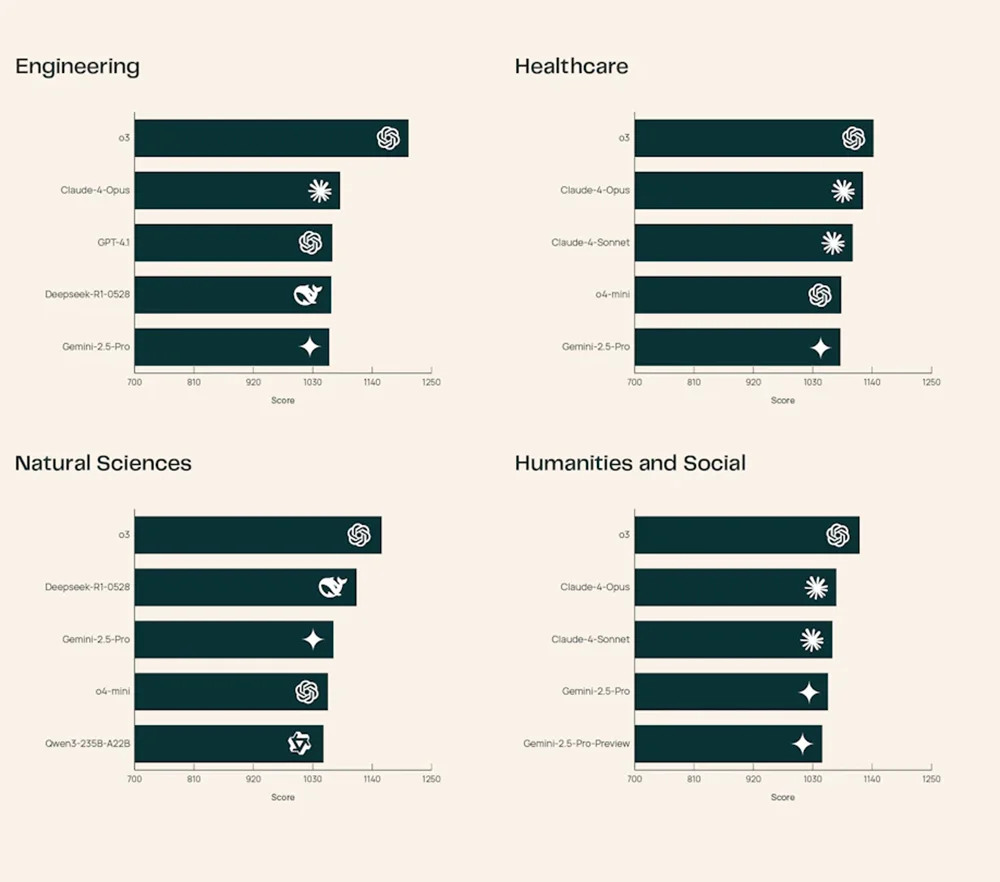
Quelle: Ai2
Offene Plattform, echte Beteiligung
Ein weiterer Pluspunkt: SciArena ist Open Source. Code, Benchmarks und Bewertungsdaten stehen frei zur Verfügung, neue Modelle können jederzeit eingereicht werden. Auch zukünftige Agentensysteme sollen auf der Plattform getestet werden können – etwa Recherche-Bots, die Literatur selbstständig analysieren. Der Gedanke dahinter: KI soll sich nicht an PR-Benchmarks messen, sondern an echter Nützlichkeit für reale Nutzer.
In der Community kommt das gut an. Besonders das Abschneiden von DeepSeek sorgt auf Reddit und in Entwicklerforen für Begeisterung. Viele Nutzer sehen darin den Beweis, dass man mit offenen Tools ernsthafte Forschung betreiben kann. Die Plattform hat das Potenzial, zu einem festen Prüfstein für neue KI‑Modelle zu werden – mit realen Anforderungen und echtem wissenschaftlichem Anspruch.
AUSBLICK
Hype kann jeder – Forschung ist die Königsklasse
Mal ehrlich: Von Benchmarks mit Fantasiewörtern und fiktiven Aufgaben hatten wir alle genug. Was SciArena bringt, ist einfach greifbarer. Es geht um echte Fragen, echte Quellen und echte Entscheidungen – genau das, worauf es in der Praxis ankommt. Dass o3 vorn liegt, ist keine Überraschung. Aber dass ein Open-Source-Modell wie DeepSeek plötzlich in derselben Liga spielt, macht richtig Laune. Klar, es gibt noch Luft nach oben, gerade bei der automatischen Bewertung. Aber wenn Forscher wieder selbst sagen, was gut ist, und nicht nur Metriken – dann sind wir auf dem richtigen Weg.

UNSER ZIEL
KURZFASSUNG
- Mit SciArena vergleichen echte Wissenschaftler KI-Modelle anhand realer Forschungsfragen – OpenAI o3 führt, aber Open-Source-Modelle holen auf.
- DeepSeek-R1-0528 überrascht mit Top-Leistung, besonders bei naturwissenschaftlichen Themen und präziser Zitierung.
- Automatisierte Bewertungssysteme erreichen nur 65 % Übereinstimmung mit menschlichen Urteilen – ein Signal für die Wichtigkeit menschlicher Beteiligung.
- Der offene, kollaborative Ansatz von SciArena könnte zum neuen Goldstandard für wissenschaftliche KI-Evaluationen werden.