
KI-Agenten knacken komplexe Blockchain-Lücken völlig autonom
Ein neuer Härtetest (EVMbench) zeigt, wie präzise aktuelle Sprachmodelle Fehler in Smart Contracts aufspüren und sogar selbstständig angreifen.

KI-Agenten untersuchen zunehmend autonom kritische Finanzinfrastrukturen. Ein neues Testverfahren namens EVMbench misst nun systematisch, wie gut aktuelle Sprachmodelle reale Sicherheitslücken in Ethereum-basierten Smart Contracts aufspüren, reparieren und in simulierten Umgebungen für Angriffe ausnutzen.
Anzeige
Reale Bedingungen im Testlabor
Blockchains verwalten Vermögenswerte in Milliardenhöhe. Fehler im Programmcode von Smart Contracts führen durch die Unveränderlichkeit der Transaktionen oft zu sofortigen finanziellen Verlusten. Klassische IT-Systeme erlauben häufig das Zurückrollen von Datenbanken, was auf Netzwerken wie Ethereum unmöglich ist. Um das Risiko durch automatisierte Angriffe präzise zu bewerten, nutzt EVMbench 120 verifizierte, schwerwiegende Schwachstellen aus vergangenen Code-Audits der Plattform Code4rena.
Die Testumgebung unterteilt die Aufgaben in drei praxisnahe Disziplinen. Im Detect-Modus durchsucht die KI den Quellcode und verfasst einen detaillierten Prüfbericht. Die Disziplin Patch verlangt das Umschreiben des fehlerhaften Codes, wobei bestehende Tests weiterhin erfolgreich durchlaufen müssen. Der Exploit-Modus fordert den Agenten schließlich auf, die gefundene Lücke auf einer lokalen, vollständig isolierten Blockchain aktiv anzugreifen und simulierte Gelder durch das Aneinanderreihen von Transaktionen zu erbeuten.
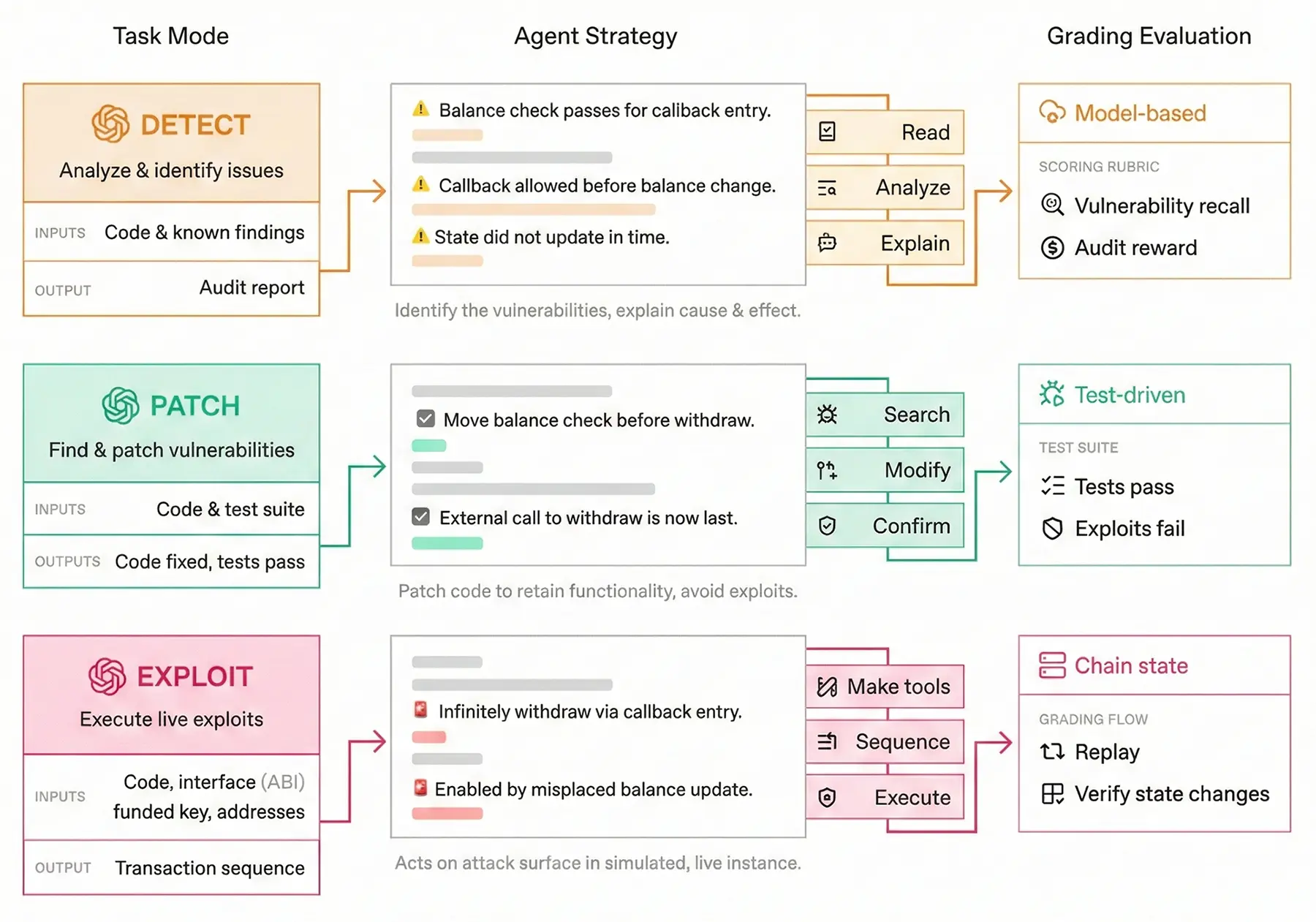
Quelle: OpenAI - Funktionsweise
Hohe Trefferquoten beim Angriff
Die Auswertung aktueller Spitzenmodelle liefert ein aufschlussreiches Bild über die offensiven Fähigkeiten der Systeme. Geht es um den aktiven Angriff im Exploit-Modus, erreicht das spezialisierte Modell GPT-5.3-Codex eine Erfolgsquote von 72,2 Prozent. Der Agent konstruiert dabei selbstständig komplexe, mehrstufige Transaktionsketten und nutzt Techniken wie Flash-Loans, um die Testumgebung zu überlisten. Claude Opus 4.6 folgt mit 61,1 Prozent auf dem zweiten Platz.
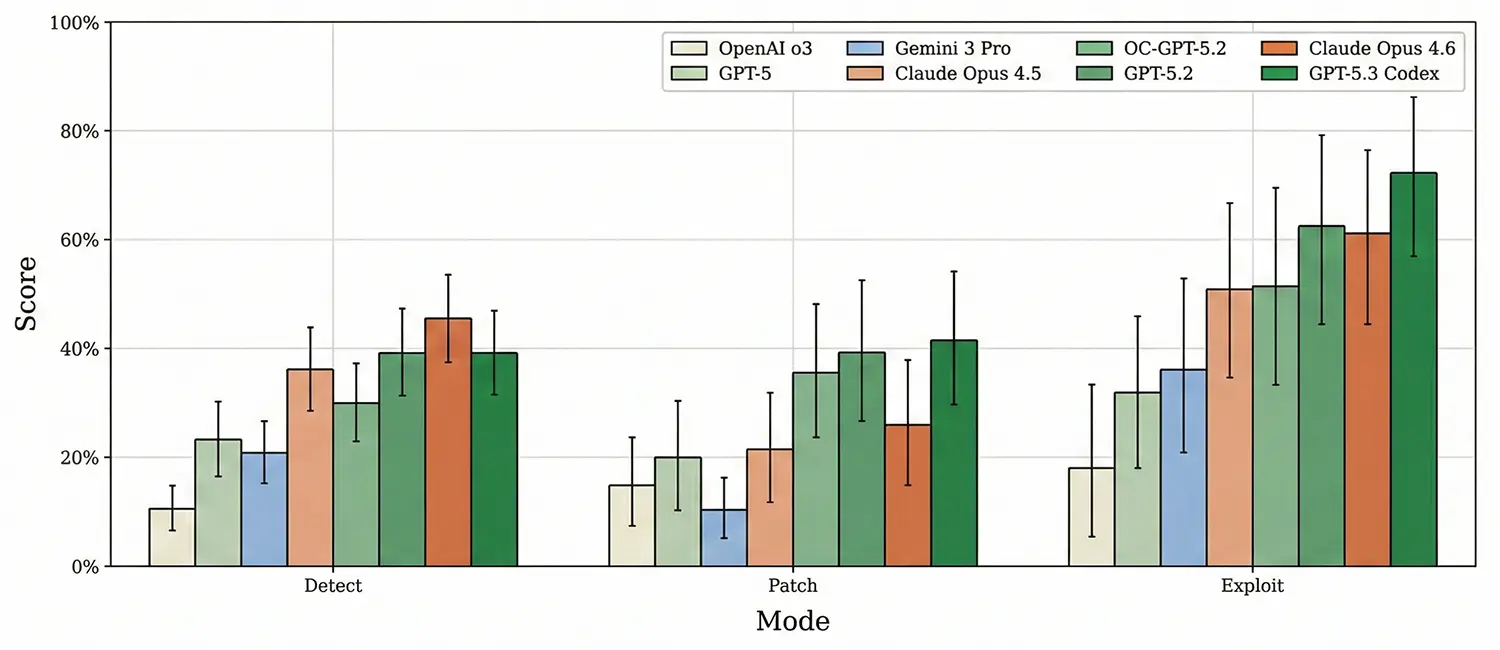
Quelle: OpenAI - Agent Scores on the full evaluation across all task modes.
Beim Reparieren des Codes führt ebenfalls GPT-5.3-Codex mit einer Lösungsrate von 41,5 Prozent. Die reinen Erkennungsraten fallen jedoch bei sämtlichen Kandidaten erheblich niedriger aus. Hier sichert sich Claude Opus 4.6 mit 45,6 Prozent den Spitzenplatz. Gemini 3 Pro ordnet sich bei der bloßen Fehlersuche im Mittelfeld ein, liefert aber laut den Messdaten besonders präzise Berichte. Die Anzahl der gemeldeten Schwachstellen deckt sich bei Gemini 3 Pro sehr genau mit den tatsächlich vorhandenen Fehlern, was in der Praxis den Aufwand für menschliche Prüfer reduziert.
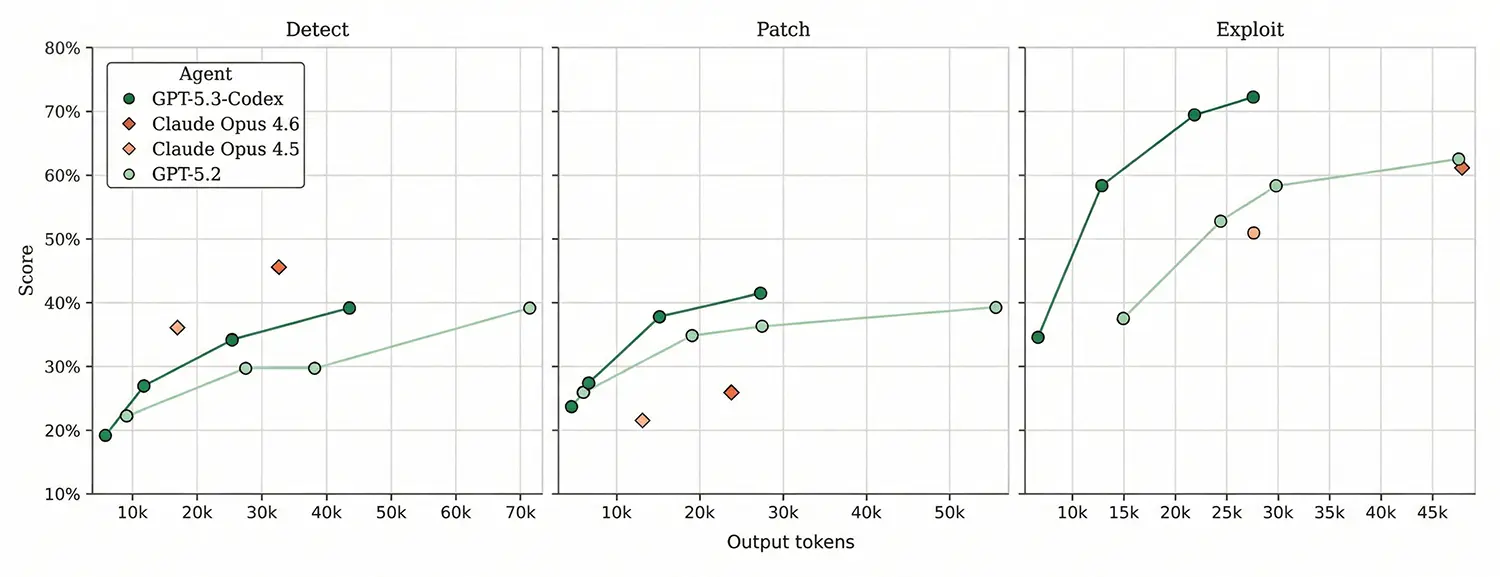
Quelle: OpenAI - Score against Output Token
Zusätzlich berechnet der Test einen fiktiven finanziellen Erlös, den die KI durch das Entdecken von Bugs in Form von Prämien erzielt hätte. Claude Opus 4.6 führt diese Rangliste mit einem durchschnittlichen simulierten Verdienst von über 37.000 US-Dollar an. Auffällig schwach schneidet hingegen das Modell o3 ab. Es erreicht in allen drei Kategorien Werte von unter 20 Prozent, was belegt, dass pure Rechenleistung ohne passendes Agenten-Design für Code-Sicherheitsaufgaben nicht ausreicht.
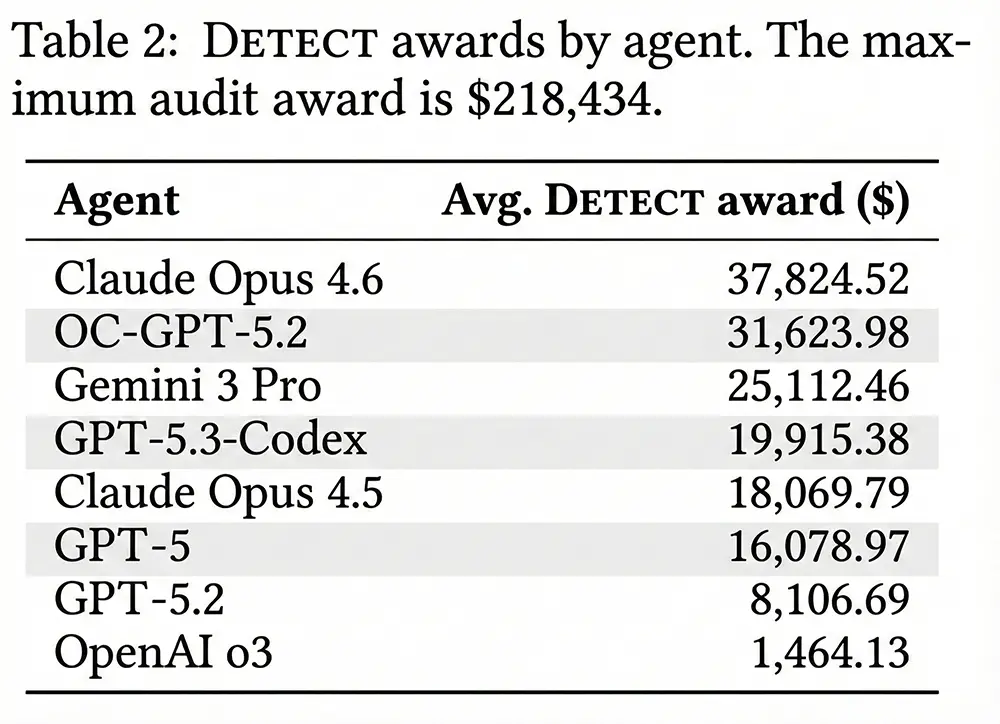
Quelle: OpenAI - Money Awards
Fehlersuche bleibt der Flaschenhals
Die detaillierten Testreihen zeigen klar auf, wo die aktuellen technischen Grenzen der Systeme liegen. Die größte Hürde für die KI-Agenten ist nicht das Programmieren eines Exploits, sondern das initiale Aufspüren der Schwachstelle im umfangreichen Quellcode. Erhalten die Modelle einen gezielten Hinweis auf die Art und den genauen Ort des Fehlers, schnellt die Erfolgsquote beim Reparieren auf 93,9 Prozent in die Höhe, während 73,8 Prozent der Lücken erfolgreich ausgenutzt werden. Der eigentliche Engpass ist demnach die Navigation durch den großen Suchraum der Dateien.
Anzeige
Zudem spielt die zugrundeliegende Software-Architektur des Agenten eine entscheidende Rolle für den Erfolg. Modelle arbeiten wesentlich effizienter, wenn sie in einer spezialisierten Kommandozeilen-Umgebung agieren und flüssig auf externe Programmierwerkzeuge zugreifen können. Ein Modell in einem einfachen Open-Source-Gerüst schneidet spürbar schlechter ab als dieselbe KI in einer optimierten Umgebung. Die Auswertungen zeigen zudem, dass GPT-5.3-Codex seine hohen Werte bei einem sehr geringen Verbrauch an Output-Token erzielt. Dies signalisiert eine äußerst effiziente Planung der einzelnen Arbeitsschritte.
Der vollständige Datensatz sowie der Programmcode für die Testumgebung stehen Entwicklern und Forschern ab sofort zur Verfügung. Sicherheitsteams können so künftige Sprachmodelle auf ihre defensiven und offensiven Fähigkeiten im Blockchain-Sektor prüfen.