
Wie ein kleines Hilfsmodell das KI-Training drastisch beschleunigt
Die neue MIT-Methode TLT nutzt freie Kapazitäten von Grafikkarten, um den Lernprozess großer Sprachmodelle sichtbar zu optimieren.

Forscher des MIT haben mit „TLT“ (Taming the Long-Tail) ein neues Verfahren vorgestellt, das das Training von Reasoning-Modellen deutlich beschleunigt. Die Methode nutzt gezielt die Leerlaufzeiten von Grafikkarten, um den Lernprozess ohne zusätzliche Kosten effizienter zu gestalten.
Das Problem der langen Antworten
Beim Training moderner KI-Modelle durch Reinforcement Learning entsteht oft ein technischer Flaschenhals. Sogenannte Reasoning-Modelle generieren vor der eigentlichen Ausgabe ausführliche Lösungswege. Diese internen Gedankengänge fallen je nach Aufgabe unterschiedlich lang aus.
Wenn eine Grafikkarte (GPU) eine kurze Antwort schnell verarbeitet hat, muss sie warten, bis andere GPUs ihre extrem langen Antworten beendet haben. Dieser Effekt wird in der Informatik als „Long-Tail“ bezeichnet. Er führt zu ungenutzter Rechenleistung und treibt die Dauer sowie die finanziellen Kosten für das Training spürbar in die Höhe. Bisherige Optimierungen konnten dieses Problem nur schwer lösen, da die dynamische Natur des Vorgangs eine gleichmäßige Hardware-Auslastung erschwert.
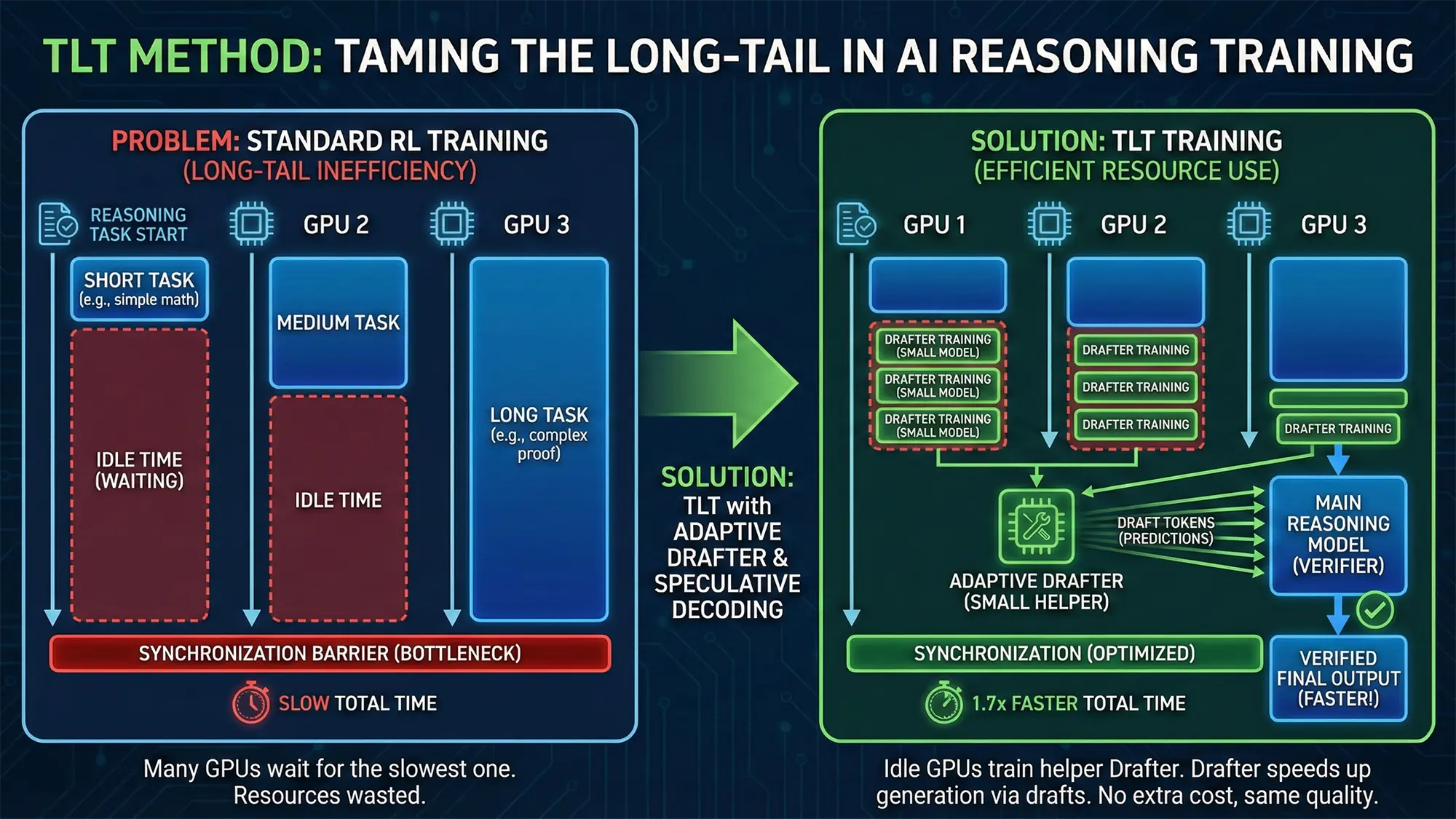
Wie das System die Leerlaufzeiten füllt
Um diese teuren Wartezeiten sinnvoll zu nutzen, setzt die Architektur auf eine Technik namens Adaptive Speculative Decoding. TLT trainiert auf den pausierenden GPUs kontinuierlich ein kleines Entwurfsmodell, den sogenannten Adaptive Drafter.
Dieses kompakte Hilfsmodell läuft asynchron im Hintergrund. Es passt sich permanent an den aktuellen Stand des großen Hauptmodells an. Sobald es einsatzbereit ist, generiert das kleine Modell sehr schnell vorläufige Textbausteine für die Lösungswege. Das große, rechenintensive Modell muss diese Vorschläge anschließend nur noch in einem Durchgang überprüfen und absegnen. Stimmen die Entwürfe, spart das System enorm viel Zeit im Vergleich zur aufwendigen Eigen-Generierung jedes einzelnen Tokens.
Anzeige
Messbare Zeitersparnis für Entwickler
Durch diesen Kniff beschleunigt sich der gesamte Trainingsprozess beachtlich. Erste Messungen der Wissenschaftler zeigen, dass die Methode das End-to-End-Training im Vergleich zu bestehenden Systemen um das 1,7-Fache verkürzt.
Die mathematische Genauigkeit bleibt dabei vollständig erhalten, sodass die Qualität der generierten KI-Antworten nicht sinkt. Zudem steht am Ende des Trainings ein optimiertes Draft-Modell zur Verfügung, das sich direkt für den späteren Betrieb der Software nutzen lässt. Der Quellcode für das neue System liegt bereits als Open Source auf der Plattform GitHub bereit.