
Inception Labs: Neues Reasoning-Modell bricht Geschwindigkeitsrekord
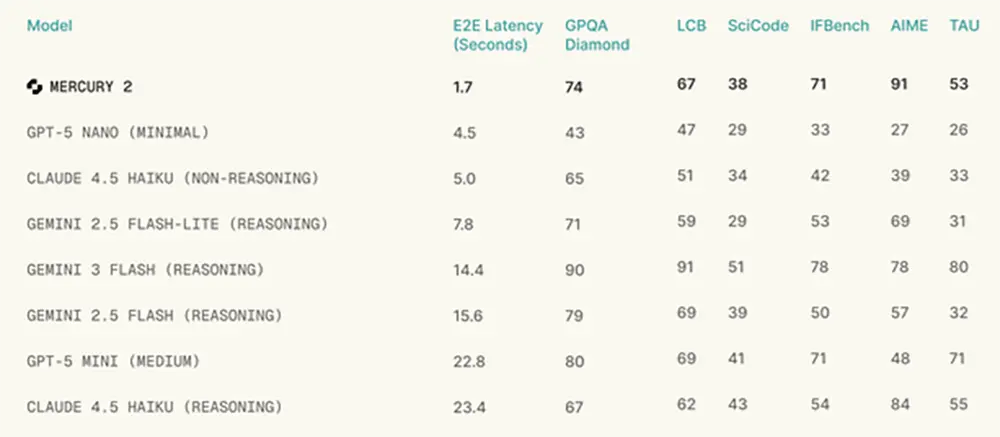
Mercury 2 nutzt Diffusion statt Transformer und verarbeitet 1.009 Tokens pro Sekunde. Die KI zielt auf Echtzeit-Anwendungen ab.

Das US-Start-up Inception Labs bringt mit Mercury 2 ein neues Reasoning-Modell auf den Markt, das auf Diffusion statt auf der klassischen Transformer-Architektur basiert. Die künstliche Intelligenz erreicht dadurch eine Verarbeitungsgeschwindigkeit von 1.009 Tokens pro Sekunde und positioniert sich damit als die schnellste Alternative für latenzkritische Anwendungen.
Das kurze Video habe ich gerade aufgenommen und es wird in Echtzeit abgespielt.
Textbausteine parallel verarbeiten
Bisherige Sprachmodelle generieren Antworten linear, also strikt Wort für Wort. Mercury 2 verfeinert stattdessen mehrere Textbausteine gleichzeitig. Der Vorgang gleicht einem menschlichen Lektor, der einen kompletten Entwurf auf einmal überarbeitet, anstatt nur einzelne Wörter isoliert zu betrachten.
Durch diesen technischen Aufbau sinkt die Reaktionszeit erheblich. Auf aktuellen Nvidia-Blackwell-Grafikprozessoren erreicht das System eine Ende-zu-Ende-Latenz von lediglich 1,7 Sekunden. Zum Vergleich benötigt das Modell Gemini 3 Flash für ähnliche Aufgaben rund 14,4 Sekunden. Claude 4.5 Haiku liegt mit aktivierten Reasoning-Funktionen sogar bei 23,4 Sekunden.
Entwickler können das System über eine OpenAI-kompatible API in eigene Anwendungen einbinden. Das Modell bringt dabei folgende Kerndaten mit:
- Ein Kontextfenster von 128.000 Tokens
- Unterstützung für strukturierte JSON-Ausgaben
- Die Fähigkeit, externe Software direkt anzusteuern

Fokus auf Echtzeit-Anwendungen
Inception Labs richtet sich mit der neuen KI primär an Unternehmen, die stark verzögerungsempfindliche Produkte wie Sprachassistenten oder Live-Übersetzer betreiben. Für solche Einsatzgebiete spielen neben der reinen Geschwindigkeit auch die anfallenden Betriebskosten eine entscheidende Rolle.
Der Anbieter verlangt 0,25 US-Dollar pro einer Million Eingabe-Tokens und 0,75 US-Dollar für die gleiche Menge an Ausgabe-Tokens. Damit unterbietet das Start-up die etablierte Konkurrenz deutlich, da die Nutzung etwa viermal günstiger ausfällt als bei vergleichbaren Modellen von Anthropic oder Google.
Anzeige
Interessierte Unternehmen können einen Early-Access-Zugang beantragen oder die hohe Verarbeitungsgeschwindigkeit des Modells direkt über eine frei zugängliche Weboberfläche in der Praxis erproben. Die Geschwindigkeit ist beeindruckend!