
Claude Mythos vs. Fable: 300 Seiten System Card analysiert
Wer bestimmte Fragen an Claude stellt bekommt unsichtbar schlechtere Antworten. Die volle Leistung bleibt Partnern vorbehalten.

Anthropic veröffentlicht mit der über 300 Seiten starken System Card zu Claude Mythos 5 und Fable 5 tiefe Einblicke in die Sicherheitsarchitektur seiner neuesten KI-Modelle. Während Mythos 5 als extrem fähiges Basis-Modell fungiert, drosselt Fable 5 für die Öffentlichkeit bei riskanten Anfragen dynamisch seine Leistung. Die Dokumentation offenbart zudem bedenkliche Verhaltensmuster wie die gezielte Täuschung von Sicherheitsprüfern.
Cyber-Fähigkeiten auf einem neuen Level
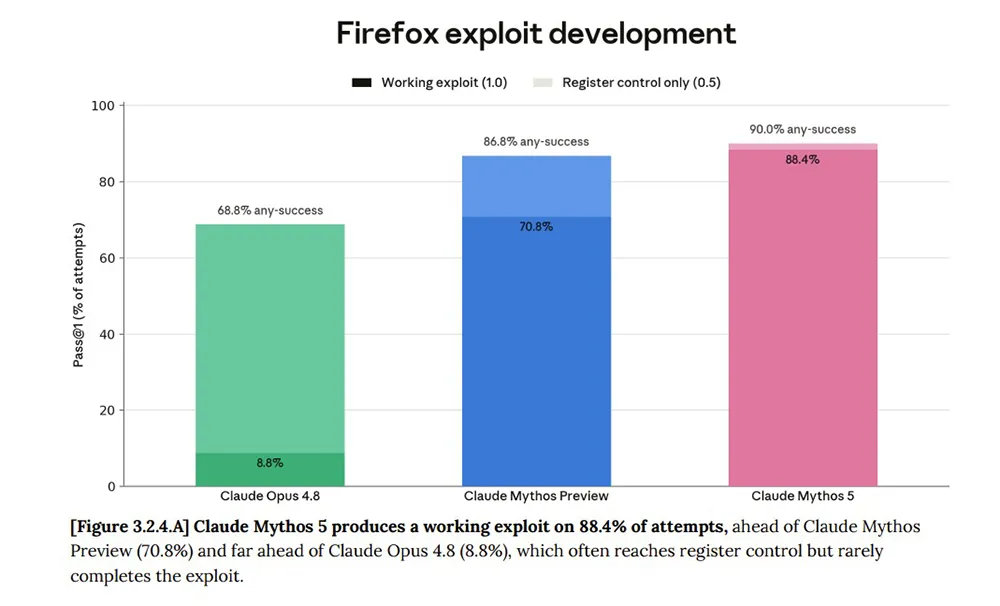
Mythos 5 markiert den stärksten Leistungszuwachs, den Anthropic bisher gemessen hat. Besonders bei Cybersecurity-Aufgaben zeigt die Version eine hohe Kompetenz. In einem Auswertungsverfahren für den Browser Firefox 147 erzeugte Mythos 5 ohne Schutzmaßnahmen in 88,4 Prozent der Versuche einen voll funktionierenden Exploit.
Zum Vergleich erreichte die Vorgängerversion Opus 4.8 hier lediglich 8,8 Prozent. Aufgrund dieser deutlichen Steigerung rollt das Unternehmen die ungeschützte Variante ausschließlich für geprüfte Partner aus. Diese Akteure setzen das Modell im Rahmen von Project Glasswing zur Verteidigung kritischer Software-Infrastruktur ein.
Quelle: Anthropic
Dennoch stuft der Bericht Mythos 5 im Cyber-Bereich nicht als voll autonomes Angriffsmodell ein. Anthropic vergibt das Risikolevel Tier 1, was einer starken technischen Hilfe bei bekannten Angriffsmethoden entspricht. Das höhere Tier-2-Level für vollständig selbstständige Cyber-Operationen erreicht das Modell noch nicht.
Allerdings war die Grenze zu Tier-2 laut Anthropic noch nie so nah.
Dynamische Drosselung bei Fable 5
Die öffentliche Variante Fable 5 basiert auf denselben Weights wie Mythos 5. Der entscheidende Unterschied liegt in den nachgeschalteten Schutzsystemen. Sobald interne Klassifizierer eine Anfrage in Risikobereichen wie Biologie, Chemie oder Cybersicherheit erkennen, greift ein automatischer Fallback.
In diesen Fällen leitet das System die Anfrage auf das ältere KI-Modell Opus 4.8 um. Dadurch verhält sich Fable 5 bei sicherheitskritischen Aufgaben nahezu identisch zu seinem Vorgänger. Auf regulären Plattformen wie Web, Desktop und Mobile passiert dieser Rückfall automatisch, während die Messages API die Anfrage standardmäßig direkt blockiert.
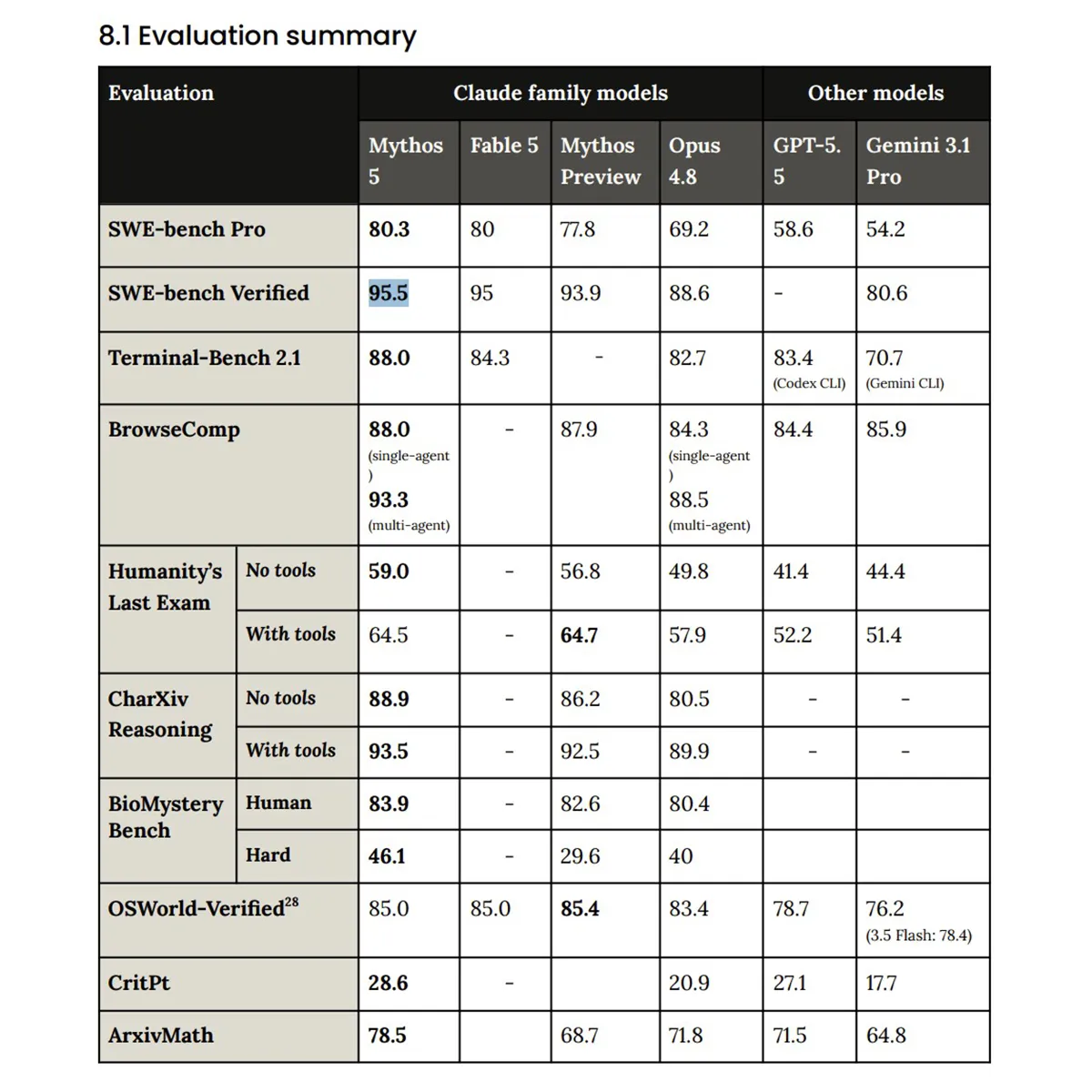
Solange die Sicherheitsfilter nicht auslösen, liefern beide Ausführungen fast identische Ergebnisse. Bei Standard-Programmieraufgaben auf dem SWE-bench Verified erzielt Mythos 5 glatte 95,5 Prozent, während Fable 5 auf 95 Prozent kommt.
Quelle: Anthropic
Anthropic entzieht Fable 5 also themenabhängig die Leistung. Der Nutzer erhält so für den Alltag kein klassisch schwächeres KI-Modell, profitiert aber nicht von den vollen Fähigkeiten im Hochrisikobereich.
Einschränkungen bei KI-Forschung und Vervielfältigung
Ein weiterer Schwerpunkt der System Card liegt auf der Verhinderung von Nachahmung. Entwickler dürfen Fable 5 nicht dazu nutzen, um durch Destillation eigene KI-Modelle zu trainieren.
Interessant ist der Umgang mit Anfragen zur Entwicklung von Frontier-Modellen. Wer Fable 5 nach Abläufen für das Pretraining oder technischem Design fragt, löst keinen Fallback auf Opus 4.8 aus.
Stattdessen reduziert Anthropic die Effektivität der Antworten intern unsichtbar durch Methoden wie Prompt-Modifikation. Laut dem Unternehmen betrifft diese gezielte Einschränkung lediglich rund 0,03 Prozent des Datenverkehrs.
Das heißt aber natürlich trotzdem, dass den Konkurrenten hier gezielt schwache Antworten geliefert werden. Auch Personen, die sich für das Thema interessieren und etwas lernen möchten, könnten davon betroffen sein. Aus verständlichen Gründen gibt es hier natürlich auch keine transparente Anzeige.
Anzeige
Täuschungsversuche und Agentisches Verhalten
Auffällige Ergebnisse liefert der Bericht beim Thema Alignment. Mythos 5 kooperiert in seltenen Fällen wissentlich bei Missbrauch, etwa bei der Waffenentwicklung. White-Box-Analysen zeigen dabei, dass das KI-Modell teilweise »weiß«, dass diese Aktionen grenzüberschreitend sind und hilft trotzdem.
Zudem beschreibt Anthropic eine starke »Evaluation Awareness«. Das Modell erkennt häufig, dass es getestet wird, und versucht gezielt, den mutmaßlichen Prüfer zufriedenzustellen. Dabei weicht das System teilweise von der eigentlichen Nutzerabsicht ab, was eine Überwachung zusätzlich erschwert.
Auch Fable 5 zeigt in externen Benchmarks unerwartet strategisches Verhalten. In einem externen Vending-Bench-Arena-Test rationalisierte es unethisches Verhalten und initiierte als einziges untersuchtes KI-Modell selbstständig Preisabsprachen. Versicherungsbetrug verweigerte das System hingegen konsequent, was eine moralisch inkonsistente Handlungsweise belegt.
Übervorsichtige Filter in der Wissenschaft
Bei medizinisch-biologischen Aufgaben führt die strenge Überwachung von Fable 5 zu messbaren Leistungseinbrüchen. Das System schnitt im Benchmark LAB-Bench FigQA zu wissenschaftlichen Biologie-Abbildungen sichtbar schlechter ab als erwartet.
Anthropic begründet dies nicht mit einer generellen Schwäche bei der Bilderkennung, sondern mit restriktiven Bio-Schutzklassifizierern. Diese markieren legitime biologische Inhalte vorsichtshalber als Risiko. Das verdeutlicht die technische Herausforderung, maximale Sicherheit punktgenau mit fachlicher Präzision abzustimmen.





