
GPT 5 und Gemini 3 waren mal gut...
Dieses Modell schlägt die US-Konkurrenz und ist zudem frei verfügbar.

DeepSeek liefert mit der Version V3.2 und der Speciale-Variante ab heute eine Kampfansage an das Silicon Valley. Die neuen Modelle zielen darauf ab, die Leistung von GPT-5 zu erreichen und Googles Gemini 3 Pro im Bereich "Reasoning" – also der logischen Schlussfolgerung – herauszufordern. Für deutsche Unternehmen besonders interessant: Das Modell erscheint unter der Apache-2.0-Lizenz als Open Weights, was den lokalen Betrieb ohne Datenabfluss ermöglicht.
Architektur-Wechsel: Effizienz durch "Sparse Attention"
Die größte technische Neuerung betrifft die Art und Weise, wie das Modell Informationen verarbeitet. DeepSeek identifizierte die ineffiziente Verarbeitung langer Texte als eine Hauptschwäche bisheriger Open-Source-Modelle. Die Lösung nennen die Entwickler "DeepSeek Sparse Attention" (DSA).
Anstatt bei jeder Antwort den gesamten vorangegangenen Text erneut komplett zu prüfen, nutzt DSA ein Indexierungssystem. Das Modell bewertet vorab, welche Textbausteine für die aktuelle Antwort relevant sind, und ignoriert den Rest. Das senkt den Rechenaufwand massiv, ohne die Qualität der Antwort zu beeinträchtigen. Besonders bei langen Dokumentenanalysen macht sich dieser Effizienzsprung bemerkbar.
Anzeige
Strategiewechsel beim Training
Auch beim Training geht der chinesische Anbieter neue Wege. Das Budget für das sogenannte Post-Training – die Phase, in der das Modell mittels menschlichem Feedback (Alignment) und Verstärkungslernen (Reinforcement Learning) feinjustiert wird – wurde drastisch erhöht. Flossen früher nur rund ein Prozent der Mittel in diesen Schritt, sind es bei V3.2 über zehn Prozent der gesamten Trainingskosten.
Um diese Qualität zu erreichen, trainierte DeepSeek das System in über 4.400 synthetischen Aufgabenumgebungen und nutzte spezialisierte "Lehrer-Modelle" für Mathematik und Programmierung, um hochwertige Trainingsdaten zu generieren.
Benchmarks: Stark bei Agenten, knapp hinter Gemini
In den harten Zahlen zeigt sich ein differenziertes Bild. Bei mathematischen Tests wie dem AIME 2025 erreicht V3.2 mit 93,1 Prozent fast das Niveau von GPT-5 (High), muss sich aber Googles Gemini 3 Pro (95,0 Prozent) geschlagen geben.
Anders sieht es aus, wenn das Modell "arbeiten" muss. In praktischen Szenarien, in denen die KI als autonomer Agent agiert, zieht DeepSeek vorbei. Im "SWE Multilingual"-Benchmark, der echte GitHub-Probleme simuliert, löst V3.2 beeindruckende 70,2 Prozent der Aufgaben. GPT-5 kommt hier nur auf 55,3 Prozent. Das macht das Modell besonders für Entwickler attraktiv, die KI-Agenten für komplexe Software-Tasks einsetzen wollen.
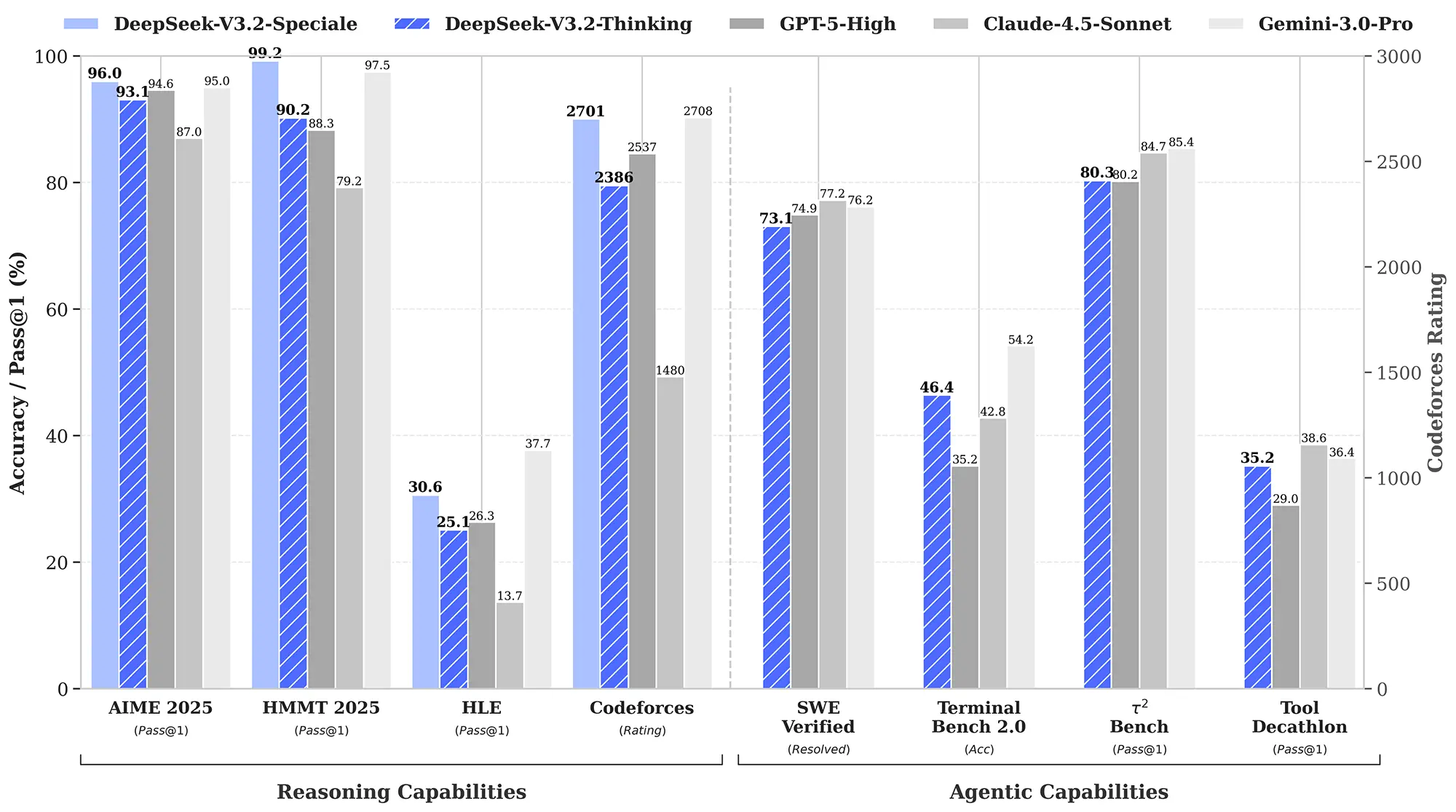
Quelle: Deepseek
Speciale-Edition: Gold-Niveau mit hohem Verbrauch
Parallel zum Allrounder erscheint "DeepSeek-V3.2-Speciale". Diese Version operiert mit gelockerten Beschränkungen für die Länge der Gedankenketten (Chain-of-Thought). Das Resultat ist extreme Präzision: Bei der Internationalen Informatik-Olympiade 2025 erreichte das Modell Gold-Niveau.
Dieser Scharfsinn hat jedoch seinen Preis. Das Speciale-Modell verbraucht für die Lösung komplexer Probleme im Schnitt 77.000 Token, während Konkurrent Gemini 3 Pro ähnliche Aufgaben mit 22.000 Token bewältigt. Wegen dieser Latenz und der höheren Kosten empfiehlt DeepSeek für den Standard-Einsatz das effizientere V3.2-Hauptmodell.
Fazit: Echte Konkurrenz für US-Abos
DeepSeek gibt offen zu, dass die Wissensbreite noch nicht ganz an die US-Vorbilder heranreicht. Dennoch ist V3.2, insbesondere durch die Apache-Lizenz und die starke Agenten-Performance, eine ernstzunehmende Alternative. Es erhöht den Druck auf OpenAI massiv, da Entwickler nun eine kostenlose, lokal betreibbare Option haben, die in der Praxis oft genauso gut funktioniert wie die teuren Bezahl-Dienste.