
Qwen3.5 von Alibaba: Gigantisches Sprachmodell für lokale KI-Agenten
Das multimodale Sprachmodell mit 397 Milliarden Parametern fordert GPT-5.2 und Claude Opus 4.5 erfolgreich heraus.

Alibaba veröffentlicht Qwen3.5: Erstes Open-Weight-Modell mit Fokus auf KI-Agenten
Alibaba hat mit Qwen3.5-397B-A17B das erste Open-Weight-Modell der neuen Generation unter der Apache-2.0-Lizenz veröffentlicht. Das multimodale Sprachmodell zielt speziell auf den Einsatz als autonomer KI-Agent ab und verarbeitet Text sowie Medien nativ.
Architektur und Hardware-Bedarf
Das Modell Qwen3.5-397B-A17B ist ab sofort frei verfügbar. Alibaba stellt die Gewichte unter der permissiven Apache-2.0-Lizenz im Netz bereit. Entwickler können das Open-Weight-Modell dadurch kommerziell ohne strenge Einschränkungen in eigenen Projekten nutzen.
Technisch handelt es sich um ein fortschrittliches Mixture-of-Experts-Modell. Das System wählt für jede spezifische Aufgabe nur spezialisierte Teilnetze aus. Von den insgesamt 397 Milliarden Parametern sind bei einer Abfrage lediglich 17 Milliarden aktiv.
Dieser Aufbau senkt den Rechenaufwand während der Texterstellung ganz erheblich. Der Speicherbedarf bleibt aufgrund der gewaltigen Gesamtgröße jedoch enorm hoch. Je nach Komprimierung (Quantisierung) belegt das Modell geschätzt 200 bis über 400 Gigabyte an Arbeits- oder Grafikspeicher. Nutzer benötigen für den lokalen Betrieb daher teure und extrem leistungsstarke Server-Hardware.
In den nächsten Tagen und Wochen sollen aber auch noch deutlich kleinere Modelle erscheinen.
Anzeige
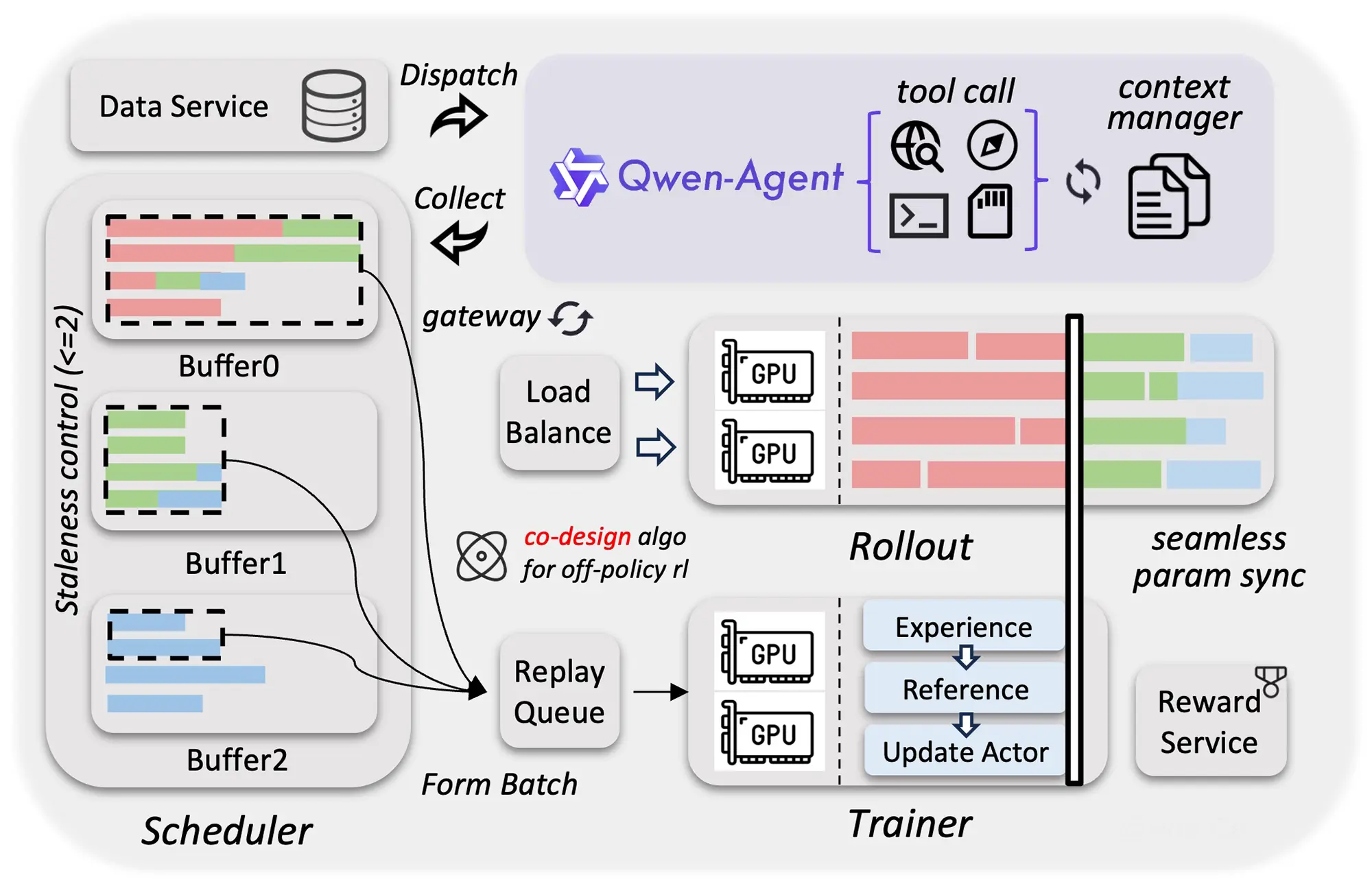
Native Multimodalität für Agenten
Eine Besonderheit der neuen Qwen3.5-Serie ist die native Multimodalität. Das Modell verarbeitet verschiedene Datentypen direkt in einem einzigen neuronalen Netz. Dazu gehören einfache Texte, Bilder, lange Dokumente und hochauflösende Videos.
Frühere KI-Systeme schalteten oft separate Modelle für die Bildverarbeitung und Textverarbeitung hintereinander. Dieser integrierte Ansatz reduziert typische Informationsverluste zwischen den einzelnen Modulen. Das System versteht den Kontext von verschachtelten Videoinhalten dadurch wesentlich präziser.
Die Entwickler rücken den Einsatz als autonomen KI-Agenten stark in den Fokus. Das Modell soll künftig selbstständig im Internet recherchieren und lokale Dateien fehlerfrei analysieren. Die native Integration aller Medientypen bildet dafür die notwendige technische Basis.
Quelle: Alibaba
Skalierung durch Trainingsumgebungen
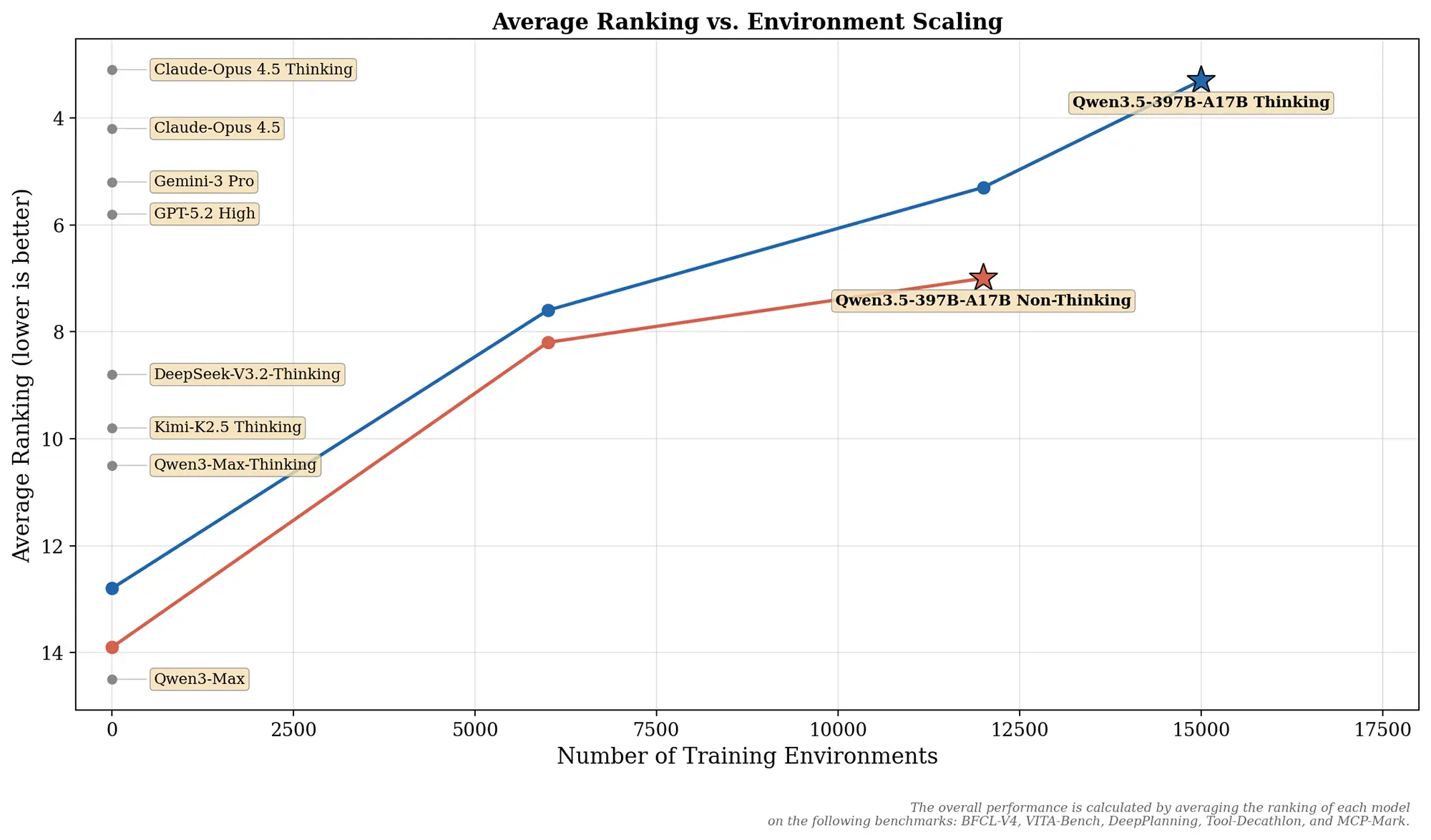
Alibaba zeigt in einer veröffentlichten Grafik den genauen Zusammenhang zwischen Modellleistung und Trainingsumgebungen. Die Entwickler haben die Menge an simulierten Umgebungen während des Trainings stark erhöht. Sie skalierten die Anzahl der Szenarien auf bis zu 15.000 Umgebungen.
Eine Umgebung stellt dabei ein spezifisches Szenario in einem Computersystem dar. Darin trainiert das Modell konkrete Handlungen und komplexe Interaktionen mit Software. Die vorliegenden Daten belegen eine klare Leistungssteigerung bei zunehmender Anzahl dieser Trainingsszenarien.
Die Modellvariante mit aktivierter Denk-Funktion erreicht bei 15.000 Umgebungen eine durchschnittliche Platzierung von 3,5. Damit schließt Qwen3.5-397B-A17B zu sehr starken proprietären Modellen wie Claude-Opus 4.5 auf.
Die Standardversion ohne diese spezielle Denk-Funktion landet im direkten Vergleich auf dem siebten Rang. Sie wurde im Vorfeld mit knapp 12.000 Umgebungen umfassend trainiert. Der beobachtete Sprung verdeutlicht den positiven Effekt des zusätzlichen Rechenaufwands für die Planung.
Quelle: Alibaba
Benchmarks zeigen beeindruckende Leistung
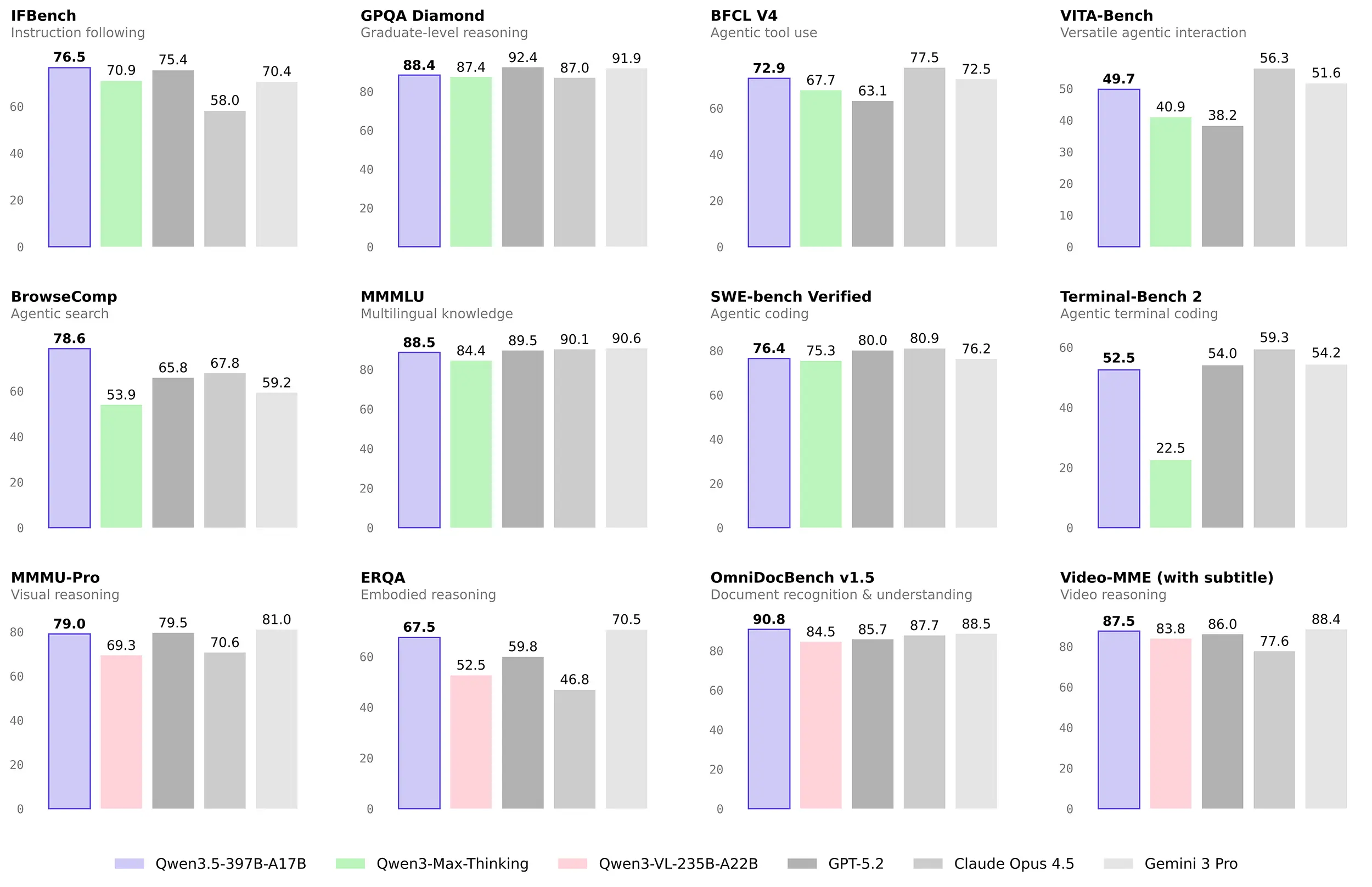
Ein genauer Blick auf die Benchmark-Ergebnisse offenbart ein äußerst starkes Bild für die Nutzer. Bei der reinen Befehlsausführung im bekannten IFBench führt das neue Alibaba-Modell. Es setzt sich dort mit 76,5 Punkten an die Spitze des Testfeldes.
Quelle: Alibaba
Auch bei der agentenbasierten Websuche schneidet das große Modell sehr gut ab. Im etablierten Test BrowseComp erreicht es überzeugende 78,6 Punkte. Die komplexe Dokumentenanalyse im OmniDocBench v1.5 entscheidet Qwen mit 90,8 Punkten ebenfalls eindeutig für sich. Mit dieser Punktzahl lässt es namhafte Konkurrenten wie GPT-5.2 und Claude Opus 4.5 hinter sich.
In anderen Disziplinen zeigen sich nur sehr kleine, verzeihliche Rückstände auf die teure Konkurrenz. Bei komplexen Programmieraufgaben im SWE-bench Verified erreicht das Modell beachtliche 76,4 Punkte. Hier führen die geschlossenen Modelle Claude Opus 4.5 und GPT-5.2 das restliche Feld zwar an. Für ein kostenloses Open-Weight-Modell ist dieser Wert dennoch ein großer Erfolg.
Ein ähnliches Bild zeigt sich beim logischen Schließen im anspruchsvollen Test GPQA Diamond. Dort liegt das System mit 88,4 Punkten nur denkbar knapp hinter dem proprietären GPT-5.2.
Bei der visuellen Analyse im MMMU-Pro liefert das Sprachmodell ebenfalls extrem starke Werte. Es ordnet sich mit exzellenten 79,0 Punkten nur minimal hinter dem Platzhirsch Gemini 3 Pro ein. Die Entwickler liefern mit dem Release ein beeindruckend starkes Gesamtpaket für den lokalen Agenten-Einsatz.