
Mira Muratis erstes KI-Modell schlägt gesamte Konkurrenz
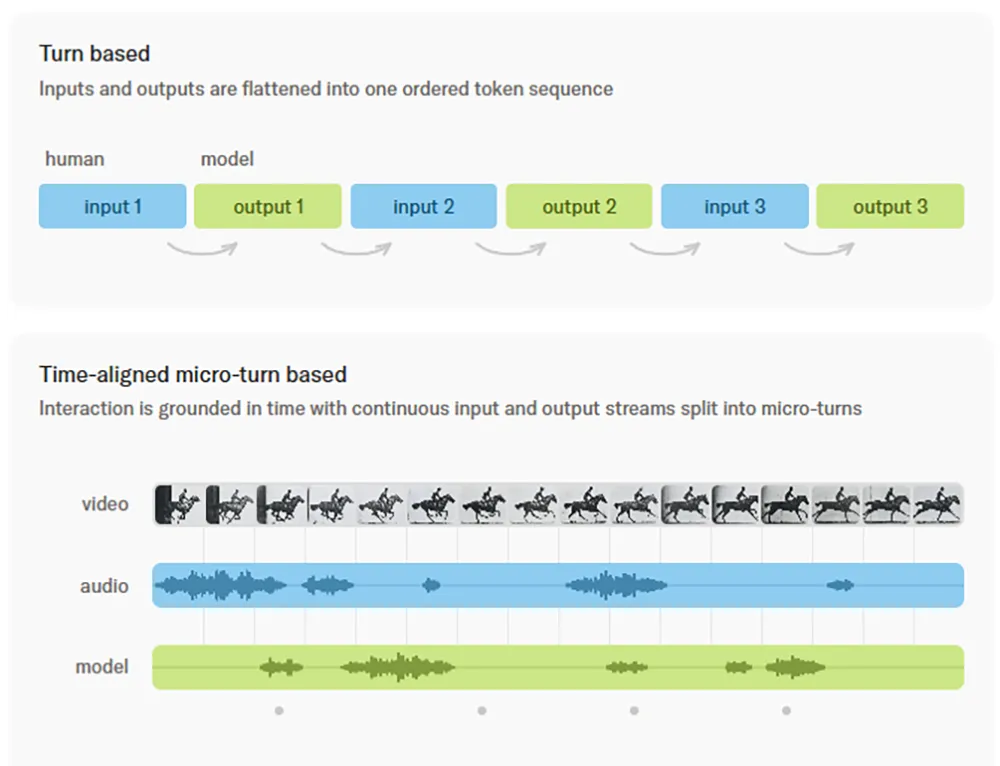
Die neuen »Interaction Models« von Thinking Machines verarbeiten Audio und Video simultan und in ultrakurzen Micro-Turns von 200 Millisekunden.

Thinking Machines beendet das Zeitalter der künstlichen Sprechpausen. Mit der Vorstellung der »Interaction Models« präsentiert das neue Unternehmen von Mira Murati eine Architektur, die Audio, Video und Text simultan verarbeitet. Statt auf das Ende einer Eingabe zu warten, agiert das KI-Modell nativ in Echtzeit.
Der Abschied vom Wartespiel
Bisherige KI-Modelle funktionieren nach dem Prinzip eines Funkgeräts: Eine Seite spricht, die andere wartet passiv ab. Erst nach Abschluss der Eingabe beginnt die Verarbeitung, was einen spürbaren Stillstand in der Zusammenarbeit bedeutet. Interaction Models lösen diese starre Struktur durch kontinuierliche Datenströme auf. Während das KI-Modell Informationen wahrnimmt, antwortet es im selben Moment. Diese Dynamik ermöglicht eine menschliche Interaktionsform, bei der Unterbrechungen und Zwischenrufe zum Standard gehören.
Technische Grundlage bilden sogenannte Micro-Turns von lediglich 200 Millisekunden. In diesen kurzen Intervallen verarbeitet das KI-Modell Eingangsdaten und generiert gleichzeitig eigene Token. Ein entscheidender Vorteil liegt im Verzicht auf externe Hilfssysteme für die Sprechpausenerkennung. Bei herkömmlichen Echtzeit-Anwendungen steuern oft einfache Algorithmen, wann die KI antworten darf. Hier entscheidet die Intelligenz des KI-Modells selbstständig über den richtigen Moment für einen Einwurf.
Quelle: Thinking Machines
Die duale Intelligenz-Architektur
Das System vertraut auf eine funktionale Teilung, um Tempo und Tiefe zu vereinen. Ein schnelles Interaction Model übernimmt die unmittelbare Kommunikation und sichert die permanente Präsenz im Dialog. Parallel dazu agiert ein Background Model für Aufgaben, die intensives Reasoning oder den Zugriff auf externe Funktionen erfordern. Sobald dieses Hintergrundmodell Resultate liefert, webt die Interaktionsschicht diese Informationen organisch in das laufende Gespräch ein.
Lange Schweigephasen bei schwierigen Anfragen gehören damit der Vergangenheit an. Während das Hintergrundmodell eine komplexe Suche durchführt, bleibt das KI-Modell ansprechbar und kann Rückfragen stellen oder den Fortschritt kommentieren. Diese Architektur ermöglicht laut Thinking Machines eine Skalierbarkeit, bei der größere KI-Modelle nicht zwangsläufig langsamer in der Reaktion werden. Vielmehr verbessert sich die Qualität der Zusammenarbeit mit zunehmender Rechenleistung.
Anzeige
Überlegenheit im Benchmark-Vergleich
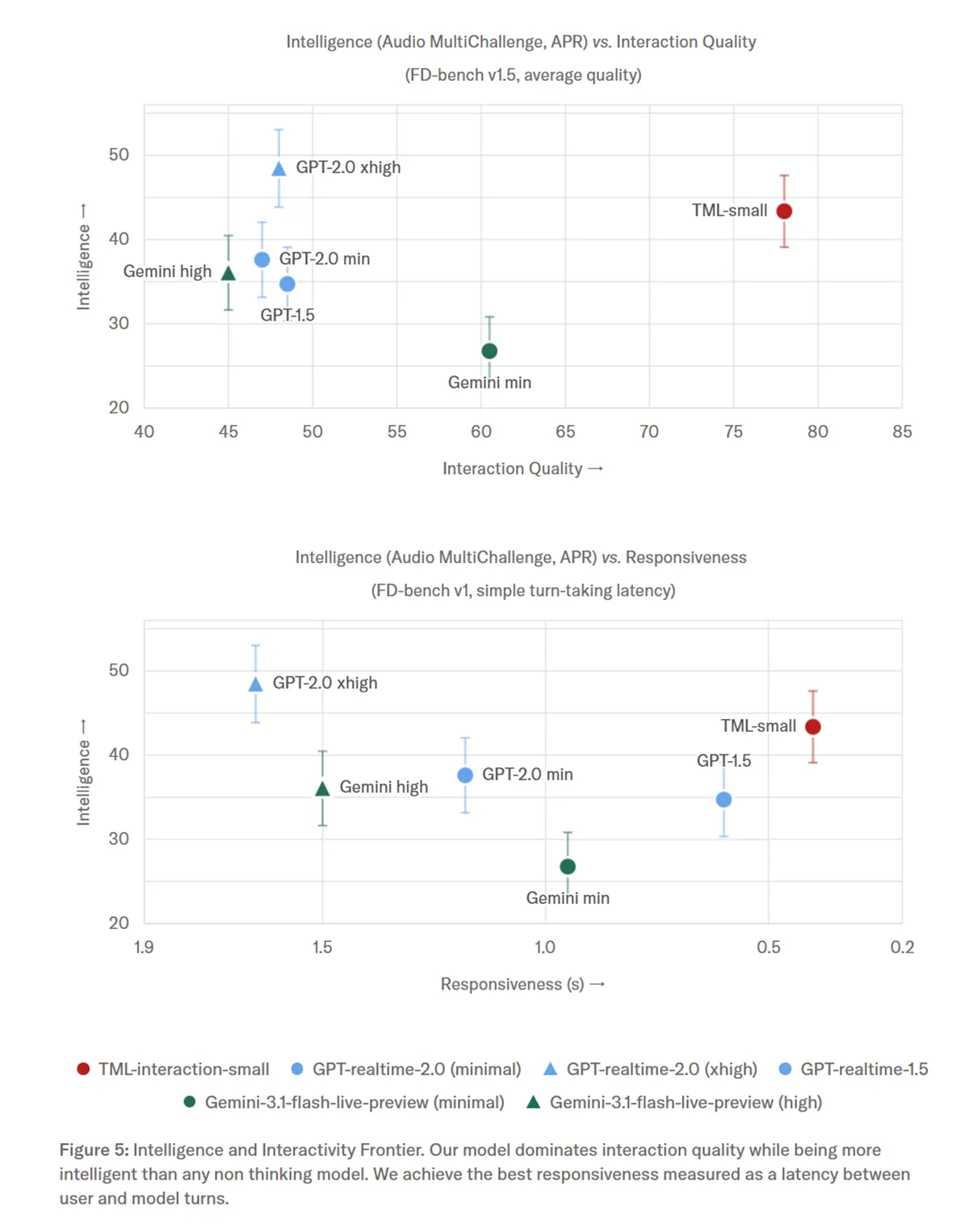
In den veröffentlichten Benchmarks demonstriert das KI-Modell »TML-Interaction-Small« seine Stärken in puncto Reaktionsgeschwindigkeit. Mit einer Latenz von nur 0,40 Sekunden im FD-bench V1 unterbietet es Konkurrenten wie GPT-2.0-min mit seinen 1,18 Sekunden deutlich. Die Grafik-1 verdeutlicht, dass das KI-Modell trotz sehr hoher Interaktionsqualität eine Intelligenz beibehält, die andere Instant-Modelle übertrifft. Während GPT-2.0 xhigh zwar leicht klüger agiert, benötigt es eine vierfach höhere Latenz von 1,63 Sekunden für die Antwort.
Quelle: Thinking Machines
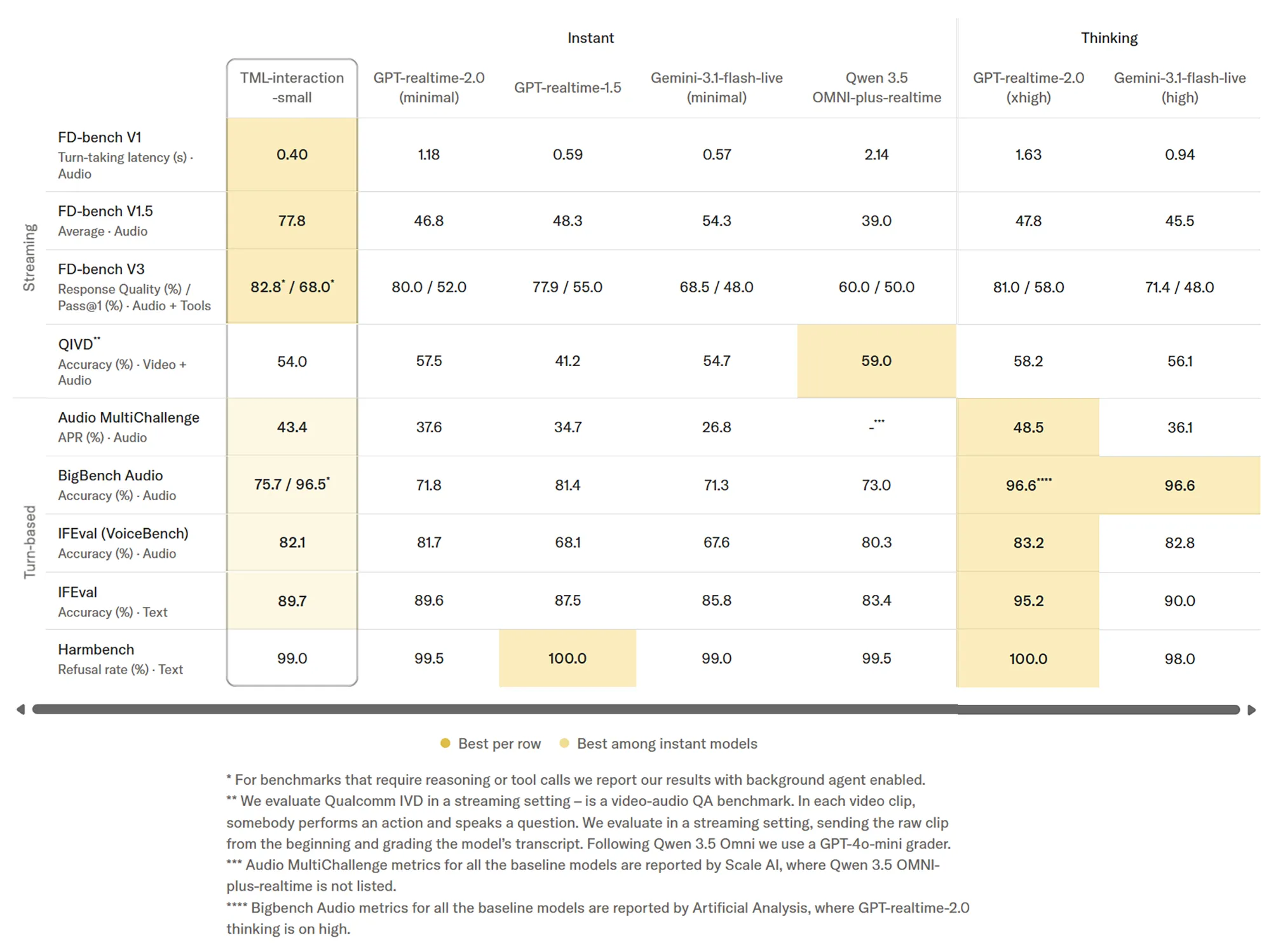
Besondere Fortschritte zeigen sich bei der qualitativen Interaktion und Tool-Nutzung. Im FD-bench V1.5 erreicht das System 77,8 Punkte, während die anderen Modelle kaum über 50% kommen. Die Benchmark-Tabelle listet zudem eine Pass@1-Rate von 68,0 % bei kombinierten Audio- und Tool-Aufgaben auf. Diese Zahlen belegen, dass die native Integration von Multimodalität stabilere Ergebnisse liefert als herkömmliche Koppelungen verschiedener Systeme.
Quelle: Thinking Machines
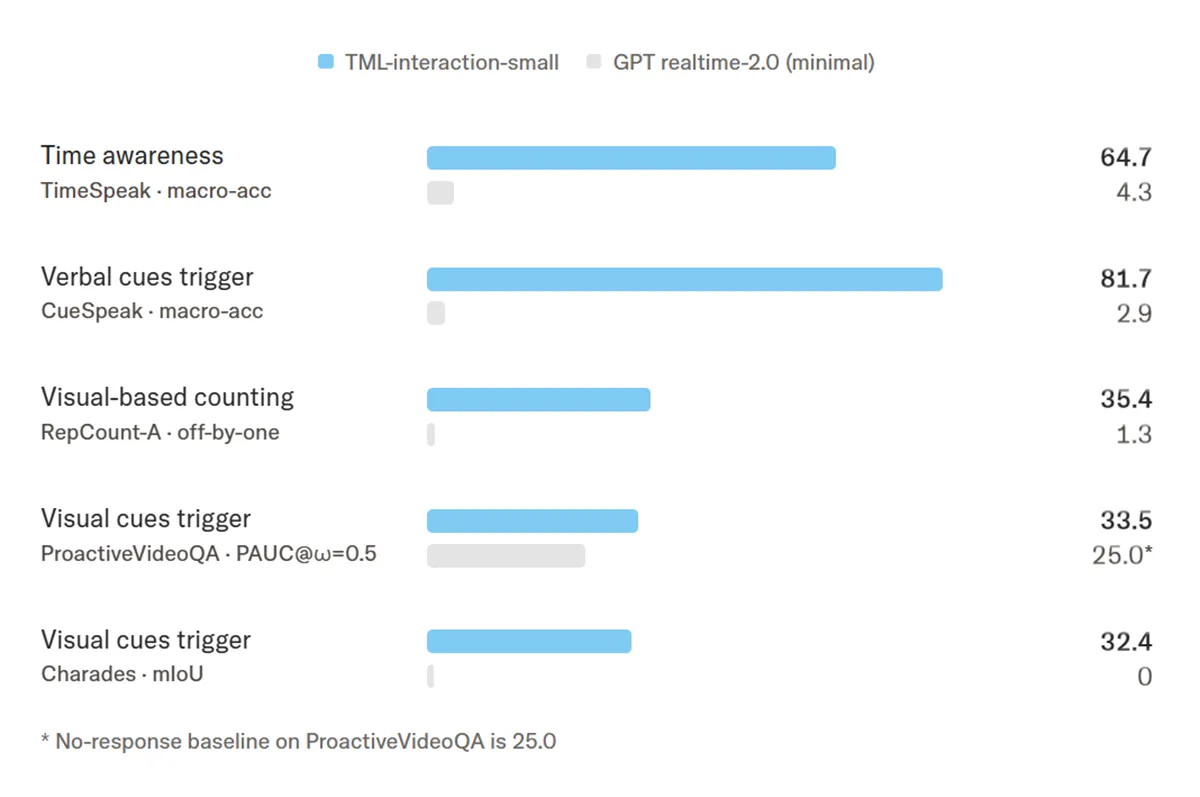
Völlig neue Dimensionen eröffnet das KI-Modell bei proaktiven Aufgaben, die Zeitbewusstsein oder visuelle Analyse erfordern. Im TimeSpeak-Test erreicht das KI-Modell eine Genauigkeit von 64,7 %, während GPT Realtime-2.0 bei lediglich 4,3 % stagniert. Wie auf dem Bild zu sehen ist, glänzt das System zudem bei der visuellen Analyse von Bewegungsabläufen. Mit einem Wert von 35,4 beim RepCount-A-Benchmark kann das KI-Modell Übungen präzise zählen, woran bisherige KI-Modelle fast vollständig scheiterten.
Quelle: Thinking Machines
Technische Hürden und Verfügbarkeit
Trotz der Fortschritte bleiben infrastrukturelle Herausforderungen bestehen. Die permanente Verarbeitung von Video- und Audiostreams lässt den Kontextspeicher schnell anwachsen, was die Verwaltung langer Sitzungen erschwert. Zudem setzt die Nutzung eine äußerst stabile und breitbandige Verbindung voraus, da Verzögerungen im Netzwerk die Echtzeit-Erfahrung beeinträchtigen. Das aktuelle KI-Modell nutzt eine Mixture-of-Experts-Struktur mit 276 Milliarden Parametern, von denen 12 Milliarden aktiv pro Token arbeiten.
Thinking Machines plant, die Research Preview in den kommenden Monaten schrittweise für Fachkreise zu öffnen. Größere KI-Modelle befinden sich bereits in der Entwicklung, sind aktuell jedoch noch zu rechenintensiv für eine flüssige Ausspielung. Das Ziel bleibt eine KI, die nicht nur klüger wird, sondern sich nahtlos in den menschlichen Arbeitsfluss integriert. Damit endet die Ära des klassischen Prompting zugunsten einer echten, synchronen Zusammenarbeit zwischen Mensch und KI.
Wir sind seit langem mal wieder komplett beeindruckt!





