
Die Funktionen von Seedance 2.0 sind von einer anderen Welt
Das neue Modell schlägt Sora 2 und Veo 3.1 und ermöglicht eine präzise Steuerung und starkes Audio.

ByteDance hat heute mit Seedance 2.0 ein neues generatives KI-Modell vorgestellt, das die Lücke zu Konkurrenten wie Sora 2 schließen soll. Das System integriert Video-, Audio- und Bildgenerierung in einem einzigen Modell und verspricht durch neue Steuermechanismen präzise Eingriffe in die Bildkomposition.
Die Entwicklung generativer Video-KI bewegt sich weg von der reinen Erzeugung kurzer Clips hin zu kontrollierbaren Produktionswerkzeugen. Während frühere Modelle oft mit physikalischen Halluzinationen und mangelnder zeitlicher Kohärenz zu kämpfen hatten, adressiert ByteDance mit Seedance 2.0 primär die Steuerbarkeit der Ausgabe. Das Modell wurde als "All-in-One"-Lösung konzipiert, die nicht nur Pixel generiert, sondern diese kontextabhängig mit passenden Audiospuren verknüpft.
Quelle: bytedance
Benchmark-Analyse: Vorsprung durch Daten
ByteDance untermauert die Leistungsfähigkeit von Seedance 2.0 mit einer Reihe interner und synthetischer Benchmarks. Die veröffentlichten Daten suggerieren eine Überlegenheit gegenüber aktuellen westlichen Modellen, müssen jedoch – wie bei Herstellerangaben üblich – mit einer gewissen Skepsis betrachtet werden, bis unabhängige Tests vorliegen.
Anzeige
Im Bereich Text-zu-Video (Text-to-Video) zeigen die Benchmark-Grafiken eine signifikante Verbesserung in der semantischen Umsetzung komplexer Prompts. Ein häufiges Problem generativer Modelle ist das "Vergessen" von Details bei langen Eingabebefehlen. Seedance 2.0 soll laut Datenblatt eine höhere Trefferquote bei der korrekten Platzierung von Objekten und der Einhaltung physikalischer Grundregeln aufweisen. Die Metriken deuten darauf hin, dass die zeitliche Konsistenz – also das stabile Beibehalten von Objekten über mehrere Sekunden hinweg – optimiert wurde, was das typische Flimmern reduziert.
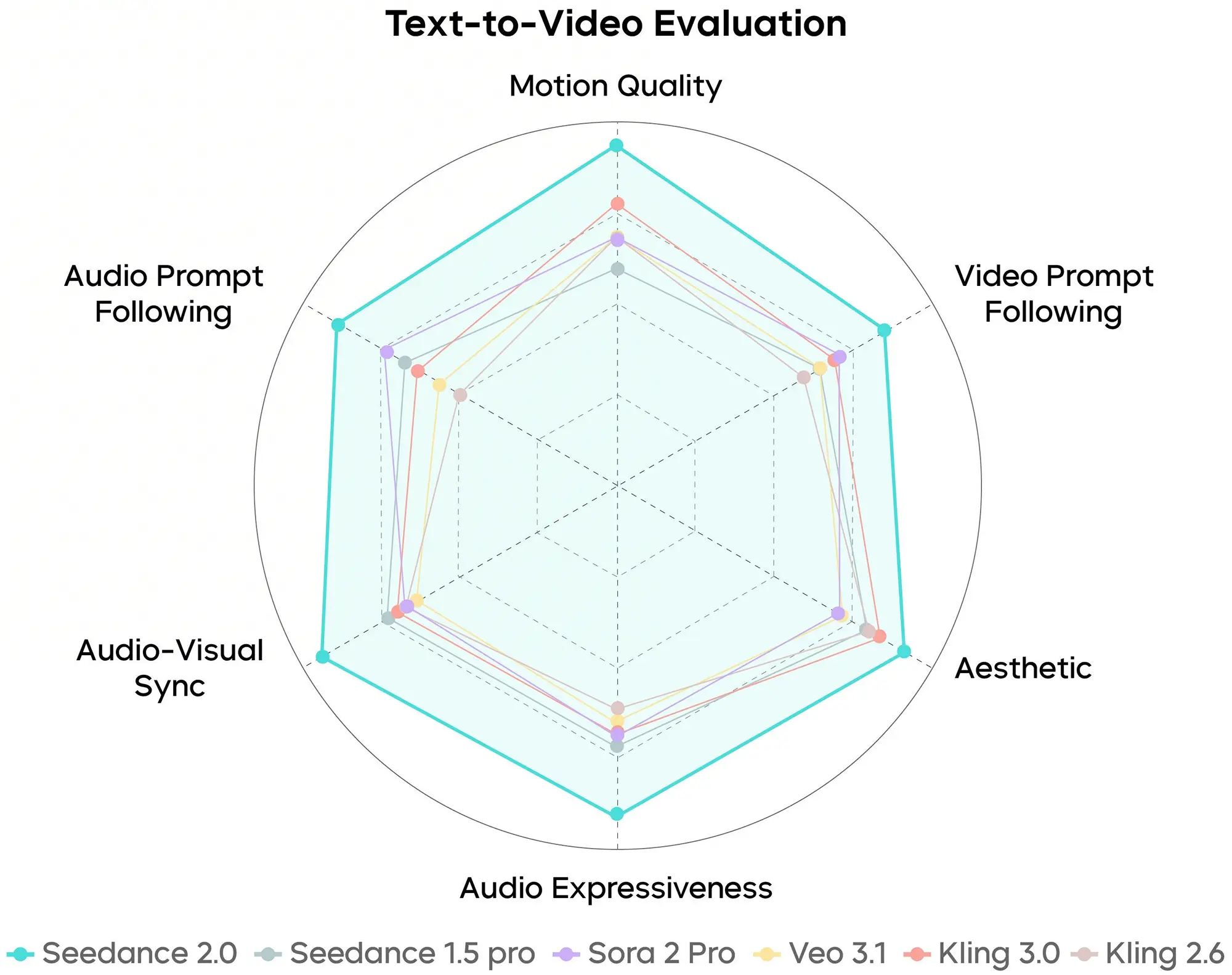
Quelle: bytedance
Die Auswertung der Bild-zu-Video (Image-to-Video) Performance hebt die Identitätsbewahrung hervor. Eine der größten Herausforderungen besteht darin, ein statisches Referenzbild zu animieren, ohne dass sich die Gesichtszüge oder strukturelle Merkmale des Motivs verfremden. Die von ByteDance präsentierten Kurven zeigen hier einen Vorsprung in der "Subject Fidelity". Das bedeutet, dass das Modell in der Lage ist, die in einem Startbild definierten Informationen (Lichtsetzung, Textur, Geometrie) exakter in die Bewegung zu übersetzen als Vorgängerversionen, die oft zu starken Halluzinationen neigten.
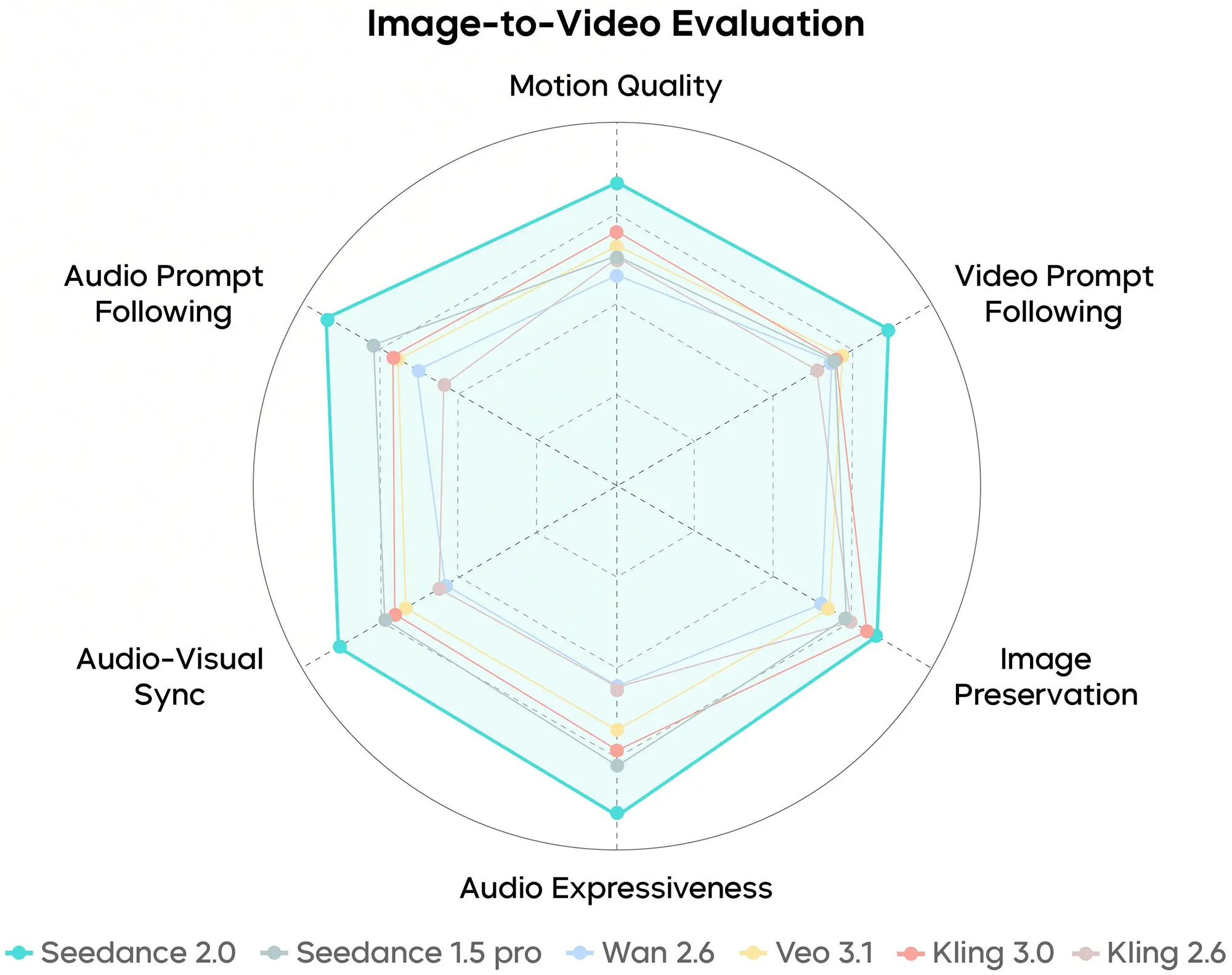
Quelle: bytedance
Besonders betont der Hersteller die Ergebnisse der multimodalen Aufgaben-Evaluation. Hierbei muss das Modell Informationen aus verschiedenen Quellen (z.B. ein Referenzbild, eine Audio-Datei und ein Text-Prompt) gleichzeitig verarbeiten. Die Benchmark-Werte indizieren, dass Seedance 2.0 diese Inputs nicht isoliert betrachtet, sondern korreliert. Ein Beispiel hierfür ist die Lippensynchronität oder die Anpassung der visuellen Stimmung an eine vorgegebene Audiospur. Die Daten legen nahe, dass die Latenz zwischen den Modalitäten minimiert wurde, was für einen flüssigeren Gesamteindruck sorgt.
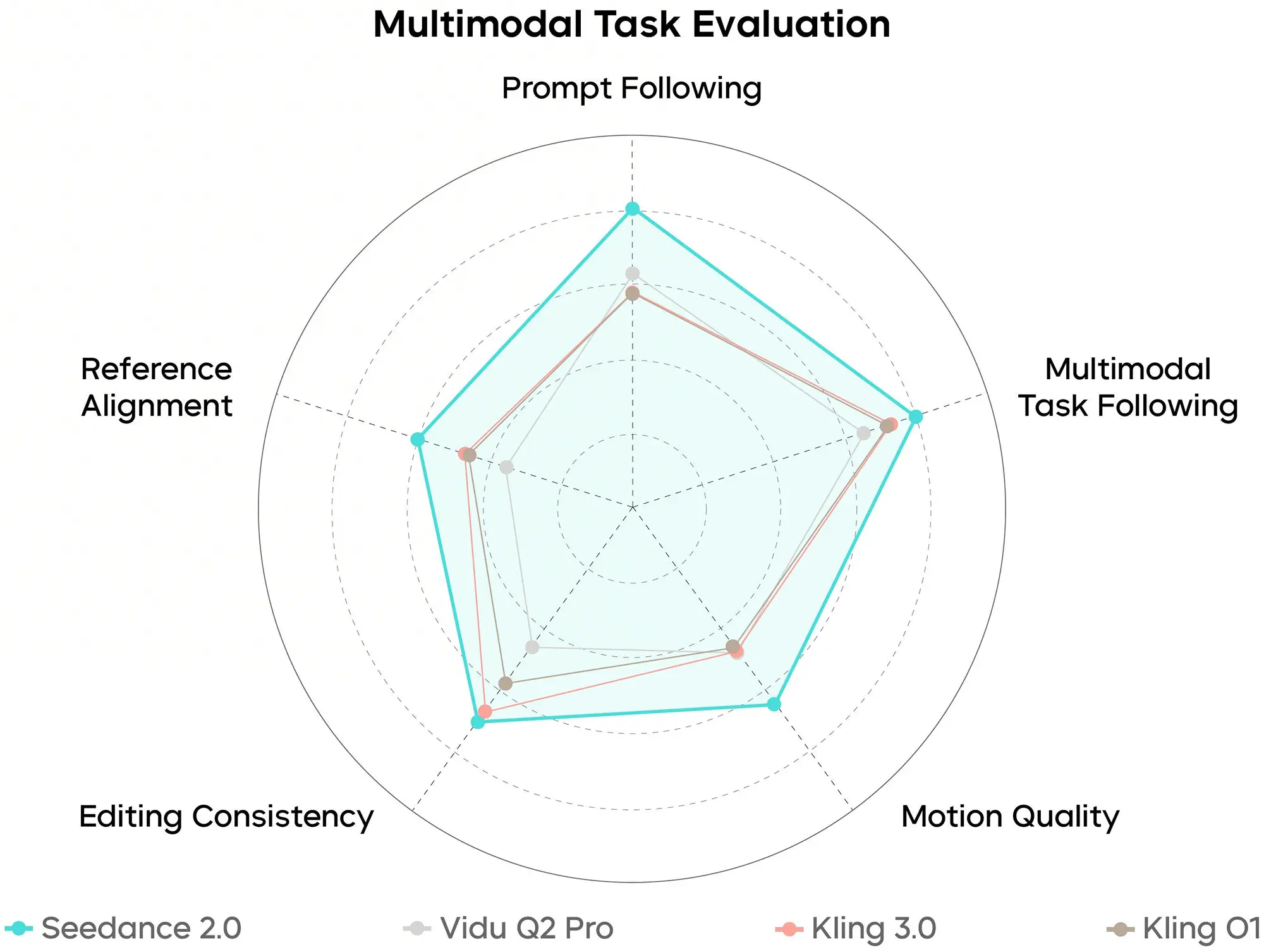
Quelle: bytedance
Granulare Steuerung statt Zufallsgenerator
Das zentrale Verkaufsargument von Seedance 2.0 ist der Übergang von der bloßen Generierung zur "Regie-Führung" (Director-level Control). Bisherige Modelle funktionierten oft nach dem Prinzip einer Blackbox: Der Nutzer gibt Text ein und hofft auf ein brauchbares Ergebnis. Seedance 2.0 implementiert Werkzeuge, die aus der professionellen Videoproduktion entlehnt sind.
Anzeige
Dies zeigt sich insbesondere in der Funktion zur Struktur- und Bewegungsübertragung. Nutzer können ein Referenzvideo hochladen – etwa eine Person, die vor einem Greenscreen agiert oder eine einfache Aufnahme mit dem Smartphone. Das Modell extrahiert die Bewegungsmuster (ähnlich einem Motion-Capture-Verfahren) und überträgt diese auf eine neu generierte Figur. So lässt sich die Gestik eines realen Schauspielers eins zu eins auf einen Anime-Charakter oder eine fotorealistische Kunstfigur mappen. Technisch deutet dies auf eine fortgeschrittene Nutzung von Pose-Estimation-Algorithmen und Depth-Maps hin, die als rigides Grundgerüst für den Diffusionsprozess dienen.
Quelle: bytedance
Ein weiterer technischer Fortschritt liegt in der integrierten Audio-Synthese. Während Video und Audio bisher meist in getrennten Arbeitsschritten und oft mit unterschiedlichen KIs erstellt wurden, generiert Seedance 2.0 den Ton nativ passend zum Bildinhalt. Das System erkennt visuelle Ereignisse – wie das Zuschlagen einer Tür oder das Bellen eines Hundes – und erzeugt parallel die entsprechende Wellenform. Dies reduziert den Post-Production-Aufwand erheblich, da keine externe Sound-Bibliothek oder separate Audio-KI synchronisiert werden muss.
Quelle: bytedance
Der Ersteindruck ist jedenfalls überragend und besser als bei Sora 2 und Veo3.1, also der aktuellen Spitze bei Videogeneratoren.