OpenAI bringt neue KI-Modelle für reaktionsschnelle Subagenten
Bessere Leistung beim Reasoning und kürzere Antwortzeiten. Die kompakten Modelle lösen GPT-5 mini ab.

OpenAI hat die Sprachmodelle GPT-5.4 mini und GPT-5.4 nano offiziell veröffentlicht. Das Unternehmen richtet die neuen Versionen ganz gezielt auf einen speziellen Einsatzzweck aus: Sie sollen als reaktionsschnelle "Subagenten" in automatisierten Arbeitsabläufen dienen.
Fokus auf agentische Systeme
Schon der Vorgänger verarbeitete Bilder, Text und Code nativ. Nun ändert sich jedoch die Philosophie in der praktischen Anwendung. In modernen Umgebungen plant ein großes Hauptmodell komplexe Aufgaben und delegiert die reine Ausführung an kleine, schnelle Worker-Modelle.
Genau für diese ausführende Rolle hat OpenAI GPT-5.4 mini und nano optimiert. Sie richten sich an Entwickler, bei denen die Latenz das direkte Nutzererlebnis bestimmt. Dazu zählen flüssige Coding-Assistenten oder Systeme, die Bildschirminhalte in Echtzeit auslesen.
Beide Modelle arbeiten dabei mehr als doppelt so schnell wie die vorherige Generation. OpenAI hat zudem das Kontextfenster auf 400.000 Token erweitert, damit die KI auch große Code-Datenbanken problemlos am Stück überblickt.
Anzeige
Starke Werte bei Programmierung und Vision
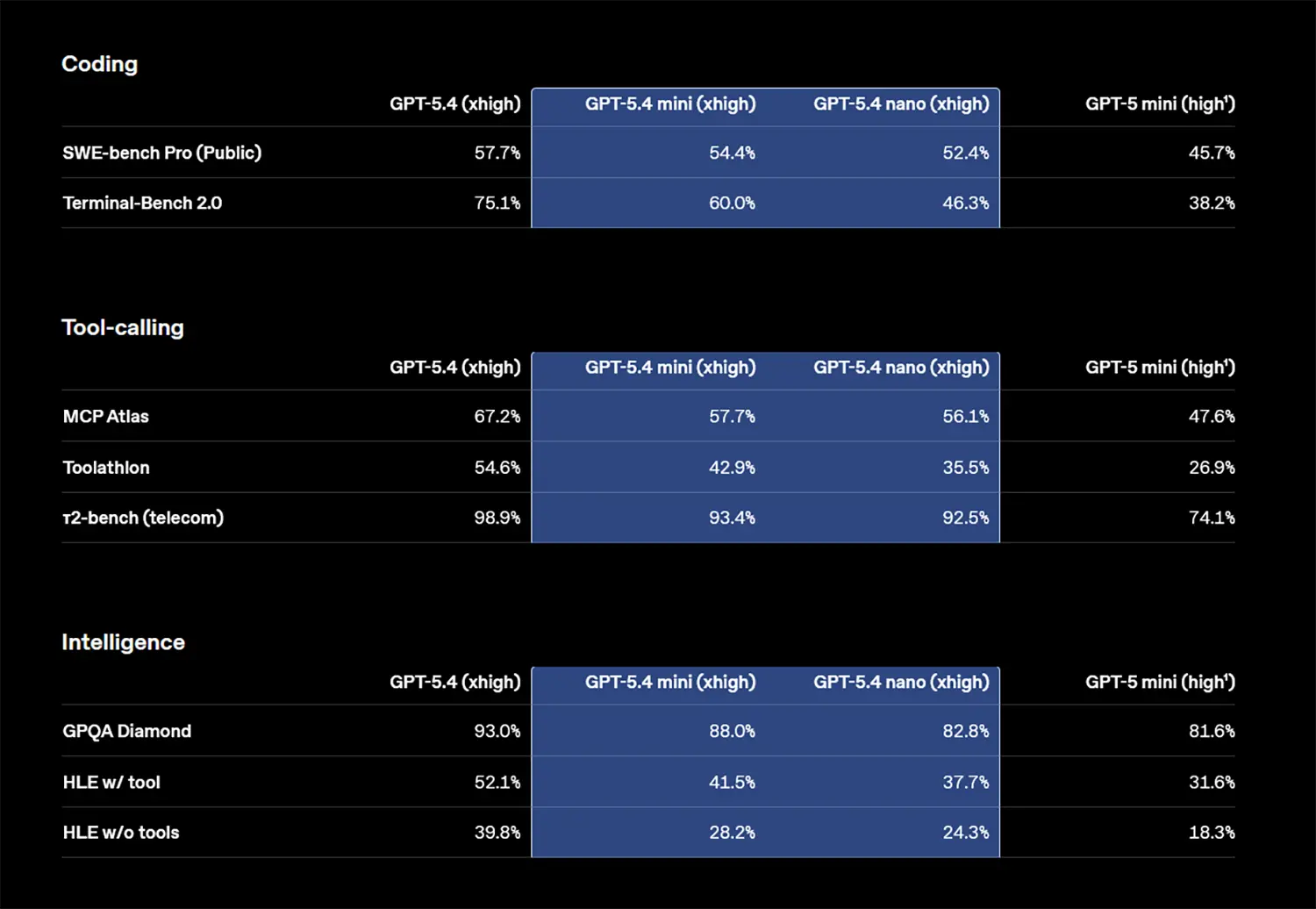
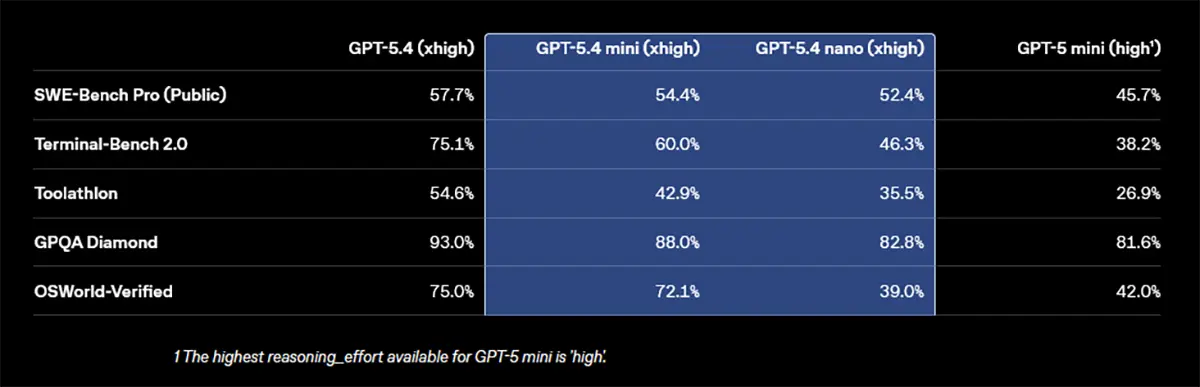
Die aktuellen Benchmarks stützen diese neue Ausrichtung. Bei der Softwareentwicklung (SWE-bench Pro) erreicht GPT-5.4 mini 54,4 %. Das kompaktere nano-Modell kommt auf 52,4 %.
Quelle: OpenAI
Auch bei der visuellen Steuerung von Computern punktet das Update. Im OSWorld-Verified Benchmark erzielt das mini-Modell 72,1 %. Es liegt damit fast gleichauf mit dem großen Flaggschiff GPT-5.4, das 75,0 % erreicht. Bei dieser rein visuellen Aufgabe zeigt das kleine nano-Modell mit 39,0 % allerdings noch Schwächen.
Das logische Denken, das sogenannte Reasoning, wurde ebenfalls in die kleinen Modelle integriert. Im anspruchsvollen GPQA Diamond Benchmark liefert das mini-Modell starke 88,0 % korrekte Antworten. Auch der Zugriff auf externe Programme (Tool-Calling) gelingt deutlich besser. Im Toolathlon-Test steigert sich GPT-5.4 mini auf 42,9 %.
Kosten und Latenz im Praxis-Check
Der eigentliche Sprung zeigt sich in der reinen operativen Effizienz. Messdaten zum SWE-bench Pro verdeutlichen die Vorteile. Eine komplexe Programmier-Aufgabe dauert mit dem großen GPT-5.4 Modell oft über 1.000 Sekunden und kostet den Entwickler rund 0,85 US-Dollar.
GPT-5.4 mini erledigt den gleichen Auftrag in etwa 200 bis 400 Sekunden. Der Preis fällt dabei auf extrem günstige 0,10 bis 0,30 US-Dollar. Wer auf absolute Geschwindigkeit setzt, nutzt GPT-5.4 nano, welches die Ergebnisse in knapp 100 Sekunden liefert.
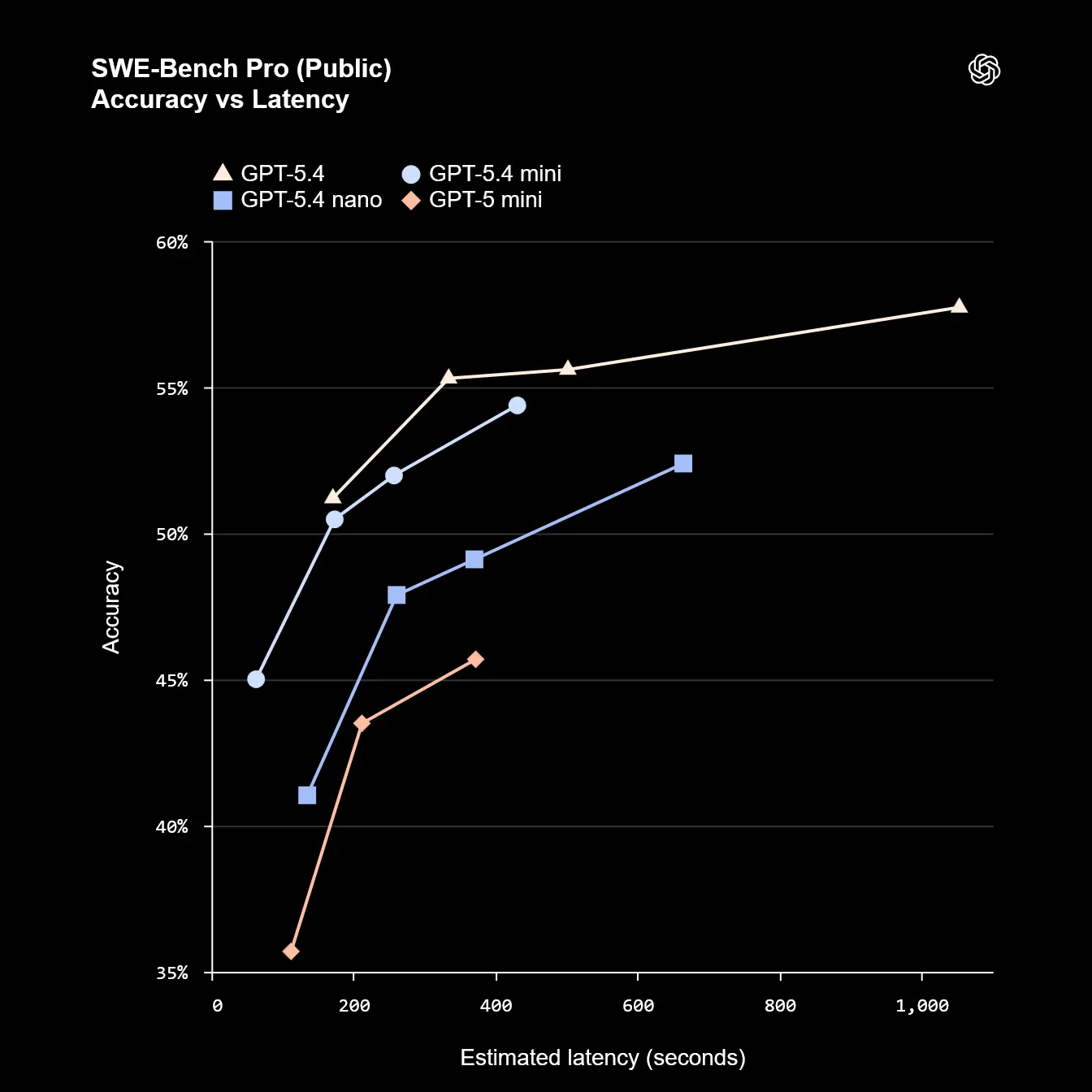
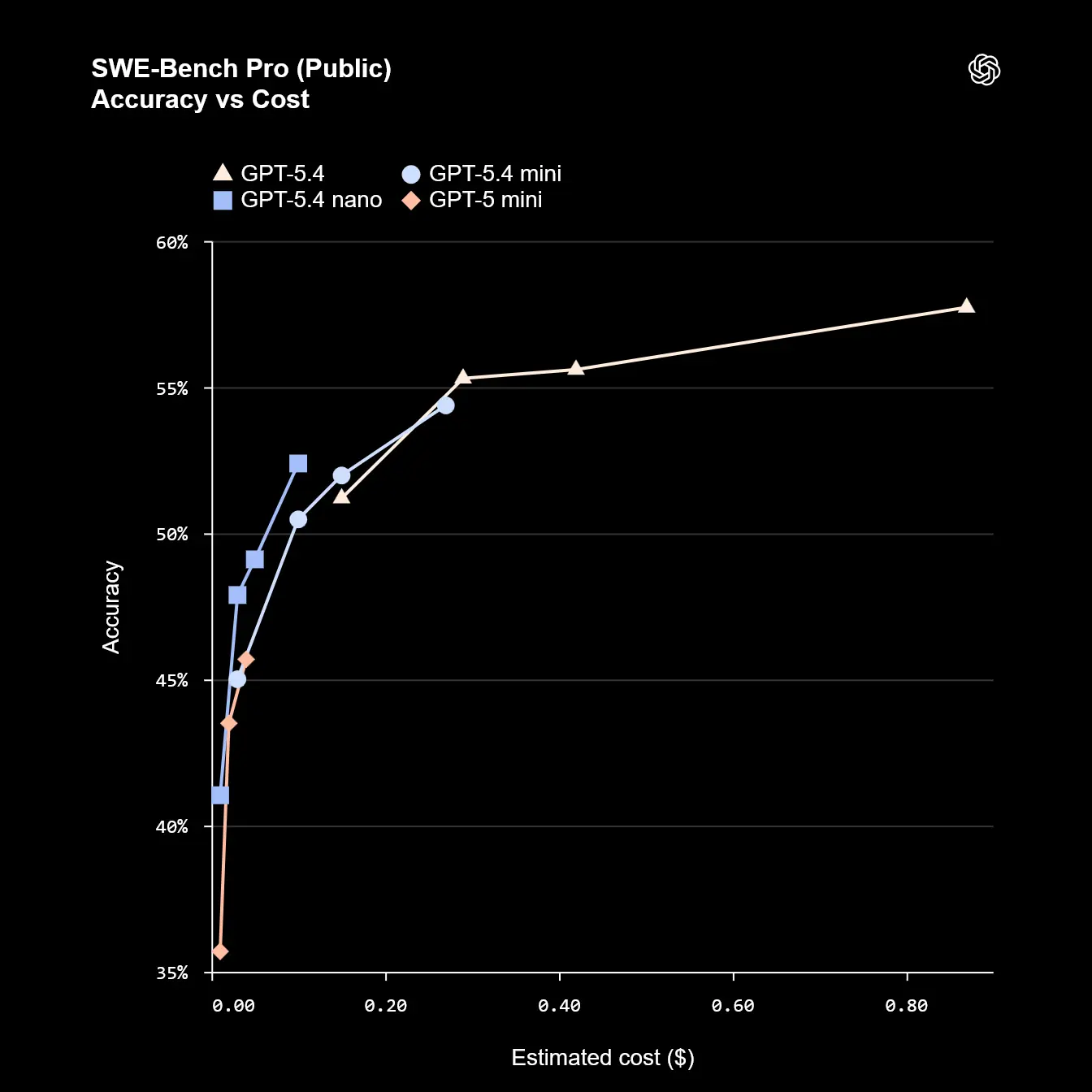
Die finalen Preise für die API-Schnittstelle unterstreichen den Sparkurs. GPT-5.4 mini kostet 0,75 US-Dollar pro Million Input-Token und 4.50 US-Dollar pro Million Output Token. Das nano-Modell wird für lediglich 0,20/1,25 US-Dollar angeboten.
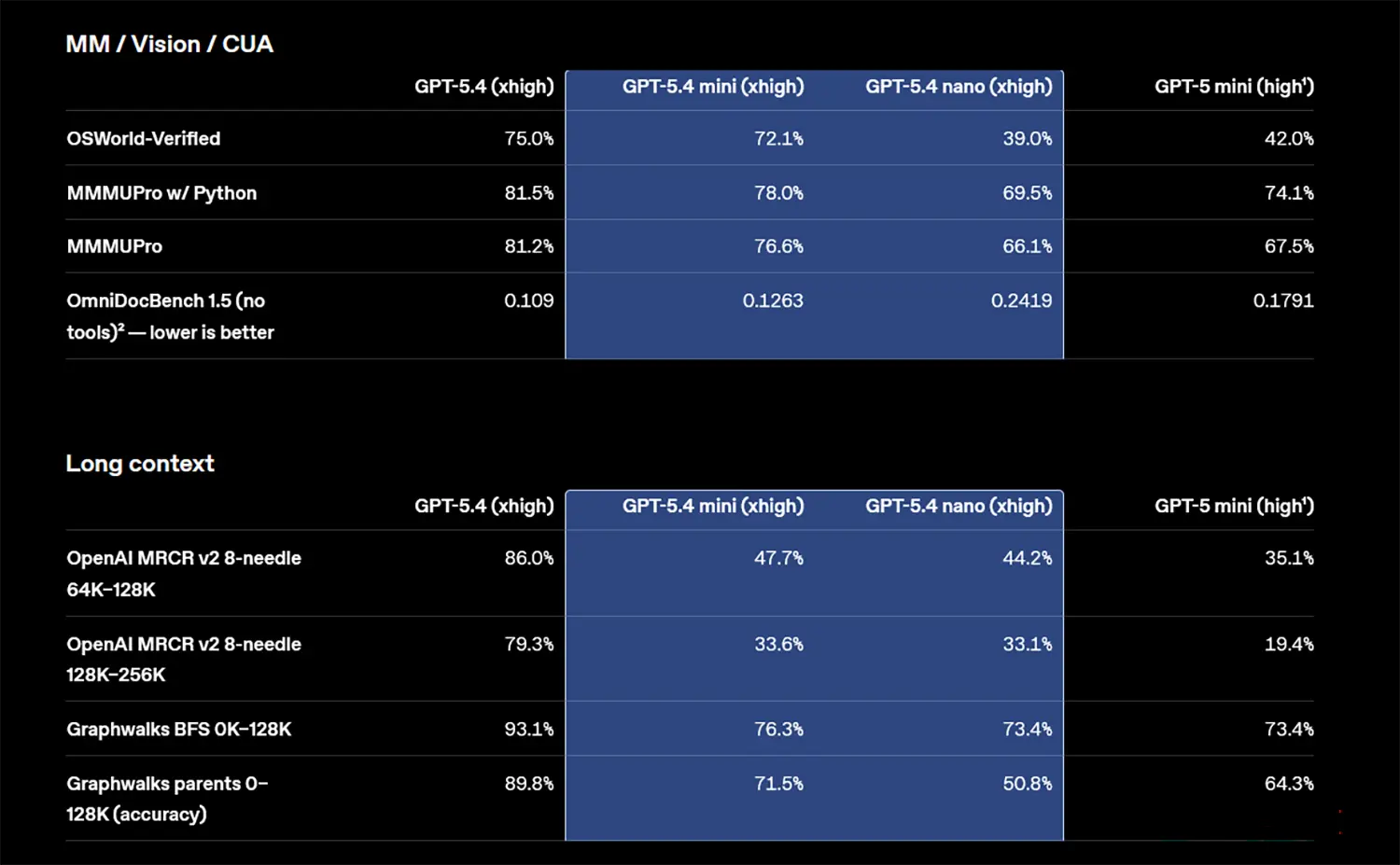
Weitere Benchmarks: