
Neues KI-Modell Mistral Small 4 fordert die Konkurrenz heraus
Mit 119 Milliarden Parametern und flexibler Denkzeit zeigt das französische Start-up, wie effizient moderne Open-Source-Architekturen arbeiten.

Mistral AI hat das neue Sprachmodell Mistral Small 4 veröffentlicht. Die Open-Source-Architektur vereint erstmals Textverständnis, Bildanalyse und komplexe Logik in einem einzigen System und lässt Nutzer die Denkzeit dynamisch steuern.
All-in-One: Flexibilität durch konfigurierbares Reasoning
Das französische KI-Unternehmen führt mit Mistral Small 4 die Fähigkeiten bisheriger Spezialmodelle zusammen. Anstatt je nach Anwendungsfall zwischen einem schnellen Instruct-Modell, dem multimodalen Pixtral oder dem Programmier-Spezialisten Devstral zu wechseln, erhalten Entwickler nun eine einheitliche Lösung für alle Aufgaben.
Eine zentrale Neuerung ist der konfigurierbare Reasoning-Modus. Anwender entscheiden per API-Aufruf direkt im Prompt, ob das Modell sofort antworten oder für komplexe Aufgaben zusätzliche Rechenzeit (Test-Time Compute) aufwenden soll. Braucht ein Nutzer nur eine kurze Übersetzung, reagiert das System direkt. Geht es um tiefgreifende Programmierprobleme, nimmt sich die KI Zeit für interne Denkschritte.
Technisch basiert das unter der freien Apache-2.0-Lizenz stehende Modell auf einer sogenannten Mixture-of-Experts-Architektur (MoE). Von den insgesamt 119 Milliarden Parametern aktiviert das System bei der Verarbeitung eines Token lediglich rund 6 Milliarden. Dafür greift es auf 128 spezialisierte Experten-Netzwerke zu, von denen jeweils vier gleichzeitig arbeiten. Dieser gezielte Abruf hält den Speicherbedarf gering und beschleunigt die Textausgabe erheblich. Ein großes Kontextfenster von 256.000 Token erlaubt zudem die Analyse ganzer Buchreihen oder komplexer Bildeingaben in einem einzigen Durchlauf.
Anzeige
Benchmarks belegen Präzision bei kurzen Antworten
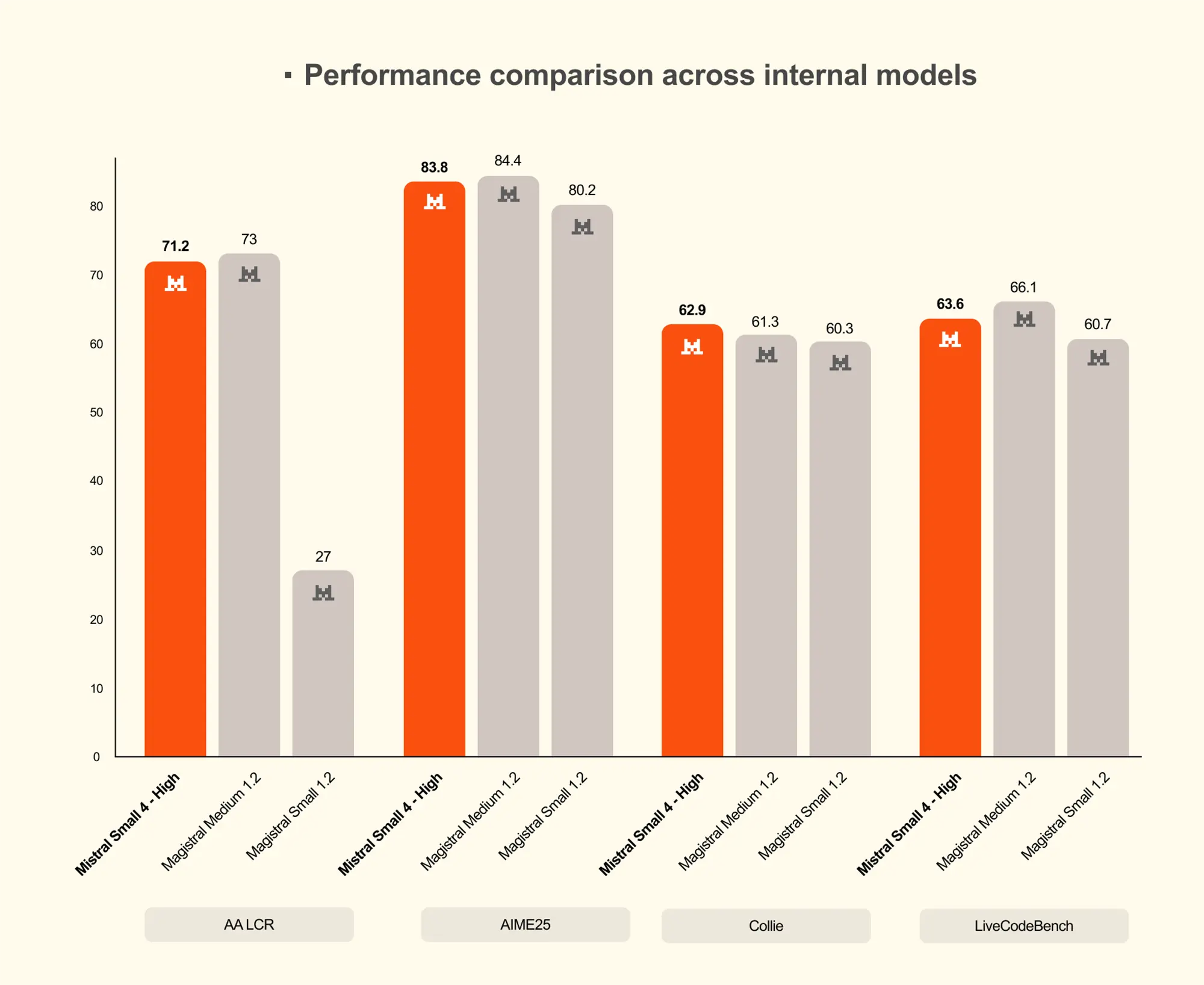
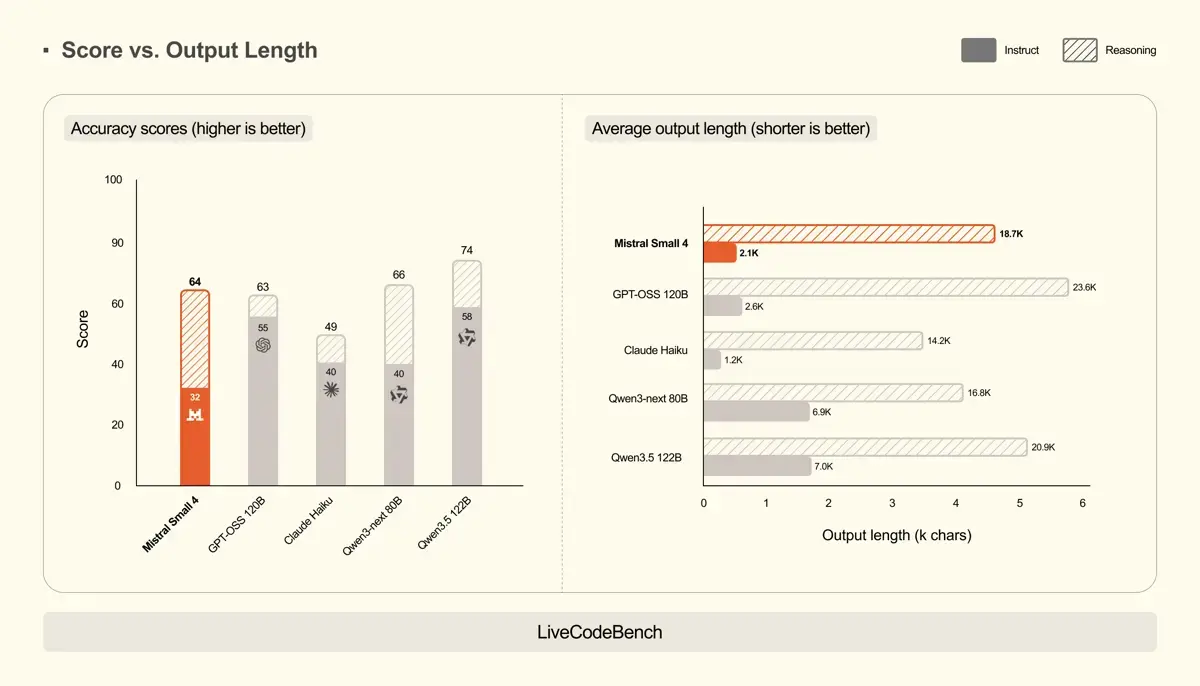
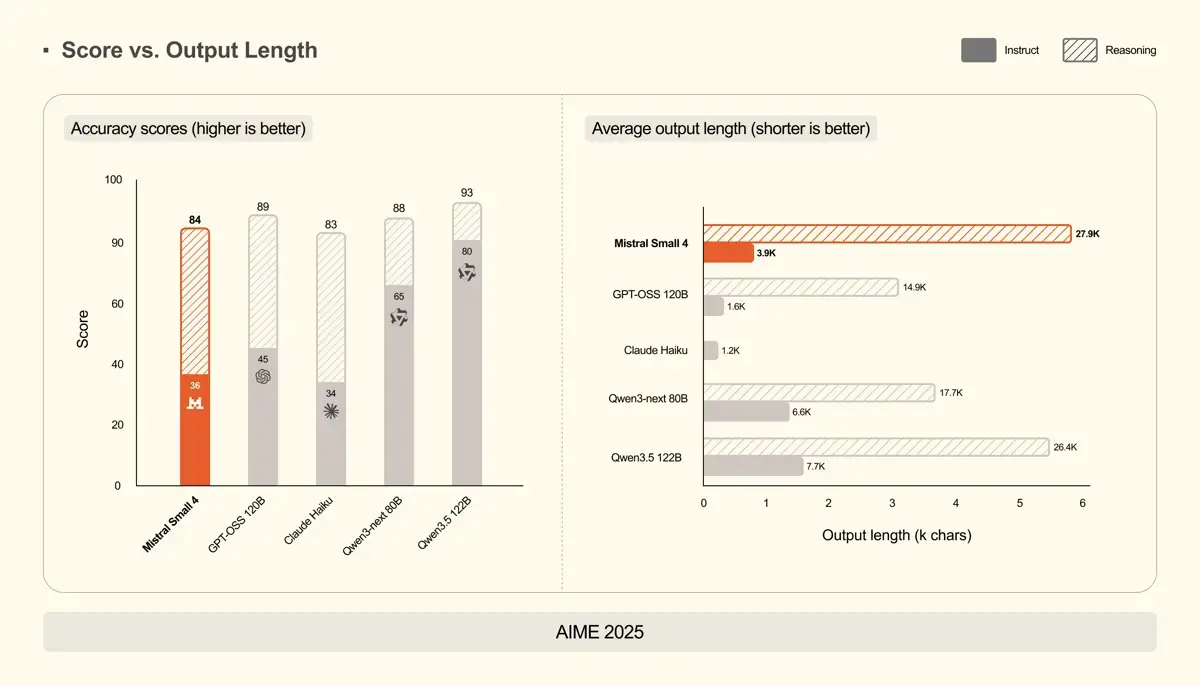
In aktuellen Leistungstests zeigt das Modell eine hohe Effizienz, besonders im Verhältnis von Genauigkeit zur Ausgabelänge. Bei anspruchsvollen Benchmarks liefert der Reasoning-Modus deutliche Leistungssprünge. Im Mathematik-Test AIME 2025 steigt der Score durch die zusätzliche Denkzeit von 36 auf starke 84 Punkte. Ähnlich verhält es sich beim Programmier-Benchmark LiveCodeBench, wo der Wert von 32 auf 64 klettert.
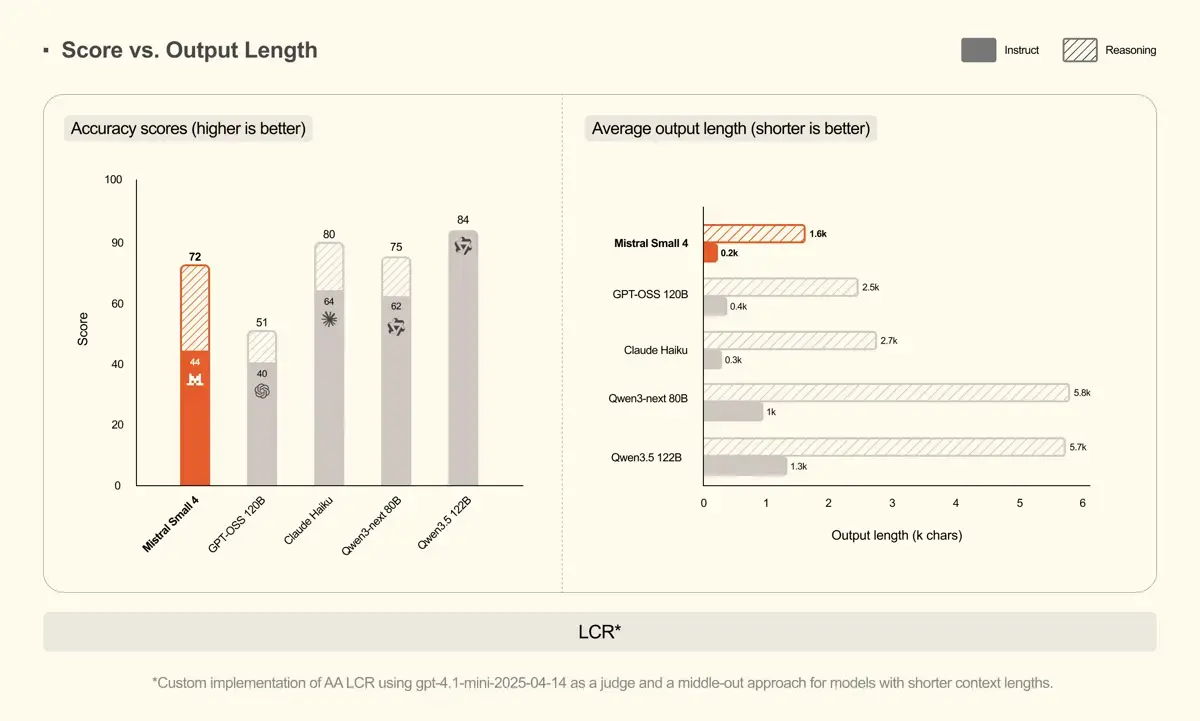
Besonders im internen LCR-Benchmark punktet Mistral Small 4 mit prägnanten Antworten. Im Reasoning-Modus erreicht das Modell 72 Punkte bei einer durchschnittlichen Ausgabelänge von nur 1.600 Token. Zum Vergleich: Das Konkurrenzmodell GPT-OSS 120B kommt hier bei 2.500 Token auf lediglich 51 Punkte, während das deutlich größere Qwen3.5 122B für seine 84 Punkte fast 5.700 Token benötigt. Mistral Small 4 löst komplexe Aufgaben also oft mit deutlich weniger Kosten.
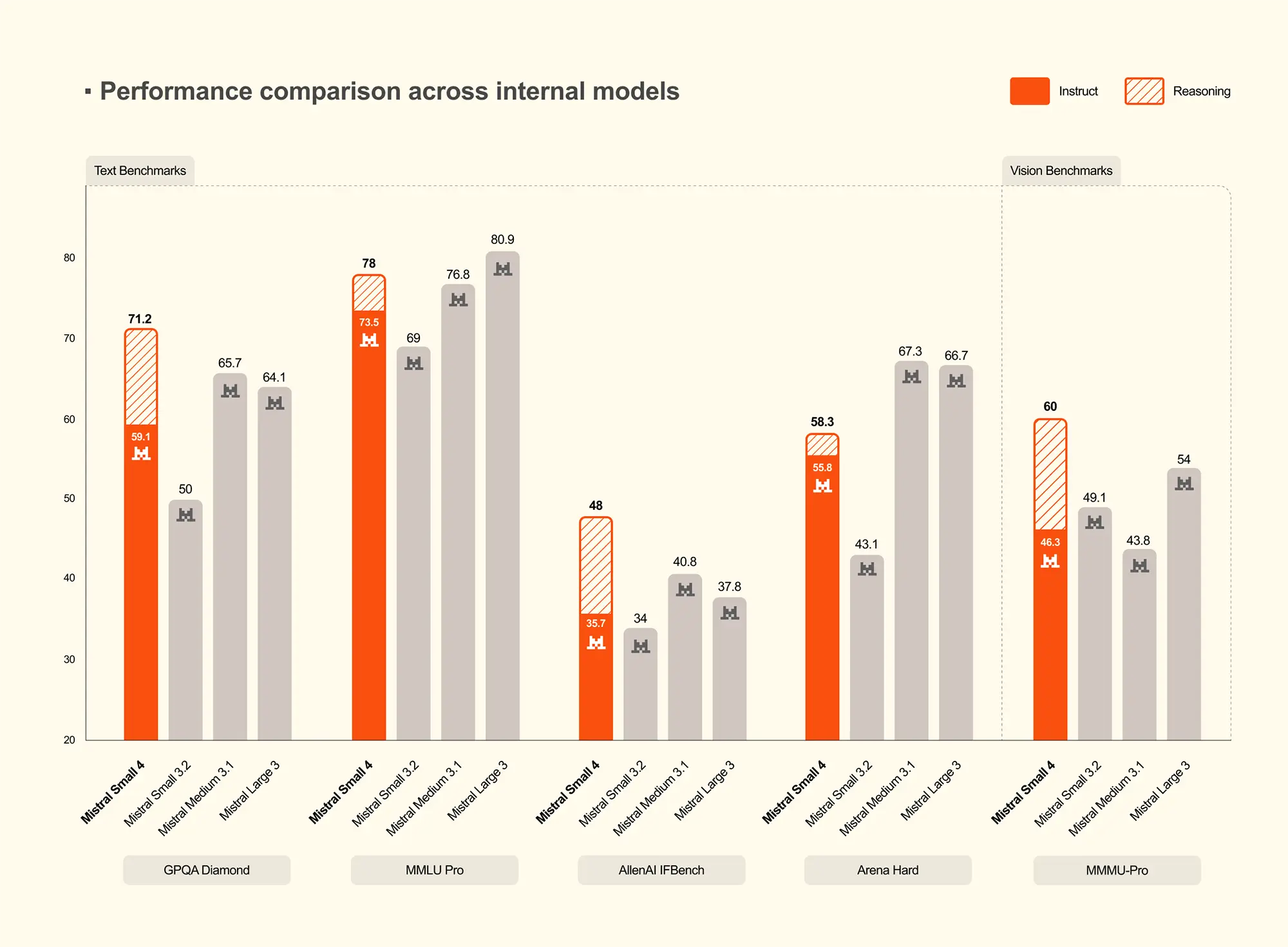
Auch im Vergleich zu den eigenen Vorgängern zeigt sich der technische Fortschritt. Im anspruchsvollen GPQA Diamond Benchmark erzielt die neue Version im Reasoning-Modus 71,2 Punkte und übertrifft damit ältere Modelle wie Mistral Medium 3.1 oder Mistral Large 3 deutlich. Bei visuellen Aufgaben im MMMU-Pro-Test erreicht das Modell sehr gute 60 Punkte.
Quelle: Mistral
Strategische Partnerschaft für offene KI
Parallel zum Release gab Mistral AI die Gründung der NVIDIA Nemotron Coalition bekannt. Als Gründungsmitglied kooperiert das Unternehmen künftig eng mit dem kalifornischen Chipentwickler, um weitere Open-Source-Modelle zu trainieren. Die Partnerschaft kombiniert die Architektur-Expertise der Franzosen mit den enormen Rechenkapazitäten von Nvidia.
Das aktuelle Release unterstreicht diesen Ansatz. Entwickler können nun auf ein hochgradig anpassbares System zugreifen, das die schnelle Verarbeitung eines kleinen Modells mit der logischen Tiefe großer Reasoning-Architekturen verbindet.
