Claude bringt 1M-Kontext und deklassiert Gemini-3 und GPT-5.4
Die KI-Modelle Opus und Sonnet verarbeiten ab sofort eine Million Token. Benchmarks zeigen, dass sie dabei deutlich präziser bleiben als die Konkurrenz.

Anthropic hat das riesige Kontextfenster von einer Million Token für seine KI-Modelle Claude Opus 4.6 und Sonnet 4.6 offiziell für alle Nutzer zugänglich gemacht. Gleichzeitig streicht das Unternehmen den bisherigen 100-Prozent-Aufschlag für lange Texte komplett. Neue Leistungstests zeigen zudem, dass die Sprachmodelle auch bei enormen Datenmengen präzise bleiben und Konkurrenten wie GPT-5.4 auf die hinteren Plätze verweisen.
Einheitlicher Preis für riesige Datenmengen
Bislang war die Analyse extrem großer Datenmengen oft mit hohen Zusatzkosten verbunden. Mit der generellen Verfügbarkeit des neuen Kontextfensters ändert sich das nun. Anthropic berechnet ab sofort für jeden Token den gleichen Preis, unabhängig davon, wie viel Text in das Modell eingespeist wird. Der bisherige 100% Aufpreis für die Nutzung des maximalen Kontextspeichers entfällt damit ersatzlos.
Neben dem Preisvorteil demonstriert das Unternehmen durch neue Benchmarks, dass die Claude-Modelle in der Praxis konstant starke Leistungen erbringen. Das Verarbeiten von Millionen von Wörtern am Stück stellt künstliche Intelligenzen häufig vor Probleme. Viele Modelle vergessen Informationen aus dem Anfangsbereich eines Textes oder verlieren ihre Fähigkeit zum logischen Denken.
Anzeige
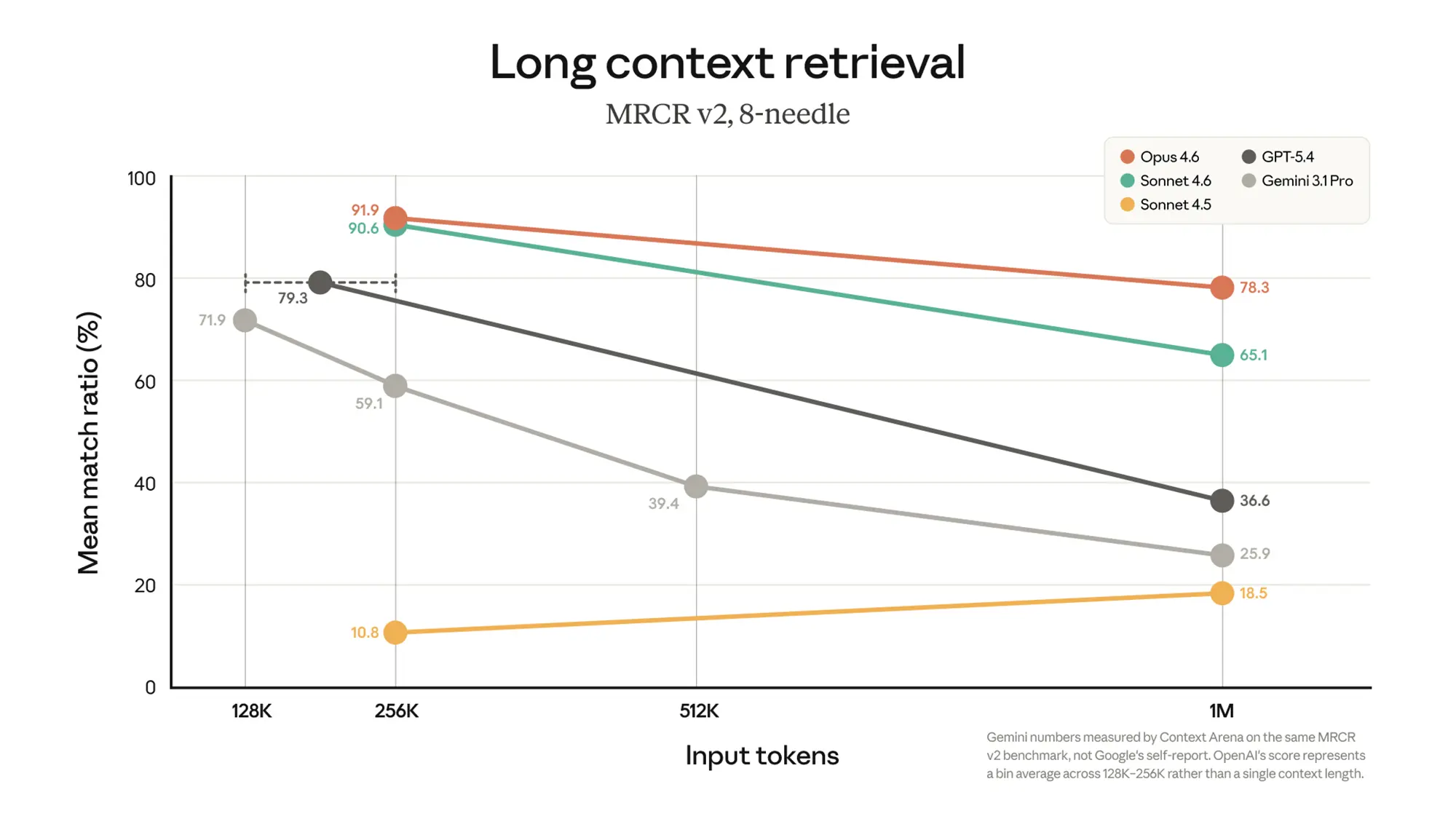
Hohe Präzision im Retrieval-Test
Beim Test zur exakten Informationsabfrage (Long Context Retrieval) erreicht das Top-Modell Opus 4.6 bei einem Kontext von 256.000 Token eine Trefferquote von knapp 92 Prozent. Reizt man das Fenster komplett auf eine Million Token aus, sinkt dieser Wert lediglich auf 78,3 Prozent. Das schnellere Modell Sonnet 4.6 hält bei voller Auslastung noch einen soliden Wert von 65,1 Prozent.
Die Auswertungen setzen diese Ergebnisse in direkten Kontrast zu den stärksten Konkurrenzmodellen auf dem Markt. Das Modell GPT-5.4 von OpenAI bricht bei einer Million Token stark auf 36,6 Prozent ein. Googles Gemini 3.1 Pro fällt bei der maximalen Auslastung sogar auf eine Genauigkeit von lediglich 25,9 Prozent ab.
Quelle: Anthropic
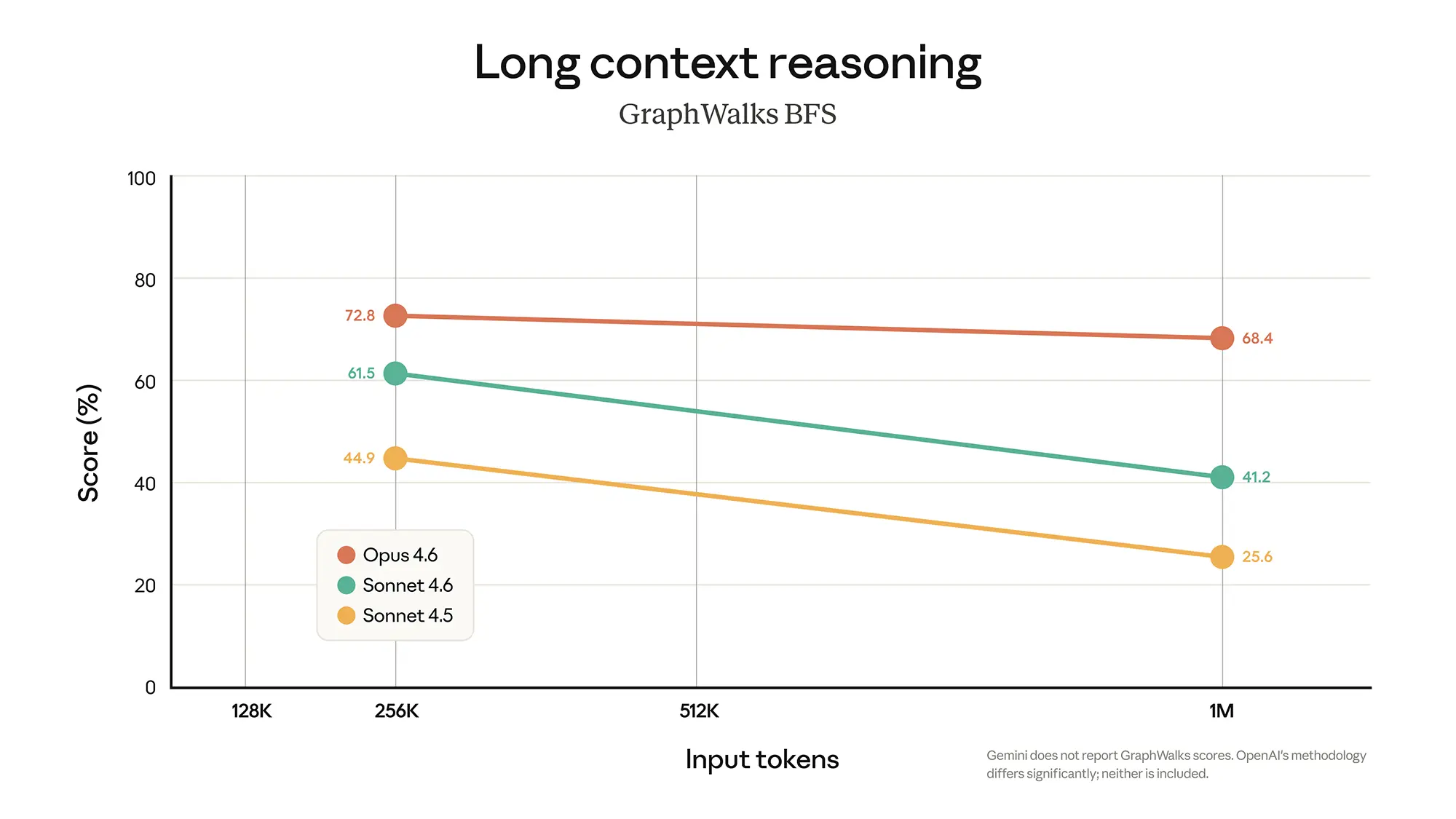
Spitzenwerte beim logischen Denken
Ein ähnliches Bild zeigt sich bei Aufgaben, die komplexes logisches Denken über den gesamten Textverlauf erfordern (Long Context Reasoning). Opus 4.6 verliert über die Distanz von einer Million Token nur wenige Prozentpunkte und sichert sich mit einem Score von 68,4 Prozent den klaren Spitzenplatz. Mit der offiziellen Freigabe positioniert sich Anthropic damit gezielt für professionelle Anwender, die sehr große Codebasen fehlerfrei bearbeiten oder umfangreiche Dokumentenarchive verlässlich auswerten müssen.