Nvidia reduziert den KI-Speicherbedarf mit neuer DMS-Technik deutlich
Die dynamische Kompression verkleinert den KV-Cache um den Faktor acht bei gleichbleibender Modellgenauigkeit.

Nvidia hat mit Dynamic Memory Sparsification (DMS) 2025 eine Methode vorgestellt, die den Speicherbedarf von Sprachmodellen bei der Textgenerierung deutlich senkt. Die Technik komprimiert den sogenannten KV-Cache um den Faktor acht, ohne die Genauigkeit der Berechnungen messbar zu verringern. Nun, 2026 ist das erste Modell nach diesem Prinzip mit Qwen3-8B-DMS-8x erschienen.
Anzeige
Der Flaschenhals im Arbeitsspeicher
Moderne KI-Modelle durchlaufen bei komplexen Anfragen einen ausführlichen Überlegungsprozess, bevor sie eine finale Antwort ausgeben. Jeder generierte Zwischenschritt belegt dabei Platz im sogenannten Key-Value-Cache (KV-Cache). Dieser Zwischenspeicher hält den bisherigen Kontext bereit, damit der Prozessor ihn nicht bei jedem neuen Wort komplett neu berechnen muss. Bei langen Überlegungsketten füllt sich der Videospeicher der Grafikkarten rasend schnell.
Das führt unweigerlich zu einem Hardware-Limit, da die Kapazität des Grafikspeichers die maximale Länge der Antwort begrenzt. Um längere Ausgaben zu ermöglichen, mussten Betreiber bisher teure Rechencluster mit mehr Arbeitsspeicher zusammenschalten. Eine reine Vergrößerung der Hardware skaliert jedoch schlecht und treibt die Betriebskosten in die Höhe.
Dynamisches Aussortieren von Daten
Der Lösungsansatz von Nvidia setzt exakt bei diesem Speicherproblem an. Das DMS-Verfahren analysiert während der Textausgabe kontinuierlich die Wichtigkeit der gespeicherten Token im Cache. Unwichtige oder redundante Informationen löscht der Algorithmus umgehend aus dem Speicher. Nur die für den logischen Zusammenhang zwingend notwendigen Daten verbleiben für weitere Berechnungen.
Im Gegensatz zu älteren Kompressionsmethoden arbeitet die Technik nicht mit starren Vorgaben. Laut dem veröffentlichten Forschungspapier passt sich der Löschvorgang in Echtzeit an die jeweilige Aufgabe an. Forscher der University of Edinburgh dokumentieren in einer Analyse, dass diese gezielte Verkleinerung des Speichers die Ausgabequalität sogar stabilisiert. Das Modell verliert bei sehr langen Texten seltener den Fokus durch überflüssige Kontextinformationen.
Anzeige
Erstes Praxis-Modell und Benchmarks: Qwen3-8B-DMS-8x
Um die Leistungsfähigkeit in der Praxis zu demonstrieren, hat Nvidia auf der Entwicklerplattform Hugging Face das Modell Qwen3-8B-DMS-8x veröffentlicht.
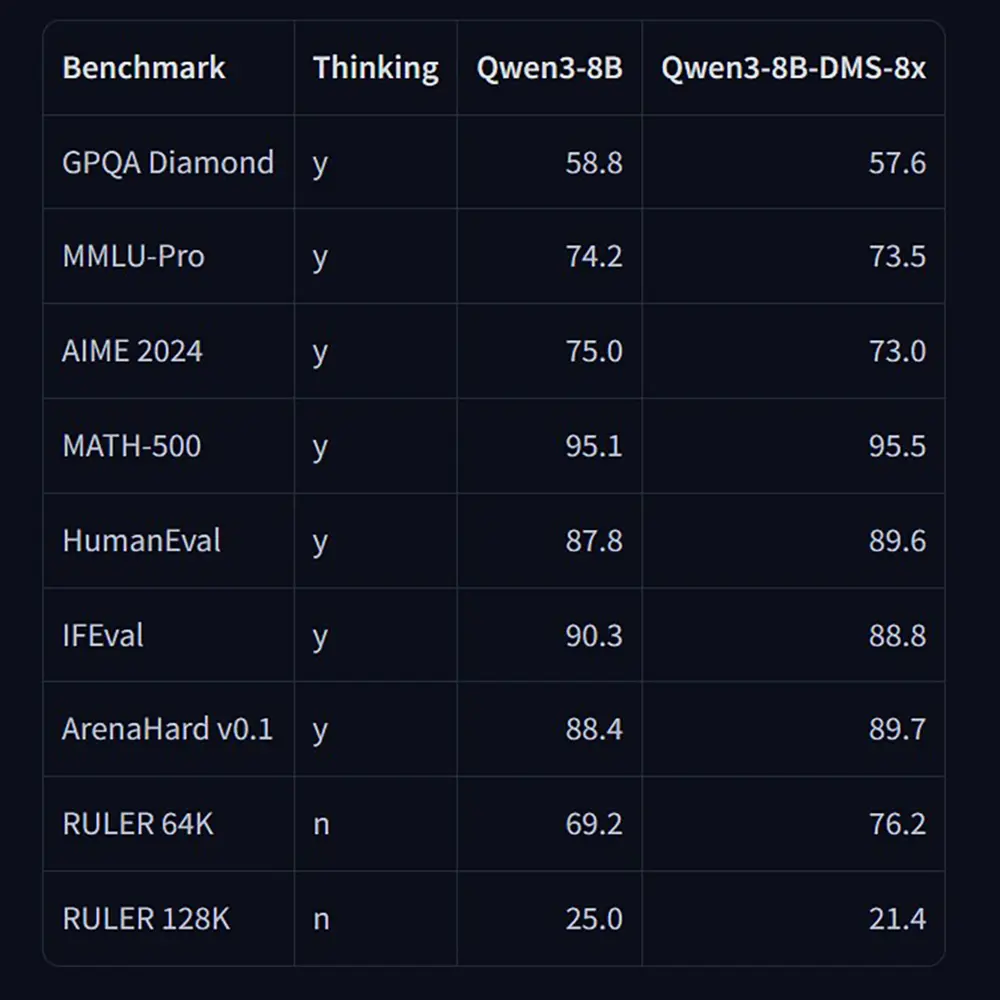
Ein direkter Benchmark-Vergleich zwischen dem Standardmodell (Qwen3-8B) und der neuen DMS-Variante zeigt eindrucksvoll, dass die achtfache Speicherkompression kaum zulasten der Ausgabequalität geht – in einigen Bereichen wird das Original sogar übertroffen:
- Logik, Mathematik & Programmieren ("Thinking"): Bei Aufgaben, die tiefgreifende Überlegungen erfordern, zeigt das DMS-Modell teils sogar bessere Ergebnisse als das Basismodell. So steigt der Score im Benchmark MATH-500 von 95.1 auf 95.5. Auch bei HumanEval (89.6 vs. 87.8) und ArenaHard v0.1 (89.7 vs. 88.4) schneidet das komprimierte Modell besser ab.
- Wissensabfragen & komplexe Tests: Bei Evaluierungen wie GPQA Diamond (57.6 vs. 58.8), MMLU-Pro (73.5 vs. 74.2), AIME 2024 (73.0 vs. 75.0) und IFEval (88.8 vs. 90.3) sind nur marginale, in der Praxis kaum spürbare Einbußen zu verzeichnen.
- Langer Kontext (ohne "Thinking"): Ein besonders interessantes Bild liefert der RULER-Benchmark für lange Kontexte. Bei einem Kontextfenster von 64K (RULER 64K) schlägt das DMS-Modell das Original deutlich mit 76.2 gegenüber 69.2 Punkten. Erst bei einem extremen Kontext von 128K (RULER 128K) fällt der Wert der DMS-Variante leicht auf 21.4 (Basis: 25.0) ab.
Diese ersten Werte belegen das enorme Potenzial von DMS, Hardwarekosten für komplexe KI-Anwendungen drastisch zu senken, ohne signifikante Kompromisse bei der Intelligenz der Modelle einzugehen.