
Google spaltet seine KI-Hardware in zwei Chips auf
Getrennte Recheneinheiten für Training und Inferenz sollen Verzögerungen minimieren. Neue Netzwerke skalieren dabei auf Millionen Komponenten.

Google teilt seine neue Chip-Generation für künstliche Intelligenz in zwei spezialisierte Hardware-Lösungen auf. Mit dem TPU 8t für das Training und dem TPU 8i für die Inferenz stehen Architekturen bereit, welche die hohe Rechenlast komplexer KI-Agenten bewältigen sollen.
Rechenleistung für das Modelltraining
Der TPU 8t fokussiert sich primär auf rechenintensive Trainingsprozesse. Ein einzelner Superpod fasst 9.600 Recheneinheiten zusammen und greift dabei auf zwei Petabyte an geteiltem Hochgeschwindigkeits-Speicher zurück. Hardware-seitig zielt das System auf eine maximale Auslastung ab, wofür unter anderem Datenspeicherzugriffe um den Faktor zehn beschleunigt ablaufen.
Zu den wichtigsten Leistungsdaten des TPU 8t gehören:
- Pod-Größe: 9.600 Chips
- Rechenleistung: 121 Exaflops (FP4)
- Bidirektionale Bandbreite: 19,2 Terabit pro Sekunde je Chip
Skalieren lässt sich der Verbund über das sogenannte Virgo-Netzwerk auf bis zu eine Million Einheiten in einem logischen Cluster. Fehlerhafte optische Verbindungen umgeht das System dabei automatisch in Echtzeit, was eine produktive Rechenzeit von kontinuierlich über 97 Prozent sicherstellt.

Quelle: Google
Schnelle Antworten in der Inferenz
Für die Ausführung fertiger KI-Modelle im Alltag kommt hingegen der TPU 8i zum Einsatz. Um Verzögerungen im Reasoning zu minimieren, verbaut der Konzern 288 Gigabyte High-Bandwidth Memory gepaart mit 384 Megabyte schnellem SRAM direkt auf dem Chip. Dies hält die aktiven Arbeitsdatensätze der Software vollständig im lokalen Zwischenspeicher.
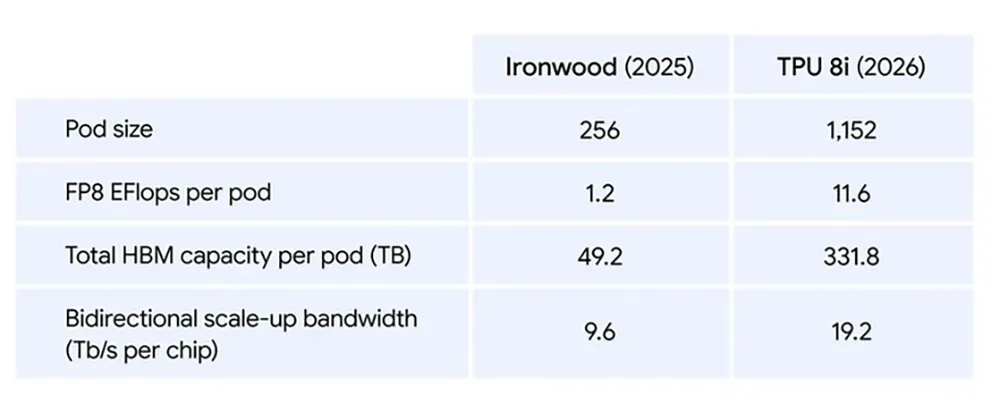
Die technischen Eckdaten des TPU 8i umfassen:
- Pod-Größe: 1.152 Chips
- Rechenleistung: 11,6 Exaflops (FP8)
- Speicher pro Pod: 331,8 Terabyte HBM
Zusätzlich halbiert die veränderte Boardfly-Architektur die maximalen Netzwerkwege zwischen den Knotenpunkten innerhalb des Rechenzentrums. Dadurch erzielen Unternehmen eine um 80 Prozent bessere Preis-Leistung bei der Inferenz im direkten Vergleich zur Vorjahresgeneration Ironwood.
Quelle: Google
Eigene Prozessoren und Infrastruktur
Erstmals arbeiten beide Chip-Varianten eng mit Googles hauseigenen Axion-Prozessoren auf ARM-Basis zusammen. Diese direkte Abstimmung auf Systemebene ermöglicht gepaart mit einer Flüssigkühlung der vierten Generation eine verdoppelte Leistung pro Watt. Entwickler nutzen für die Ansteuerung der Hardware weiterhin etablierte Frameworks wie JAX, PyTorch oder vLLM.
Die neuen Komponenten stehen Unternehmenskunden als Teil des Cloud-Angebots im weiteren Verlauf dieses Jahres zur Verfügung.